《交流群》专题
-
Java8的流:为什么并行流比较慢?
考虑到我有2个CPU核心的事实,并行版本不是应该更快吗?有人能给我一个提示为什么并行版本比较慢吗?
-
Flink Streaming:由控制流控制的数据流
我有一个问题是这个问题的变体:Flink:如何存储状态和在另一个流中使用? 我有两条流: val ipStream:DataStream[IP地址]= <代码>val routeStream:数据流[路由表]= 我想知道哪个包裹使用哪条路线。通常可以通过以下方式完成: 这里的问题是,我无法在这里真正为流设置密钥,因为这既需要完整的表,也需要ip地址(并且密钥必须独立计算)。 对于中的每个元素,我需
-
音频流Python上的Google流语音识别
我已经搜索了Google的所有可用文档,但我找不到Python音频流上的流式语音识别示例。 目前,我正在Django中使用Python语音识别从用户那里获取音频,然后收听音频。然后,我可以保存文件并运行google语音识别,或者直接从创建的音频实例中运行。 有人能指导我如何对音频流执行流式语音识别吗?
-
从流[重复]中获取子列表的流
我有一个SeniorEmployee类,它有一些属性,在这个属性下我有JuniorEmployee列表。现在我的标准是在SeniorEmployee中通过流和基于一些标准进行迭代,然后对于与筛选标准匹配的SeniorEmployee,我们需要在juniorEmployee列表中进行迭代,并计算他们的总薪资。那么,我如何通过流在单个lambda表达式中实现它呢?请帮帮忙。 如果EmpCode为10,
-
Spring云数据流流部署到云铸造
-
我可以将流转换为流吗?[副本]
这可能吗(伪Java): 更笼统地说,在流上是否有一个操作可以增加流中的元素数量(而不是像那样减少元素数量)?
-
工作流程结构、促销优惠流程
非常感谢您的帮助,在实施细节方面,以及我下面的两个澄清问题: 背景: 创建优惠促销工作流程。优惠有截止日期(我们在优惠被接受后开始倒计时。) 用户可以选择拒绝报价(工作流程随后停止)一旦报价被接受,他们将有7天的时间尝试兑换返现积分。一旦他们满足返现积分要求,我们将把积分记入他们的账户 第一个问题:下面的逻辑正确吗?我正在使用信号。 我是如何考虑编写工作流的(然而,当我尝试发出不同的信号时,我似乎
-
如何从Akka事件流构建Akka流源?
当接收到消息时,它将运行,并将接收到的每个项发布到。 我怎么能那么做? 以防万一它可能会添加更多选项,请注意,另一个代码块是的Websocket处理程序。
-
AWS:无法确定流上传的流大小
我正在尝试将图像文件从临时php文件存储路径上传到S3。文件大小约为100 kb,最大为500 kb。 当上传发生时,我得到这个错误: 我不认为我需要在这里进行分段上传,因为文件不是太大。此外,上传从我的本地系统到 S3,但是当我在 AWS 上部署 PHP 实例时,上传会给我一个错误。任何帮助将不胜感激。 谢谢你
-
集群模式下的Redis流
Redis streams是否受益于群集模式?假设您有10个流,它们是分布在集群中还是全部分布在同一个节点上?我计划使用Redis streams实现真正的高吞吐量(每秒200万条消息),因此我担心Redis streams在这种规模下的性能。 如果Redis streams不能在集群模式下进行开箱即用的扩展,那么任何关于水平扩展Redis streams的指导都会非常棒。
-
Java中的流程生成器和流程-如何执行超时的流程?
问题内容: 我需要在Java中执行具有特定超时的外部批处理文件。这意味着,如果批处理执行的时间比指定的超时时间长,我需要取消执行。 这是我编写的示例代码: 批处理文件“ wait.bat”是这样的: 如您在代码中看到的,批处理文件将花费25秒完成(main方法的第一行),并且Timer将在5秒后销毁命令。 这是我的代码的输出: 如您在输出中看到的,最后一行(“ Really Done …”)在第5
-
实现流云数据流转换,为流中的每个元素调用API
我相信,这不是实施这种转变的最佳方式。我想知道是否有更好的方法从数据流作业中进行查找。 跟进: 试图将用例实现为侧输入:
-
来自单个Google云数据流作业的并行数据流流水线
我试图从一个数据流作业中运行两个分离的管道,类似于下面的问题: 一个数据流作业中的并行管道 如果我们使用单个p.run()使用单个数据流作业运行两个分离的管道,如下所示: 我认为它将在一个数据流作业中启动两个独立的管道,但它会创建两个包吗?它会在两个不同的工人上运行吗?
-
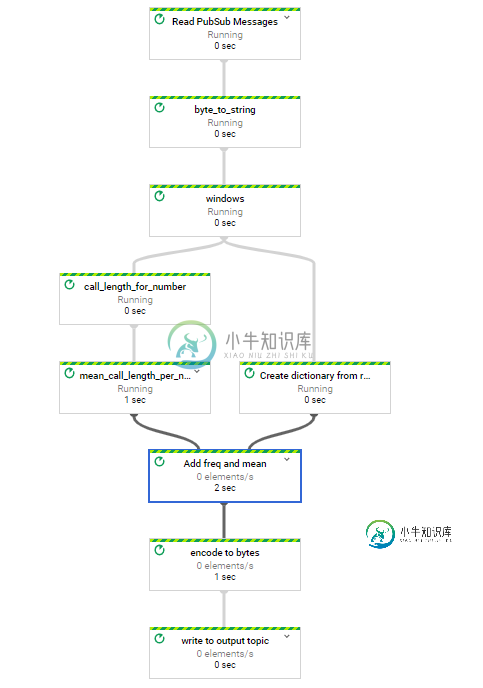 在流式流水线中组合多个边输入时数据流失败
在流式流水线中组合多个边输入时数据流失败我已经用Python SDK(Apache Beam Python 3.7 SDK 2.19.0)构建了一个窗口流数据流管道。初始数据的表示如下: 其思想是找出给定窗口中每行号码的平均通话长度。数据作为CSV的行从pub/sub中读取,我向所有行添加一个与该数字的平均调用长度相对应的值: 我使用以下管道: 有什么想法吗?
-
正当我提交交易时违反了完整性约束
问题内容: 我正在使用Hibernate 4.0 Final和ojdbc6开发我的Web应用程序。一切正常,除非我尝试插入新的父/子关系。首先,这些是实体: 让我们看看这两种情况: 一名员工已经存在,我尝试向其添加新地址->正常工作。 员工不存在,我尝试创建一个新员工。两种不同的情况: a)我只插入一名雇员(无地址)->可以正常工作。 b)我插入并添加了employee及其地址-> 失败 。我必须