《群面模拟》专题
-
 格灵深瞳大模型一面
格灵深瞳大模型一面50分钟。 哦对,我睡过头了,醒来刚好两点,还迟到了两分钟。 据说只有一面,有同学面过,也有同学正在组里实习。主要做预训练,目前只有四个人,包括他和另一个实习生。 问了有没有其他方法的工作,他说他们只做预训练。 面试官提到数据处理和清洗是他们现在的一个痛点。。。 自我介绍 只问了大模型的经历,但是这个项目经历讨论了半个小时,中间差点吵起来了…… 不过对于我们没考虑到的地方,他也给了不少建议,面试官
-
 澜舟科技大模型二面
澜舟科技大模型二面55分钟左右 男面试官,说话很温柔很客气 自我介绍 好奇为啥有段实习是在某个学校 项目提问 项目中遇到的loss上的问题,怎么排查怎么解决,讲个思路 没有八股 代码: 1. 字符串数组的最长公共前缀 2. 给你一个整数数组 nums 和一个整数 target 。 返回 nums 中能满足其最小元素与最大元素的 和 小于或等于 target 的 非空 子序列的数目。 团队介绍 大模型应用,有具体需求
-
 字节 大模型 二面凉经
字节 大模型 二面凉经说字节一面简单的报应来了…… 基本全程围绕项目拷打,对每个步骤的做法和意义都有拷打,问了很多项目在RLHF层面的优化方向,DPO和PPO的trade off方面的问题,答得都不是很好。 看到我做了图文模型工作,问我图文模型的路线有啥,我给他吟唱clip blip llava,它说要最前沿的,直接不会。 代码题做了链表排序,需要空间复杂度为1的算法,我只会递归归并排序那套,寄。 最后明里暗里说我非科
-
 快手推荐大模型一面
快手推荐大模型一面面试时间8月30日 1. 自我介绍 2. 直接做两道题,LC17、LC209 3. 开始问实习,主要在继续预训练的数据、训练参数等上详细问了(一直问我两阶段学习率都是怎么设置的) 问实习的过程中穿插了一些LLM八股 4. 预训练的loss 5. 退火过程的理解 6. LLM的几种架构 7. Llama跟BERT的各种对比 8. Llama结构的演化改进 9. ROPE的原理 10. BN、LN、R
-
 智谱大模型应用三面
智谱大模型应用三面昨天三面推到了今天,面试官比较忙。 1.自我介绍 2.聊了一会蚂蚁的实习,联邦学习安全之类的,说了一下落地难的情况,面试官感觉对这个也是有了解的,以前面试官基本上都是跳过这个 hh。 3.聊暑期实习的项目。聊了一会。 问我前两面做了题没有,我说没有。 1. 写一个 self atten, 只需要写 forward 触发八股为什么要除以根号 dk?不能是 dk?或者其他的吗? 多头是头越多越好还是越
-
Jenkins部署到K8集群
问题内容: 我正在尝试第一次将docker映像部署到kubernetes集群中,我有两个节点master和worker节点都处于启动和运行状态。 我创建了namesapace预发布环境,以在jenkins构建过程中部署我的更改,但我遇到了错误。 詹金斯舞台 你能请人帮我吗? 问题答案: 原因是上下文在您的kubeconfig文件中不存在。您可以运行以检查当前上下文并使用该上下文。
-
云中的Elastic search集群
问题内容: 我有2个Linux VM(都在Cloud Provider的同一数据中心):Elastic1和Elastic2(其中Elastic 2是Elastic 1的克隆)。两者都具有相同的版本centos,相同的群集名称和相同的ES,再次-Elastic2是一个克隆。 我使用服务包装器在启动时自动启动它们,并将彼此的ip引入各自的iptables文件,因此现在我可以在节点之间成功ping。 我
-
如何建立ES集群?
问题内容: 假设我要在5台计算机上运行Elasticsearch集群,并且它们都连接到共享驱动器。我将Elasticsearch的一个副本放到了该共享驱动器上,以便所有三个都可以看到它。我是否只是在我所有机器上的共享驱动器上启动Elasticsearch,并且集群将自动发挥作用?还是我必须配置特定设置以使Elasticsearch意识到它可以在5台计算机上运行?如果是这样,相关的设置是什么?我应该
-
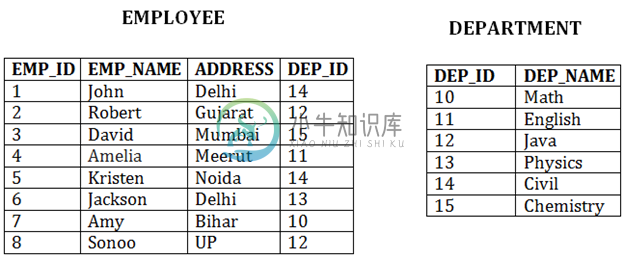 DBMS群集文件组织
DBMS群集文件组织当两个或多个记录存储在同一文件中时,它称为群集。 这些文件在同一数据块中有两个或多个表,并且用于将这些表映射到一起的键属性仅存储一次。 该方法降低了在不同文件中搜索各种记录的成本。 当经常需要以相同条件连接表时,将使用群集文件组织。这些连接只会从两个表中提供几条记录。 在给定的示例中,仅检索指定部门的记录。此方法不能用于检索整个部门的记录。 在这种方法中,可以直接插入,更新或删除任何记录。 数据根
-
Kafka费者群组示例
消费者群组是来自Kafka主题的多线程或多机器消费。 消费者群组 消费者可以通过使用加入一个组。 一个组的最大并行度是该组中的消费者的数量 ← 分区的数量。 Kafka将一个主题的分区分配给组中的使用者,以便每个分区仅由组中的一位消费者使用。 Kafka保证只有群组中的单个消费者阅读消息。 消费者可以按照存储在日志中的顺序查看消息。 重新平衡消费者 添加更多流程/线程将导致Kafka重新平衡。 如
-
 Kafka群集体系结构
Kafka群集体系结构有关Kafka群集体系结构,请看下面的结构图。 它显示了Kafka的集群图。 下表描述了上图中显示的每个组件。 Broker - Kafka集群通常由多个代理组成,以保持负载平衡。 Kafka经纪人是无状态的,所以他们使用ZooKeeper维护他们的集群状态。 一个Kafka代理实例可以处理每秒数十万次的读写操作,每个Broker都可以处理TB消息,而不会影响性能。 Kafka经纪人的领导人选举可
-
无状态EJB和集群
场景:EjbA和EjbB都是远程无状态会话bean。 对b的这些方法调用中的任何一个都可以发生在集群环境中的不同节点/VM上,这是否正确? 甚至连对method1的调用? 我的意思是,如果一些客户端调用方法foo,是否会发生这样的情况:在这个事务中,在node1上调用方法1,下一个对方法1的调用,在同样的foo()调用期间,转到node2上的Ejb实例? 解释下面引用的"Enterprise Ja
-
AWS Aurora群集endpoint用法
如果我使用带有2个读取副本的AWS Aurora MYSQL数据库,我需要使用不同的连接字符串进行读写,还是由集群endpoint为我路由流量?如果是这样的话,对于一个写得更少的应用程序来说,让读副本成为比主副本更大的实例(更强大)是否明智,因为它几乎不会被使用? 提前道谢。
-
Java正则表达式群
有谁能让我睡着吗? 我不知道为什么这段代码现在不工作了。 甚至几个小时前它还能工作!! 请让我知道是什么问题。 输入:300+25 预期输出: 300 + 25 + 输出: null null null 通知PLZ
-
Spark独立集群调优
应用程序不是那么占用内存,有两个连接和写数据集到目录。同样的代码在spark-shell上运行没有任何失败。 寻找群集调优或任何配置设置,这将减少执行器被杀死。