《运筹优化》专题
-
 记一次vue-webpack项目优化实践详解
记一次vue-webpack项目优化实践详解本文向大家介绍记一次vue-webpack项目优化实践详解,包括了记一次vue-webpack项目优化实践详解的使用技巧和注意事项,需要的朋友参考一下 项目现状 项目是一个数据监测平台,引入了ehcart和three.js 负责项目的数据可视化;打包后,体积高达2.1M,这个体积相比于我的项目规模来说就显得稍有笨重了 使用webpack-bundle-analyzer分析了一下各个文件所占用的比例
-
 JVM:早期(编译期)优化的深入理解
JVM:早期(编译期)优化的深入理解本文向大家介绍JVM:早期(编译期)优化的深入理解,包括了JVM:早期(编译期)优化的深入理解的使用技巧和注意事项,需要的朋友参考一下 早期(编译期)优化 JVM的编译器可以分为三个编译器: 前端编译器:把*.java转变为*.class的过程。如Sun的Javac、Eclipse JDT中的增量式编译器(ECJ) JIT编译器:把字节码转变为机器码的过程,如HotSpot VM的C1、C2编译器
-
mysql优化limit查询语句的5个方法
本文向大家介绍mysql优化limit查询语句的5个方法,包括了mysql优化limit查询语句的5个方法的使用技巧和注意事项,需要的朋友参考一下 mysql的分页比较简单,只需要limit offset,length就可以获取数据了,但是当offset和length比较大的时候,mysql明显性能下降 1.子查询优化法 先找出第一条数据,然后大于等于这条数据的id就是要获取的数据 缺点:数据必须
-
创建小型高质量PDF嵌入优化PNG?
我正在尝试创建一个小的PDF文件,嵌入一个优化的PNG图像显示为3页PDF的页眉和页脚(相同的图像必须在PDF中显示6倍) 我优化的PNG映像只有2.3KB。看起来很锋利。 我还尝试制作一个测试页面,并使用wkhtml2pdf,但它做了同样的事情。添加低质量标志没有任何区别。 PDF规范建议支持PNG? 从略读PDF规范,它看起来像是支持PNG图像。
-
硬币兑换的空间优化解决方案
给定一个值N,如果我们想换N美分,并且我们有无限量的S={S1,S2,…,Sm}值的硬币,我们可以用多少种方式来换?硬币的顺序无关紧要。 例如,对于N=4和S={1,2,3},有四种解:{1,1,1,1},{1,1,2},{2,2},{1,3}。所以输出应该是4。对于N=10和S={2,5,3,6},有五个解:{2,2,2,2},{2,2,3,3},{2,2,6},{2,3,5}和{5,5}。所以
-
具有自定义函数的Gekko优化约束
我目前正试图用Gekko的分支来解决一个混合整数非线性问题 以下是我迄今为止的尝试:
-
即时编译器如何优化Java并行流?
不久前有人问了一个有趣的问题: 我决定证明使用Java8流API(确切地说是并行流)是可能的。以下是我的代码,它在非常罕见的情况下工作: 然后我想,也许是因为潜在的JIT编译器优化?因此,我尝试使用以下VM选项运行代码: 我禁用了JIT,成功案例的数量显著增加! 即时编译器如何优化并行流,以便优化可能会影响上述代码的执行?
-
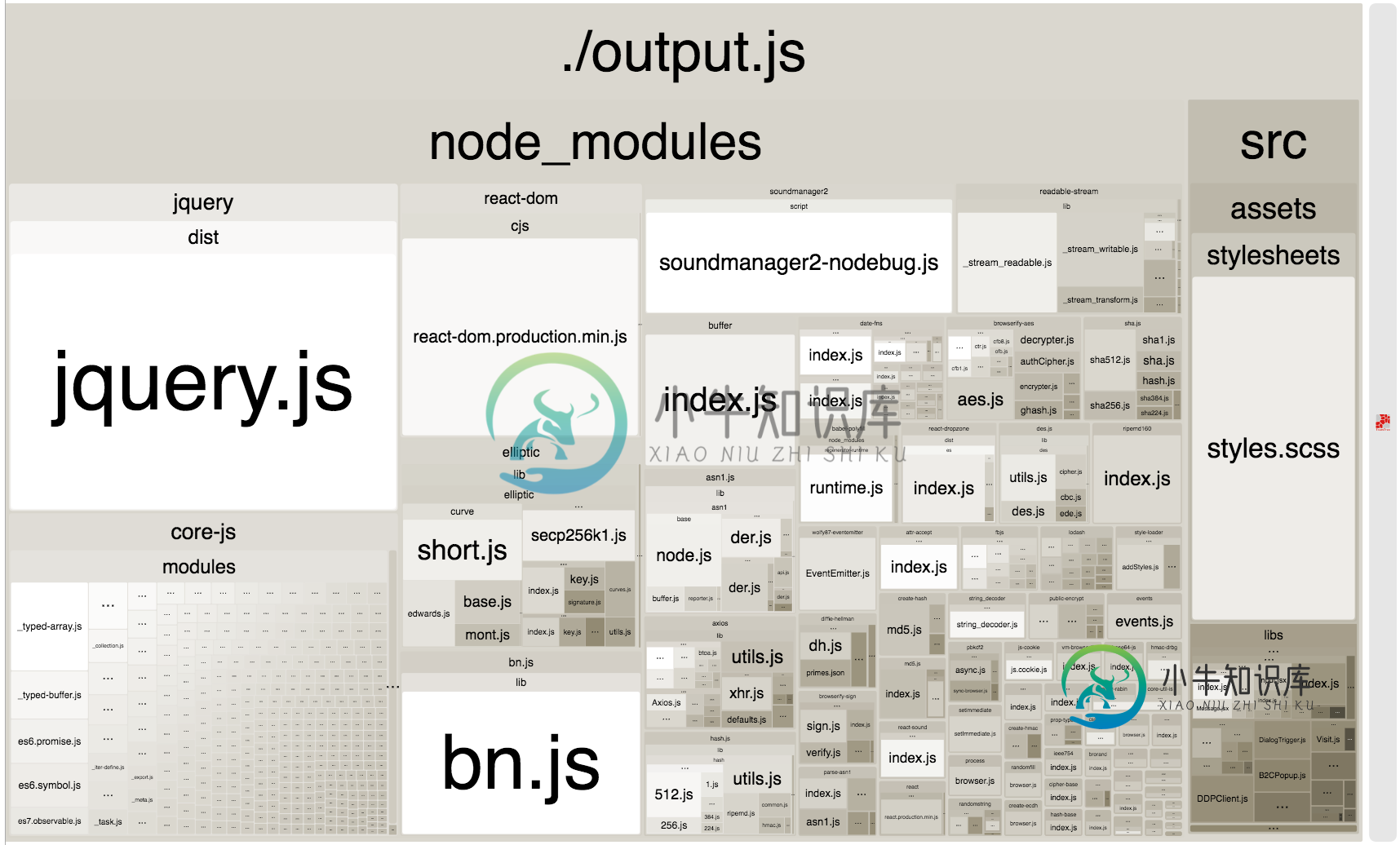 如何进一步优化webpack捆绑包大小
如何进一步优化webpack捆绑包大小所以我能够将我的捆绑包大小从13mb减少到681 mb 我做了一些优化,比如正确的生产配置,优化库,比如lodash,用date fns替换momentjs。 现在,大多数软件包都不超过1mb,并且大多数都是由npm安装的依赖项。 在这里使用webpack-bundle-Analyzer就是我的bundle现在的样子 你们觉得我能做些什么来减少包裹的大小吗?也许删除jquery并转到vanilla
-
void返回型函数的尾部调用优化
尾部调用优化对返回void的函数的递归调用有效吗?例如,我有一个函数,void fun() 在这里,编译器不会知道,调用fun()是最后一条语句。那么尾部调用优化是否只针对返回某些值的函数?
-
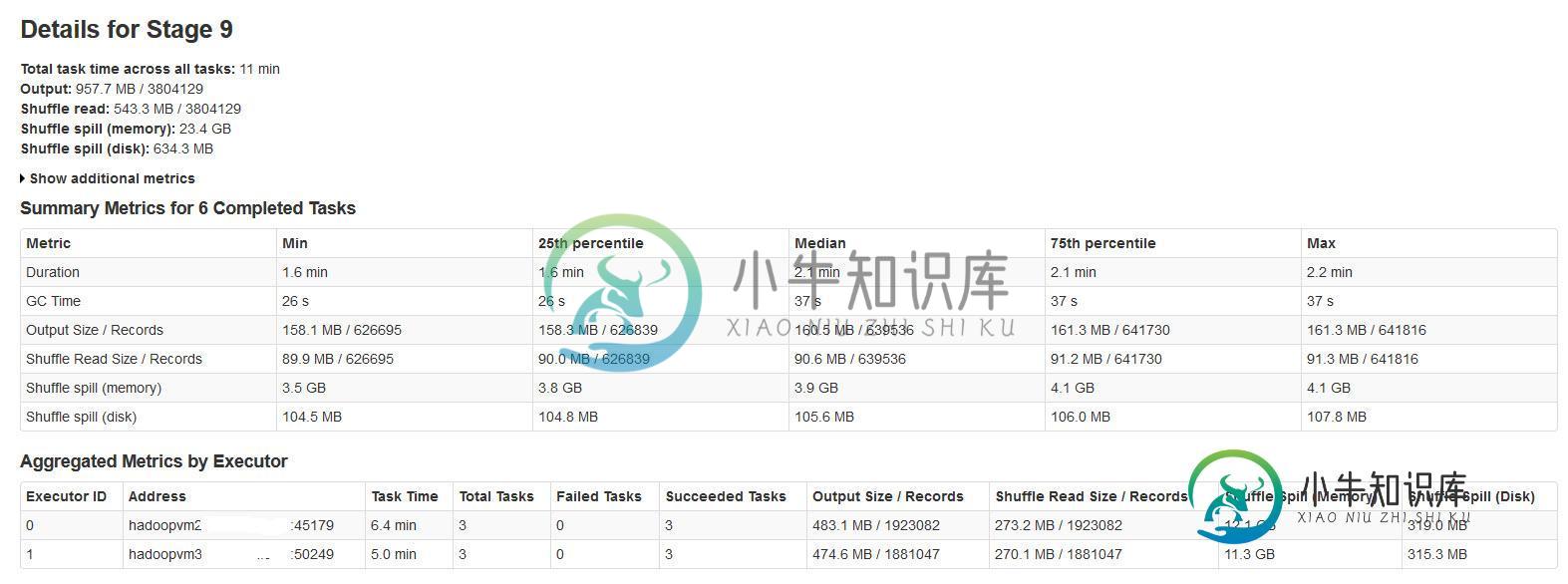 如何优化Apache Spark应用中的shuffle溢出
如何优化Apache Spark应用中的shuffle溢出我正在运行一个有2个工作者的Spark流式应用程序。应用程序具有联接和联合操作。 所有批处理都成功完成,但注意到shuffle溢出度量与输入数据大小或输出数据大小不一致(溢出内存超过20次)。 对此进行研究后发现 注意到这个溢出内存的大小对于大的输入数据是难以置信的大。 我的问题是: 这种溢出对性能有很大影响吗? 有没有什么火花属性可以减少/控制这种巨大的溢出?
-
这种易失性访问可以优化掉吗?
来自ISO/IEC 9899:201x第5.1.2.3节程序执行: 2访问一个易失性对象,修改一个对象,修改一个文件,或者调用一个做那些操作中任何一个的函数,都是副作用,都是执行环境状态的改变。表达式的计算通常包括值计算和副作用的启动。用于lvalue表达式的值计算包括确定指定对象的标识。 因此,访问(读\写)volatile被称为副作用。让我们继续: 6对符合要求的实施的最低要求是: > 对易失
-
用电晕限制优化活动座位分配
问题:给定一组注册组,每个注册组的人数不同(1-7),以及一组座位组(不可变,至少相距2m),座位数不同于1-4个,我想找到人组对座位组的最佳分配: 人组可以分为几个座位组(但最好不是) 不同的人组不能共享座位组 (可选)分配应使“浪费”的座位数最小化,即使空座位组中的座位数最大化 (理想情况下,它应该在Google Apps脚本中运行,因此内存和计算复杂性应该尽可能小) 第一次尝试:我对决策问题
-
工作人数可变的任务优化调度
我有一些任务的持续时间是已知的整数长度。任务之间也有依赖关系。我也有任意数量的员工可以安排这些任务。 我想为他们找到一个最佳的时间表,首先我要最小化所有任务执行的总长度,其次我想在一个之前运行过大多数依赖项的工作人员身上安排任务,第三我想最小化所需的工作人员数量。 因此,如果任务具有依赖项A、B和C,并且worker1运行A和B,worker2运行C,那么我更希望将新任务添加到worker1。 我
-
在基准测试时防止编译器优化
我最近遇到了这个精彩的cpp2015演讲cppCon 2015:钱德勒·卡鲁斯“调整C:基准、CPU和编译器!哦,天哪!” 提到的防止编译器优化代码的技术之一是使用以下函数。 我在努力理解这一点。问题如下。 1)逃避比重击有什么好处? 2) 从上面的例子来看,clobber()似乎可以防止前面的语句(push_back)以这种方式进行优化。如果是这样,为什么下面的代码片段不正确? 如果这还不够混乱
-
什么是复制删除和返回值优化?
什么是拷贝删减?什么是(命名的)返回值优化?它们暗示了什么? 在什么情况下它们会发生?限制是什么? 如果您被引用到此问题,您可能正在查找介绍。 有关技术概述,请参阅标准参考。 请参阅此处的常见情况。