《运筹优化》专题
-
“constexpr if”vs“if”与优化-为什么需要“constexpr”?
C++1z将引入“constexpr if”-一个将根据条件删除其中一个分支的if。似乎合理有用。 但是,没有constexpr关键字就不行吗?我认为在编译过程中,编译器应该知道编译时是否知道条件。如果是的话,即使是最基本的优化级别也应该移除不必要的分支。 例如(参见godbolt:https://godbolt.org/g/ipy5y5): Godbolt explorer显示,即使带有-o0的
-
如何玩转缓冲区大小优化读写?
如何在标准C++/C++11(无POSIX函数)中优化std::ifstream和std::ofstream的读写速度?(1<-由于有几个问题,这些数字标识了不同点) 我不知道缓冲区的确切作用,所以你能确认一下吗: 用于读取:文件的大部分预加载在内存中(因此缓冲区大小定义了这大部分的大小)(2) 写入:数据写入内存,一旦缓冲区满了,数据就从内存传输到文件系统(3) 如何设置std::ifstrea
-
JDK 17 中字符串的 “” 操作数的优化
我们知道,在JDK8及以下版本中,使用加号表示连接的字符串将被编译到StringBuilder中进行性能优化,但在JDK9之后,它将使用<code>java.lang.invoke实现。StringConcatFactory#makeConcatWithConstants方法。 但是,在反编译< code>java.lang.Object之后,可以看到其< code>toString方法仍然是使用
-
列表中对的总和:记忆、设计优化
从一个整数列表和一个和值中,我必须按照外观的顺序返回前两个值,然后相加为和。任务的来源 我觉得最优化的扫单方式是: 等等。到目前为止我说的对吗? 然后,我使用了记忆法来削减出现两次以上的数字。 我编写的代码是实用的,但在更高级的测试中会超时。这里是: 如果您能帮助我理解我的错误和如何处理这类任务,我将不胜感激。干杯!
-
优化两个大型pyspark数据帧的连接
我有两个包含GB数据的大型pyspark数据框df1和df2。第一个数据框中的列是id1,col1。第二个数据框中的列是id2,col2。数据框的行数相等。id1和id2的所有值都是唯一的。id1的所有值也正好对应一个值id2。 因为。前几个条目与df1和df2区域相同,如下所示 DF1: df2: 所以我需要连接键 id1 和 id2 上的两个数据帧。df = df1.join(df2, df1
-
Linux上的Swift:如何指定编译器优化
stackoverflow上的几个线程(例如这一个)讨论了不同的优化级别(、、...)在编译Swift应用程序时。 然而,那些帖子与OSX上的开发有关。这些优化似乎可以直接通过Xcode或xcrun()设置。 我想知道在Linux(Ubuntu15.10)上直接使用Swift编译器时,如何切换不同的优化级别。目前,我只是通过调用来构建应用程序,如文档中所示,但我发现没有办法不更改优化级别。
-
Java:使用异步编程优化应用程序
所需代码如下:- 我在考虑以下方法:- > 不是通过POST调用dropwizard资源方法,而是直接从计划程序调用。 谢了。 编辑:我能想到两个瓶颈: 网页下载 将结果插入数据库(数据库位于另一个系统中) 似乎一次执行1个URL的处理
-
分支预测与分支目标预测优化
我的代码经常调用具有多个(不可预测的)分支的函数。当我分析时,我发现这是一个小瓶颈,大部分CPU时间用于条件JMP。 考虑以下两个函数,其中原始函数有多个显式分支。 这是一个新函数,我试图在其中删除导致瓶颈的分支。 然而,当我分析新代码时,性能只提高了大约20%,而且调用本身(对mem_funcs数组中的一个func)花费了很长时间。 第二个变量仅仅是一个更隐含的条件吗,因为CPU仍然无法预测将要
-
优化DOC、XLS文件中的元数据写入
我正在做一个程序,只修改文件Doc,xls,ppt和Vsd中的元数据(标准和自定义),程序可以正常工作,但我想知道是否有办法在不将整个文件加载到内存中的情况下执行此操作: POIFSFileSystem=new POIFSFileSystem(new FileInputStream("file.xls")) NPOIFSFileSystem方法速度更快,占用的内存更少,但它是只读的。 我使用的是A
-
编译器会将除法优化为乘法吗
根据这个问题,浮点除法与浮点乘法。由于某些原因,除法比乘法慢。 如果可能的话,编译器通常会用乘法代替除法吗? 例如: 会是: 如果它被认为是编译器可靠的问题,我使用的是VS2013默认编译器。但是,如果我得到一个通用的答案就好了(这种优化的理论有效性)
-
哈斯克尔:GHC会对此进行优化吗?
GHC能否简化id=(\(a,b)- 更复杂的情况呢: GHC将简化映射到映射中? 我试图使用简单的beta缩减,但由于糟糕的模式匹配,这些术语看起来是不可缩减的。 因此,我很好奇GHC的优化技术如何处理这个问题。
-
JavaScript性能优化之V8垃圾回收策略
前言 本篇文章主要是介绍,JavaScript性能优化之V8垃圾回收策略的相关内容 V8垃圾回收策略 1.采用分代回收的思想 2.内存分为新生代和老生代 3.针对不同对象采用不同的算法 V8垃圾回收策略演示图 在上图所示中,内存分为两部分,一个是新生代一个是老生代,两个区域采用不同的GC算法 V8中常用的GC算法 1.分代回收 2.空间复制 3.标记清除 4.标记整理 5.标记增
-
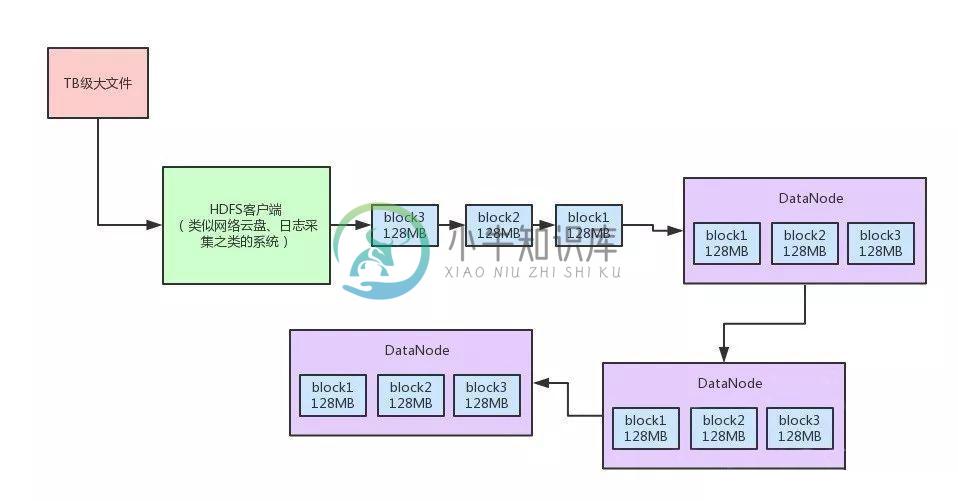 Hadoop的TB级大文件上传优化实践!
Hadoop的TB级大文件上传优化实践!主要内容:一、写在前面,二、原始的文件上传方案,三、HDFS对大文件上传的性能优化,1. Chunk缓冲机制,2. Packet数据包机制,3. 内存队列异步发送机制,四、总结一、写在前面 上一篇文章,我们聊了一下Hadoop中的NameNode里的edits log写机制。 主要分析了edits log写入磁盘和网络的时候,是如何通过分段加锁以及双缓冲的机制,大幅度提升了多线程并发写edits log的吞吐量,从而支持高并发的访问。 如果没看那篇文章的同学,可以回看一下:《每秒上千次高并发访问
-
进一步探索分类 - 优化近邻算法
有一种分类器叫“机械记忆分类器(Rote Classifer)”,它会将数据集完整地保存下来,并用来判断某条记录是否存在于数据集中。 所以,如果我们只对数据集中的数据进行分类,准确率将是100%。而在现实应用中,这种分类器并不可用,因为我们需要判定某条新的记录属于哪个分类。 你可以认为我们上一章中构建的分类器是机械记忆分类器的一种扩展,只是我们不要求新的记录完全对应到数据集中的某一条记录,只要距离
-
第11章 新特性 - Java 代码性能优化
35 个 Java 代码性能优化总结 代码优化,一个很重要的课题。可能有些人觉得没用,一些细小的地方有什么好修改的,改与不改对于代码的运行效率有什么影响呢?这个问题我是这么考虑 的,就像大海里面的鲸鱼一样,它吃一条小虾米有用吗? 前言 代码优化,一个很重要的课题。可能有些人觉得没用,一些细小的地方有什么好修改的,改与不改对于代码的运行效率有什么影响呢?这个问题我是这么考虑 的,就像大海里面的鲸鱼一