《秋招想进大厂该如何准备》专题
-
如何配置Maven2发布到艺术工厂?
目前,我有一个Maven2项目,在运行时构建一个JAR: 我现在需要调整,以将此JAR()发布到运行于以下位置的ArtFactory服务器: 我尝试添加一个<代码> 关于如何让出版业开始工作,有什么想法吗?为了简单起见,假设这个人工repo经过身份验证,可以接受用户使用和进行的发布/写入。
-
 如何将卡与残障晶圆厂重叠?
如何将卡与残障晶圆厂重叠?我有一个带有CardView和禁用的的布局,我以编程方式将其设置为enabled,当FAB被启用时,所有工作都很好,但当我将其设置为disabled时,它会在卡后面。 我已经试着通过设置一个更高的高度来设置卡片和晶圆厂的高度,但是当它被禁用的时候,它仍然会高于… 下面是它的样子: 我将显示它的重叠,就像当enabled设置为true时: 下面是我的代码:
-
如何查看准备好的语句的内容?
问题内容: 我正在努力学习在PHP中使用mysqli编写预备语句,通常,如果我对查询有疑问,我只需将其回显到屏幕上,就可以看到第一步。 我如何用准备好的陈述来做到这一点? 替换变量后,我想查看SQL语句。 问题答案: 使用准备好的语句: 准备该语句时,它会发送到MySQL服务器 当您绑定变量+执行语句时,只有变量被发送到MySQL服务器 并且语句+绑定变量在MySQL服务器上执行-无需在每次执行语
-
如何在PHP中使用mysqli准备的语句?
问题内容: 我正在尝试准备好的语句,但是下面的代码不起作用。我收到错误消息: 致命错误:在第12行的/var/www/prepared.php中的非对象上调用成员函数execute() 另外,我需要对准备好的语句使用mysqli吗?谁能指出我关于从连接到插入再到带有错误处理的选择的准备好的语句的完整示例? 问题答案: 从文档: 在执行语句或获取行之前,必须使用mysqli_stmt_bind_pa
-
如何查看准备发送给Datadog的指标
所以我对度量和测微计是新手。我遵循了本教程,在本教程中,我们设置了一些基本的仪表,如计数器和仪表,并公开了这些指标。当我点击endpoint时,我能够看到指标。我可以在那里看到我的自定义仪表。 所以现在我尝试将指标公开给datadog。我导入了以下依赖项: 并且在我的应用程序属性文件上也有这个: 我知道我没有包括任何数据的url或任何类似的内容,但是我的印象是,我可以通过访问像< code>/ac
-
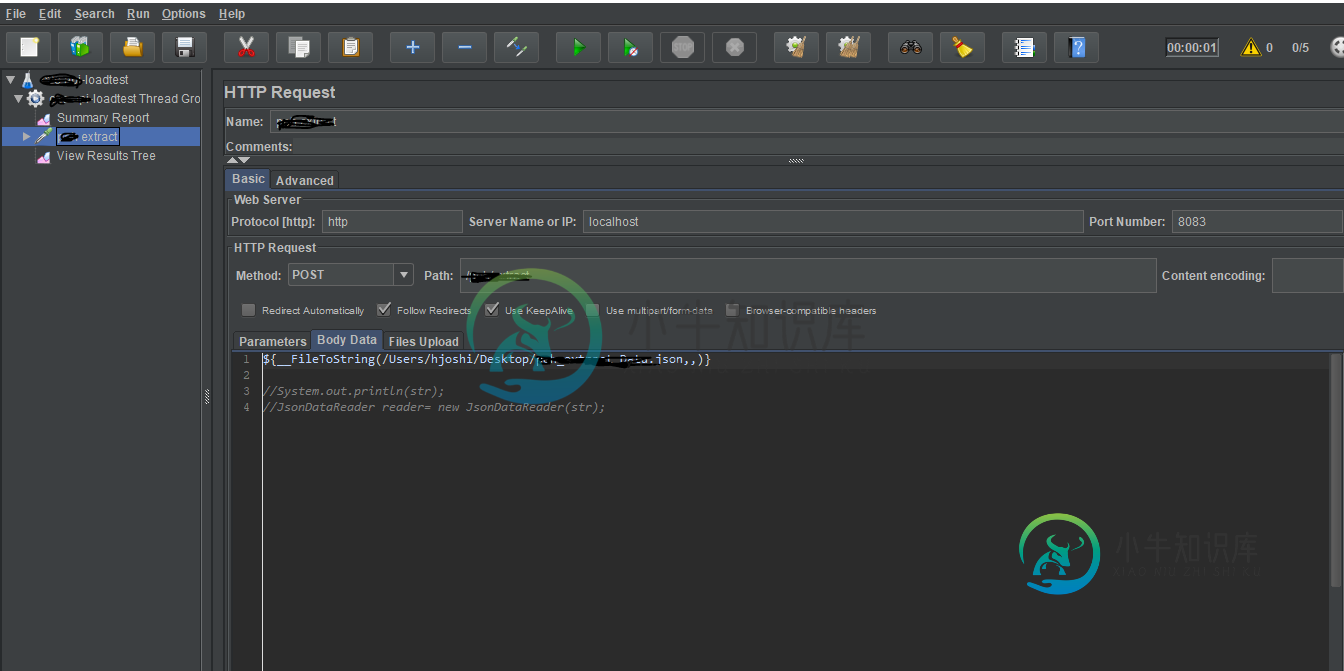 如何准备Jmeter中json文件中的多行
如何准备Jmeter中json文件中的多行我是Jmeter的新手,我正在json文件中生成随机数据(比如n个请求)。 以下是json文件 < code>{"firstName":"Stella "," lastName":"Barrera "," password":"BUiVwvAw "," email":"Alex3@test。COM "," orgName ":" quickers Consulting "," locationNa
-
程序员如何准备面试中的算法
备战面试中算法的五个步骤 对于立志进一线互联网公司,同时不满足于一辈子干纯业务应用开发,希望在后端做点事情的同学来说,备战面试中的算法,分为哪几个步骤呢?如下: 1、掌握一门编程语言 首先你得确保你已掌握好一门编程语言: C的话,推荐Dennis M. Ritchie & Brian W. Kernighan合著的《C程序设计语言》,和《C和指针》; C++ 则推荐《C++ Primer》,《深度
-
Part 2 :准备:如何学习Node.js - 常用软件
1)oh my zsh是我最习惯的shell,终端下非常好用 配合iterm2分屏 + spectacle全屏,几乎无敌 2)brew是mac装软件非常好的方式,和apt-get、rpm等都非常类似 安装4个必备软件 brew install git 最流行的SCM源码版本控制软件 brew install wget 下载、扒站神器 brew install ack 搜索代码神器 brew ins
-
Part 2 :准备:如何学习Node.js - 基础学习
犀牛书,《JavaScript权威指南》,没事就多翻翻,看多少遍都不为过。 2)个人学习和技术选型都要循序渐进 先能写,采用面向过程写法,简单理解就是定义一堆function,然后调用,非常简单 然后再追求更好的写法,可以面向对象。对于规模化的编程来说,oo是有它的优势的,一般java、c#,ruby这些语言里都有面向对象,所以后端更习惯,但对于语言经验不那幺强的前端来说算高级技巧。 等oo玩腻了
-
如何找到最大堆栈大小?
问题内容: 我正在使用Ubuntu 11.04。如何找出进程的最大调用堆栈大小以及堆栈中每个帧的大小? 问题答案: 您可以使用查询最大进程和堆栈大小。堆栈框架没有固定的尺寸。它取决于每个帧需要多少本地数据(即本地变量)。 要在命令行上执行此操作,可以使用ulimit。 如果要为正在运行的进程读取这些值,我不知道执行此操作的任何工具,但是查询/ proc文件系统很容易:
-
如果有两个项目,要进行代码比较差异,你该如何操作?
本文向大家介绍如果有两个项目,要进行代码比较差异,你该如何操作?相关面试题,主要包含被问及如果有两个项目,要进行代码比较差异,你该如何操作?时的应答技巧和注意事项,需要的朋友参考一下 https://www.matools.com/compare 在线对比代码
-
该方法如何推断类型
问题内容: 下面的方法完美无瑕 但是我没有指定此方法中的 是什么。编译器如何将 方法返回的值分配给 未指定类型i 的变量? 我只是测试了答案的有效性,指出了从该方法的返回类型推断出的答案。它似乎没有解决。请检查以下代码。它甚至不编译 再次修改源代码并对其进行测试,结果导致编译时错误 问题答案: 该方法如何推断类型 没有。泛型方法不推断其泛型类型-这就是为什么称为 类型参数 的原因。方法的 调用者
-
Hadoop当下又该如何配置?
本文向大家介绍Hadoop当下又该如何配置?相关面试题,主要包含被问及Hadoop当下又该如何配置?时的应答技巧和注意事项,需要的朋友参考一下 解答: Hadoop现在拥有3个配置文件: 1,core-site.xml; 2,hdfs-site.xml; 3,mapred-site.xml。 这些文件都保存在conf/子目录下。
-
我应该如何替换“上的”
例如,我有这样的代码 如何将“\on the”替换为replace eAll()?
-
前端 - Vanblogs 该如何部署呀?
请问Vanblogs 该如何部署呀,谢谢各位大神 看过相应的操作说明,但是看不懂,小白一个