《算法面经》专题
-
 分享一波攒了整个秋招的NLP算法岗面经
分享一波攒了整个秋招的NLP算法岗面经投的岗位比较杂,主要是NLP,也包括一些多模态、大模型、推荐相关的岗位,最终拿到了腾讯、顺丰、平安金服和迪子的offer,华子、京东和百度的池子。 总结一下,首先算法的问题会问得非常杂,主要根据你的项目经历,面试官一般会从你的经历里挑和他们工作内容比较相关的点提问,然后不断扩展;反而八股文问的不多,一般是一些中小厂喜欢问八股。 最后是自己的一点见解,对于非研究性质的算法岗位,论文的权重并没有很大(
-
 蔚来秋招提前批规控算法岗面经(已意向)
蔚来秋招提前批规控算法岗面经(已意向)自身情况:985硕,无文章,一段大厂机器人方向实习。硕士期间方向是机器人运动规划,想转行自动驾驶规控。 时间线:7.15投简历(提前批),7.22笔试,7.28一面,8.4二面,8.11三面,8.16四面,8.24hr面,9.6拉群沟通(算是OC)9.13意向。 一面7.28(45min): 自我介绍 讲项目,他全程没说话,听我介绍了10分钟后说:我不懂机械臂规划这一块,谢谢你的分享,学习到了。
-
 VIVO深度学习算法研发工程师Camera方向面经
VIVO深度学习算法研发工程师Camera方向面经9.20下午技术一面 1. 问实习 15mins 2. 问项目问论文 15mins 3. 最后说没有时间了,然后问我会不会C++,我说本科学过。 (无手撕) 访问: 1. 后续还有几轮面试?答:还有一轮或者两轮,也有可能后续直接HR面试 9.21 下午收到HR面通知 9.22 HR面试 攒人品,许愿offer #vivo##校招##秋招#
-
 预测算法实习面经for自动驾驶(暑期实习)
预测算法实习面经for自动驾驶(暑期实习)秋招已经慢慢走过了一半,终于有时间来写一下我这半年的总结,先来讲下我的实习吧,先放面经,下一篇再来讲下在智加的实习生活。 岗位:算法实习-预测方向 本人本硕都是机械工程专业,目前在上交智能汽车研究所读研,研二下学期是可以外出实习的,大概在3月份左右开始看暑期实习的机会,本来没有太了解智加,也是机缘巧合在我实验室同学的推荐之下,我和他一起投递了智加的暑期实习。很巧的是我们两后来都来智加实习了。 在官
-
 字节 实习算法工程师-业务中台,一面凉经
字节 实习算法工程师-业务中台,一面凉经这次又没准备好,或者说没准备就来面试了,真的很难受。 面试前就是准备好挨揍的感觉,非常难受,明知道自己没准备,还非要参加这个面试找虐。 我再也不想体验这种感觉了,下次一定把简历背熟,题刷好,基础知识掌握牢再投简历!!绝不裸面,裸面就是自己找不痛快。 -----以上为面试前的感受---------------- ddd面试8分钟就结束了 面试官还是挺和蔼的,看我以前的经历主要做开发的,简历上只有北航
-
 轻舟智航-主动安全算法一面(大概率凉经)
轻舟智航-主动安全算法一面(大概率凉经)8.16一面 让我着重介绍大疆车载的主动安全系统工程实习经历,先聊了这方面比较多,但我更多是做se的工作,并没有开发过这方面算法,只对这些功能流程比较了解,就没长时间聊下去。 之后是介绍简历的硕士项目,这次运气不好,对我简历里无人机任务决策规划算法项目不太特别感兴趣(哎,之前面试过的公司都比较感兴趣,都聊了好久),面试官不让我太详细介绍,马上就是噩梦开始,问一堆背书八股知识,吐了。 1. hybr
-
 快手秋招面经-视频策略模型算法工程师
快手秋招面经-视频策略模型算法工程师自我介绍 自己从简历上选一个与数据分析、建模有关的项目讲 (第一个项目:) 刚刚说到这是一个比赛,是kaggle的比赛吗 为什么选用XGBoost(隐含考察点:模型的使用场景) 提到样本倾斜的问题,应该怎么解决样本不均匀 (第二个项目:) 是直接用数据集里的特征进行建模(应该是想问有没有特征筛选) 有哪些特征筛选的方法 (实习)两份实习分别做什么 (知识点)有没有学过因果推断的课程或做过相关项目
-
 迈瑞医疗 信号处理算法岗 暑假实习 面经
迈瑞医疗 信号处理算法岗 暑假实习 面经0offer选手面经发出来攒攒人品吧(悲 #无实习如何秋招上岸# ) 一面:6/1 1.自我介绍 2.介绍项目,方向可能比较对口,一直挖,哭死 3.是否是独生子女 4.哪里人 5.未来定居打算 6.能实习多久 7.职业规划走技术还是走项目管理 8.还投了哪些公司 反问: 有无暑假转正,回答没有,秋招得重新投 第二天hr打电话约二面,时间在第三天,二面和一面差不多,但项目没挖那么多,更多是问其他问题
-
Android Flood-fill算法
问题内容: 有谁知道迭代和高效的洪水填充算法? 还是有没有办法实现没有堆栈溢出错误的递归算法? 尝试了使用堆栈的@ Flood填充, 但是我找不到在白色和黑色图像上工作的方法。 问题答案: 这个算法对我很好。
-
SMO算法实现?
本文向大家介绍SMO算法实现?相关面试题,主要包含被问及SMO算法实现?时的应答技巧和注意事项,需要的朋友参考一下 选择原凸二次规划的两个变量,其他变量保持不变,根据这两个变量构建一个新的二次规划问题,这样将原问题划分为更小的子问题可以大大加快计算速度,而选择变量的方式是: 其中一个是严重违反KKT条件的一个变量 另一个变量是根据自由约束确定的
-
canopy算法原理?
本文向大家介绍canopy算法原理?相关面试题,主要包含被问及canopy算法原理?时的应答技巧和注意事项,需要的朋友参考一下 根据两个阈值来划分数据,以随机的一个数据点作为canopy中心。 计算其他数据点到其的距离,划入t1、t2中,划入t2的从数据集中删除,划入t1的其他数据点继续计算,直至数据集中无数据。
-
ALS算法原理?
本文向大家介绍ALS算法原理?相关面试题,主要包含被问及ALS算法原理?时的应答技巧和注意事项,需要的朋友参考一下 答:对于user-product-rating数据,als会建立一个稀疏的评分矩阵,其目的就是通过一定的规则填满这个稀疏矩阵。 als会对稀疏矩阵进行分解,分为用户-特征值,产品-特征值,一个用户对一个产品的评分可以由这两个矩阵相乘得到。 通过固定一个未知的特征值,计算另外一个特征值
-
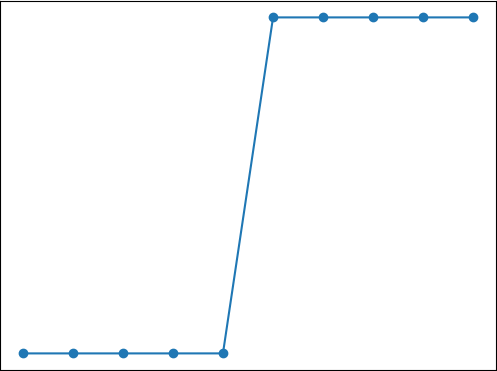 Logistic回归算法
Logistic回归算法主要内容:什么是分类问题?,Logistic回归算法我们知道有监督学习分为“回归问题”和“分类问题”,前面我们已经认识了什么是“回归问题”,从本节开始我们将讲解“分类问题”的相关算法。在介绍具体的算法前,我们先聊聊到底什么是分类问题。 什么是分类问题? 其实想要理解“分类”问题非常的简单,我们不妨拿最简单的“垃圾分类处理”的过程来认识一下这个词。现在考虑以下场景: 小明拎着两个垃圾袋出门倒垃圾,等走到垃圾回收站的时候,小明发现摆放着两个垃圾桶,上面
-
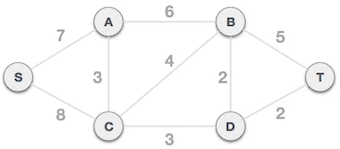 普里姆算法
普里姆算法主要内容:普里姆算法的具体实现了解了什么是 最小生成树后,本节为您讲解如何用普里姆(prim)算法查找连通网(带权的连通图)中的最小生成树。 普里姆算法查找最小生成树的过程,采用了贪心算法的思想。对于包含 N 个顶点的连通网,普里姆算法每次从连通网中找出一个权值最小的边,这样的操作重复 N-1 次,由 N-1 条权值最小的边组成的生成树就是最小生成树。 那么,如何找出 N-1 条权值最小的边呢?普里姆算法的实现思路是: 将连通
-
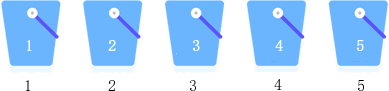 桶排序算法
桶排序算法主要内容:桶排序算法的实现思路,桶排序算法的具体实现桶排序(又称箱排序)是一种基于分治思想、效率很高的排序算法,理想情况下对应的时间复杂度为 O(n)。 接下来,我们系统地学习一下桶排序算法。 桶排序算法的实现思路 假设一种场景,对 {5, 2, 1, 4, 3} 进行升序排序,桶排序算法的实现思路是: 准备 5 个桶,从 1~5 对它们进行编号; 将待排序序列的各个元素放置到相同编号的桶中; 从 1 号桶开始,依次获取桶中放置的元素,得到的就是一