《全文检索》专题
-
用XPath表达式从HTML span元素中提取全文
我有一个HTML树,看起来如下所示: 我试图用以下XPath表达式从span中提取所有文本: 然而,这种方法只返回第一个文本行,直到中断?问题是:为了提取HTML span标记的全文内容,我将如何以正确的方式处理这个问题?我将非常感谢任何帮助,并预先感谢您的支持。
-
输入流。available()和从oracle完全读取文件注释
根据: 请注意,虽然InputStream的一些实现将返回流中的总字节数,但许多实现不会返回。使用此方法的返回值来分配一个缓冲区以保存此流中的所有数据永远都是不正确的。 来自: http://docs.oracle.com/javase/7/docs/api/java/io/InputStream.html#available() 还有这张便条 http://docs.oracle.com/jav
-
如何在php中回显.html文件的全部内容?
问题内容: 有什么办法可以在php中回显.html文件的全部内容? 例如,我有一些sample.html文件,我想回显该文件名,因此应显示其内容。 问题答案: 您应该使用: 这将读取文件,并通过一个命令将其发送到浏览器。这基本上与以下内容相同: 否则可能会导致大型文件崩溃,而事实并非如此。
-
 易语言删除文本中的全部空格功能
易语言删除文本中的全部空格功能本文向大家介绍易语言删除文本中的全部空格功能,包括了易语言删除文本中的全部空格功能的使用技巧和注意事项,需要的朋友参考一下 删全部空命令 英文命令:TrimAll 操作系统支持:Windows、Linux 所属类别:文本操作 返回一个文本,其中包含被删除了所有全角或半角空格的指定文本。 语法: 文本型 删全部空 (欲删除空格的文本) 例程 说明 通过“删全部空”命令将一段文本中的空格全部
-
 深入理解Vue官方文档梳理之全局API
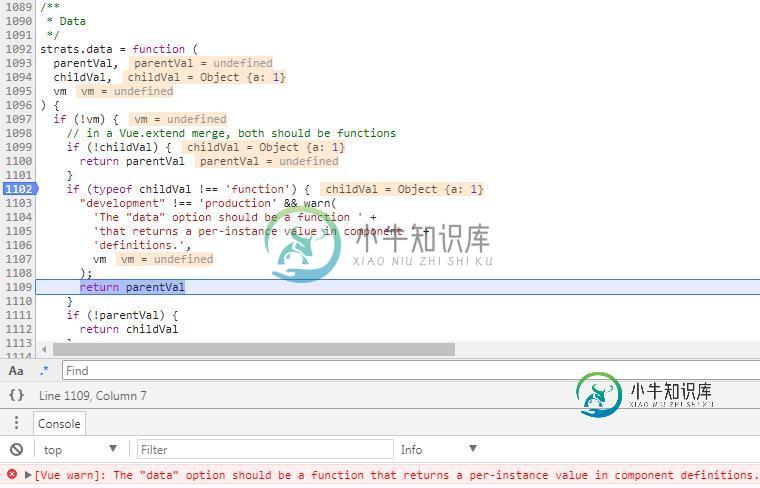
深入理解Vue官方文档梳理之全局API本文向大家介绍深入理解Vue官方文档梳理之全局API,包括了深入理解Vue官方文档梳理之全局API的使用技巧和注意事项,需要的朋友参考一下 Vue.extend 配置项data必须为function,否则配置无效。data的合并规则(可以看《Vue官方文档梳理-全局配置》)源码如下: 传入非function类型的data(上图中data配置为{a:1}),在合并options时,如果data不是f
-
在Typescript中的文件中本地处理全局变量
我公司的工作方式很奇怪。我们使用PHP模板引擎将所有文件复制到一个超文本标记语言中并提供服务。它如下所示: 主html xxx。输电系统 如您所见,IIFE有两层,一层在主超文本标记语言中,另一层在每个中,以确保变量的范围正确包含在每个文件中。然后我使用将编译成。 问题是现在我有一个附加文件,我想在的IIFE中包含xxx.ts。让我们假设与完全相同。 yyy.ts 在这里,我在两个文件中的处遇到问
-
音频文件未完全在语音通道中播放
有了一个机器人,我试着用discord在一个音频通道中播放一个音频文件(mp3)。js、ffmpeg和opusscript。 基本上,这就是它的工作原理: 因此,音频播放,但在结束前停止(例如,对于5s音频文件,它在3s后停止)。机器人留在频道中,我可以再次播放,但对于我的所有文件,它在结束前停止。我怎样才能解决这个问题?
-
Apache POI:从Word模板文件中完全删除图表
null 有人知道这里会出什么问题吗?
-
API 19:网络安全策略不允许明文通信
我有一个公共API,我必须在应用程序中使用。API没有提供,所以我希望允许明文访问。 但是,我仍然支持KitKat(API19)。
-
以正常、安全和有效的方式复制文件
我搜索一个好的方法来复制一个文件(二进制或文本)。我写了几个样本,每个人都工作。但我想听听经验丰富的程序员的意见。 我错过了好的例子,并搜索了一种与C++一起工作的方法。 ANSI-C方式 POSIX方法(K&R在“C编程语言”中使用该方法,更低级别) Kiss-C++-StreamBuffer-Way 复制-算法-C++-方法 Own-Buffer-C++-Way LINUX-WAY//需要ke
-
模板标签参考 - 全局标签 - channelartlist|频道文档
channelartlist|频道文档: 标签名称:channelartlist 标记简介: 功能说明:获取当前频道的下级栏目的内容列表标签 适用范围:全局使用 基本语法: {dede:channelartlist row=6} <dl> <dt><a href='{dede:field name='typeurl'/}'>{dede:field name='typename'/}</a></d
-
模板标签参考 - 全局标签 - arclist|文档列表
arclist|文档列表: 标签名称:arclist 标记简介:织梦常用标记,也称为自由列表标记,其中imglist、imginfolist、specart、coolart、autolist都是由该标记所定义的不同属性延伸出来的别名标记。 功能说明:获取指定文档列表 适用范围:全局使用 基本语法: {dede:arclist flag='h' typeid='' row='' col='' ti
-
 visual-studio-code - VS Code 代码补全不显示文字了?
visual-studio-code - VS Code 代码补全不显示文字了?换了电脑,Macbook air M1 安装 Visual Studio Code - Insiders 版,结果代码补全不显示文字了。
-
如何检测何时使用PyPDF2成功提取pdf文本。提取文本?
我正在使用PyPDF2库通过其函数从PDF文件中提取文本,对于大多数PDF来说,它工作得很好! 但是,一些PDF生成的文本如下所示: \n!"#$% 根据文件,这是可以预期的: 这适用于某些PDF文件,但对其他文件效果不佳,具体取决于使用的生成器。 不幸的是,函数在输出上述文本时不会引发任何异常。 所以,我的问题是,有没有一种方法可以以编程方式检测函数何时返回胡言乱语?
-
使用UITextChecker对Swift 5中的希伯来文文本进行拼写检查
对于任何希伯来文文本,无论文本是否包含任何真实单词,我都会返回真值: 我的设备上安装了希伯来语词典,我在设置中将希伯来语和不将希伯来语设置为“iPhone语言”时都尝试过 我的英语很好。如果UITextChecker是希伯来语的半身像,我有没有其他方法可以解决这个问题?无论如何,我更喜欢另一种解决方案,因为我的应用程序是通用的,而且UIKit在macOS上不起作用。 [更新1] 我花了一些时间调查