《索引》专题
-
Lucene:如何在几个独立的索引集上执行搜索并合并结果?
现在我有了几个Lucene索引集(我称之为shards),它对不同的文档集进行索引。它们是独立的,这意味着我可以在它们中的每一个上执行搜索,而不必阅读其他的。然后我得到一个查询请求。我想在每个索引集上搜索它,并结合结果形成最终的顶级文档。 我知道,在给文档打分时,Lucene需要知道每个术语的 ,不同的索引集会给同一个术语不同的 (因为不同的索引集持有不同的文档集)。因此,根据我的理解,我不能直接
-
403使用AWS SDK从AWS弹性搜索获取索引时出现禁止错误
我正在使用AWS SDK连接到弹性搜索。我正在浏览https://docs.aws.amazon.com/elasticsearch-service/latest/developerguide/es-indexing.html 本主题中的其他问题更像是权限问题或在给ElasticSearch写信时出现的问题。对我来说,写作很好,只有阅读给了我错误 POST方法工作得很好,它正在添加索引。我正在以相
-
螺母爬网失败的 Solr 索引,报告“索引器: java.io.IO异常: 作业失败!
我在ec2实例上集成了Nutch1.13和Solr 6.5.1。我确实复制了模式。使用下面的cp命令将xml转换为Solr。我给localhost发了兴奋剂。宿主在nutch站点。nutch_home/conf文件夹中的xml。 cp /usr/local/apache-nutch-1.13/conf/schema.xml /usr/local/apache-nutch-1.13/solr-6.5
-
WebDriverWait +搜索项目
问题内容: 创建激活码后,需要1至60秒的时间将代码上传到系统中。因此,在创建新代码之后,我想使用WebDriverWait 60秒钟来确保,并且在此时间段内每3秒钟我要单击“搜索按钮”。有什么办法吗? 问题答案: 附带“免费” 。 您可以在创建时设置一个值,以告诉它应该多久尝试运行一次代码(单击搜索按钮): http://selenium.googlecode.com/git/docs/api/
-
ElasticSearch全文搜索
问题内容: 我尝试在elasticsearchJava API上使用正则表达式运行全文搜索。我的过滤器是这样的: 但是它只与一个单词匹配,而没有短语匹配。我的意思是,例如: 如果soruce中有一个字符串,例如:“ ”,而当我的文本字符串如下:“ ”,“ ”,“ ” …时,它就起作用了。 但是,当我的realTimeTextIn字符串为“ ”时,全文搜索将不起作用。我搜索的单词不能超过一个。 我在
-
ElasticSearch搜索性能
问题内容: 我们有两个节点的集群(私有云中的VM,64GB的RAM,每个节点8个核心CPU,CentOS),几个小索引(约100万个文档)和一个大索引,约有2.2亿个文档(2个分片,170GB)的空间)。每个盒上分配了24GB的内存用于elasticsearch。 文件结构: 运行以下查询大约需要1-2秒: 我们是在此时达到硬件极限,还是有办法优化查询或数据结构以提高性能? 提前致谢! 问题答案:
-
ElasticSearch-搜索人名
问题内容: 我有一个很大的名字数据库,主要来自苏格兰。我们目前正在生产一个原型,以替换执行搜索的现有软件。这仍在生产中,我们的目标是使我们的结果尽可能接近同一搜索的当前结果。 我希望有人可以帮助我,我正在对Elastic Search进行搜索,查询是“ Michael Heaney”,我得到了一些疯狂的结果。当前搜索返回两个主要的姓,分别是“ Heaney”和“ Heavey”,都以“ Micha
-
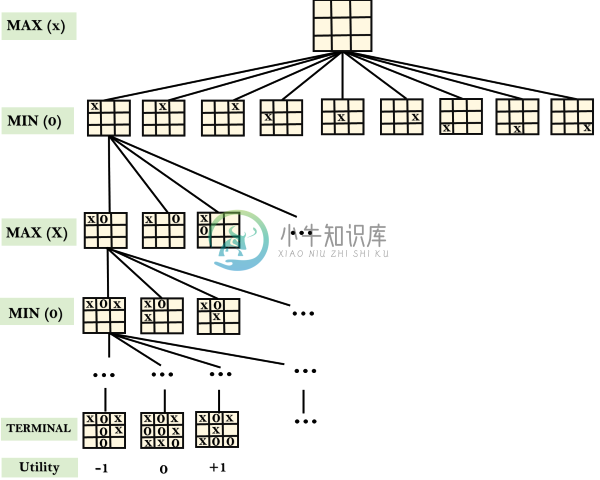 对抗性搜索
对抗性搜索主要内容:AI中的游戏类型,游戏树对抗性搜索是一种搜索,在此检查当尝试在世界范围内进行计划而其他代理正在计划针对 时出现的问题。 在之前的主题中,我们研究仅与单个代理相关联的搜索策略,该代理旨在找到通常以一系列动作的形式表达的解决方案。 但是,可能存在多个代理在同一搜索空间中搜索解决方案的情况,这种情况通常发生在游戏中。 具有多个代理的环境被称为多代理环境,其中每个代理是其他代理的对手并且彼此竞争。每个代理都需要考虑其他代理的操作
-
 二分搜索树
二分搜索树主要内容:src/runoob/binary/BinarySearch.java 文件代码:一、概念及其介绍 二分搜索树(英语:Binary Search Tree),也称为 二叉查找树 、二叉搜索树 、有序二叉树或排序二叉树。满足以下几个条件: 若它的左子树不为空,左子树上所有节点的值都小于它的根节点。 若它的右子树不为空,右子树上所有的节点的值都大于它的根节点。 它的左、右子树也都是二分搜索树。 如下图所示: 二、适用说明 二分搜索树有着高效的插入、删除、查询操作。 平均时间的时间复
-
MongoDB全文检索
主要内容:启用全文检索,创建全文索引,使用全文索引,删除全文索引从 2.4 版本开始,MongoDB 开始支持全文检索功能,全文检索就是对文本中的每个词建立索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户,整个过程类似于通过字典中的检索字表查字的过程。 目前,MongoDB 支持大约 15 种语言的全文索引,例如 danish、dutch、english、finnish、french、germ
-
HeapDumpOnOutOfMemoryError弹性搜索
当我执行ps-aef grep elasticsearch HeapDumpOnOutOfMemoryError时看到了这一点 501 373 47 1 0 2:29pm ttys004 0:04.14/usr/bin/Java-xms4g-xmx4g-xss256k-djava.awt.headless=true-xx:+useparnewgc-xx:+useparnewgc-xx:+usepa
-
从SparkSession检索SparkContext
我正在运行spark批处理作业,并使用,因为我需要在每个组件中处理许多spark sql功能。在父组件中初始化,并作为传递给子组件。 在我的一个子组件中,我想在我的中再添加两个配置。因此,我需要从中检索,停止它并用附加配置重新创建。要做到这一点,我如何从Spark会话检索SparkContext?
-
Solr检索数据
在本章中,我们将讨论如何使用Java Client API检索数据。假设有一个名为sample.csv的.csv文档,其中包含以下内容。 可以使用命令在核心-下对此数据编制索引。 以下是向Apache Solr索引添加文档的Java程序代码。将此代码保存在的文件中。 通过在终端中执行以下命令编译上述代码 - 执行上述命令后,将得到以下输出。
-
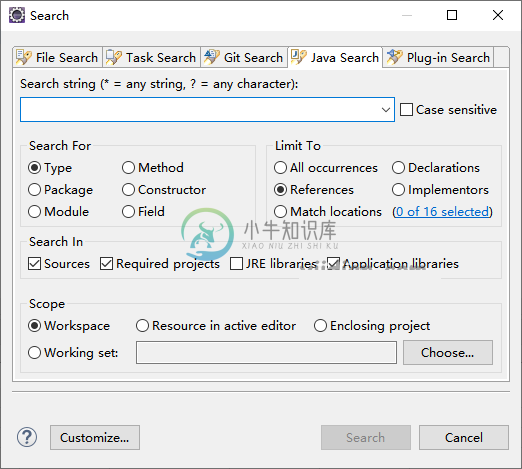 Eclipse 搜索菜单
Eclipse 搜索菜单主要内容:Eclipse 搜索菜单Eclipse 搜索菜单 Eclipse 搜索对话框允许您在整个工作区、一组项目、特定项目或包资源管理器视图中选择的文件夹中搜索包含文字或字符模式的文件。 可以通过以下方式调用搜索对话框 : 单击“Search”菜单并选择“Search”或“File”或“Java”。 单击 Ctrl + H。 “File Search”页面允许您搜索任何类型的文件,但“Java Search”页面仅关注 Java
-
4.11.探索迷宫
在这一节中,我们将讨论一个与扩展机器人世界相关的问题:你如何找到自己的迷宫? 如果你在你的宿舍有一个扫地机器人(不是所有的大学生?)你希望你可以使用你在本节中学到的知识重新给它编程。 我们要解决的问题是帮助我们的乌龟在虚拟迷宫中找到出路。 迷宫问题的根源与希腊的神话有关,传说忒修斯被送入迷宫中以杀死人身牛头怪。忒修斯用了一卷线帮助他找到回去的退路,当他完成杀死野兽的任务。在我们的问题中,我们将假设