《贝壳找房内推》专题
-
Java 内存泄漏
本文向大家介绍Java 内存泄漏,包括了Java 内存泄漏的使用技巧和注意事项,需要的朋友参考一下 在Java中,垃圾回收(析构函数的工作)是使用垃圾回收自动完成的。但是,如果代码中有引用它们的对象怎么办?它无法取消分配,即无法清除其内存。如果这种情况一再发生,并且创建或引用的对象根本没有被使用,它们就会变得无用。这就是所谓的内存泄漏。 如果超过了内存限制,则程序将通过抛出错误(即“ OutOfM
-
Markdown 内联代码
本文向大家介绍Markdown 内联代码,包括了Markdown 内联代码的使用技巧和注意事项,需要的朋友参考一下 示例 Markdown支持添加内联代码like this,该代码是通过将文本包装在反引号中获得的: `code here` 或者,您可以将内联代码放在<code>和</code>HTML标记之间。 考虑以下降价代码: 这将产生以下输出: This是内联代码块!This也是一个! 如果
-
Markdown 内联链接
本文向大家介绍Markdown 内联链接,包括了Markdown 内联链接的使用技巧和注意事项,需要的朋友参考一下 示例 markdown中链接的形式如下。 例如,这将带您到Example.com创建
-
河内塔问题
本文向大家介绍河内塔问题,包括了河内塔问题的使用技巧和注意事项,需要的朋友参考一下 河内塔是一个难题的问题。我们有三个看台和n个光盘。最初,将光盘放置在第一支架中。我们必须将光盘放入第三个或目标支架,第二个或辅助支架可以用作帮助支架。 但是要遵循一些规则。 每个动作我们只能传送一张光盘。 只能从架子上取出最上面的光盘。 较大的光盘不会放在较小的光盘的顶部。 此问题可以通过递归轻松解决。首先,使用
-
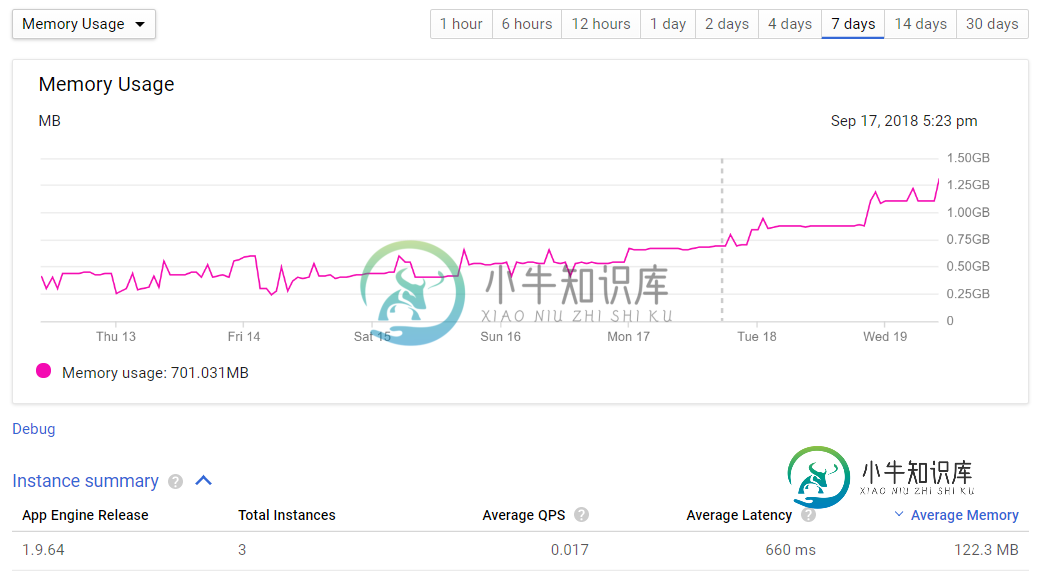 软内存使用
软内存使用我是新来的谷歌应用程序引擎,但试图找到我的应用程序消耗多少软内存的真正来源。 我正在标准环境中运行F1实例类(128MB内存限制),尚未出现“软内存超出”错误。 我用来检查内存的工具有: GoogleAppEngine仪表板(内存使用量图表)——显示了过去一周内存使用量从250MB逐渐增加到1GB以上。请参阅下面的第一张图片 GoogleAppEngine仪表板(实例摘要表)-显示122MB的平均
-
读取JSON内容
问题内容: 我正在使用jsoup抓取一些HTML数据,效果很好。现在,我需要提取一些JSON内容(仅JSON,而不是HTML)。我可以使用jsoup轻松做到这一点,还是必须使用另一种方法来做到这一点?jsoup执行的解析是对JSON数据进行编码,因此无法使用Gson正确解析。 谢谢! 问题答案: 虽然很棒,但Jsoup是HTML解析器,而不是JSON解析器,因此在这种情况下它没有用。如果您尝试过,
-
Informix内存泄漏
问题内容: 我使用Informix遇到了一个奇怪的问题(具体来说,我使用的是IBM.Data.Informix命名空间,即4.10 Client SDK)。我正在使用ODBC连接到IBM Informix数据库,并且遇到内存泄漏问题。该文档相当稀疏,并且我只能使用当前安装的驱动程序/ SDK。这是我用于数据库上下文的代码: } 我已尝试处置并关闭所有可以的连接,但这似乎无济于事。我是否缺少某些东西
-
CPython内存分配
问题内容: 这是一篇受此评论启发的帖子,内容涉及如何在CPython中为对象分配内存。最初,这是在创建列表并将其添加到for循环中_以_ 实现列表理解的上下文中。 所以这是我的问题: CPython中有多少个不同的分配器? 每个功能是什么? 什么时候被正式称为?(根据此评论中的内容,列表理解可能不会导致调用, python在启动时会为其分配多少内存? 是否有规则来控制哪些数据结构在此存储器上首先获
-
jsp内置对象
本文向大家介绍jsp内置对象,包括了jsp内置对象的使用技巧和注意事项,需要的朋友参考一下 JSP中一共预先定义了9个这样的对象,分别为:request、response、session、application、out、pagecontext、config、page、exception 1、request对象 request对象代表了客户端的请求信息,主要用于接受通过HTTP协议传送到服务器的数据
-
Java 8 Hashmap内部
我已经完成了Java8 Hashmap的实现,并带着以下疑问来到这里。请帮我澄清一下: 我在一篇文章中读到,具有相同哈希代码的节点将被添加到与链表相同的bucket中。它说,这个链表的新节点将被添加到head而不是tail中,以避免尾部遍历。但当我看到源代码时,新的节点被添加到尾部。对吗 我没有完全理解这个变量的最小树容量。是不是经过这么多的计算,整个地图会被转换成树(从数组到树)
-
Java内存分配
我有一个一直在思考的问题。以这个特殊的类为例 假设我有一个B类,它拥有一个使用listOne读取详细信息的方法。要查看数组列表,我需要首先获取列表的大小,以便我的代码知道数组列表何时结束。有两种方法可以做到这一点,一种是 或者我也可以用 在内存和效率方面,哪种方法更好?此外,假设我正在递归地读取一个非常大的数组。为了简单起见,让我们假设递归读取此数组将导致堆栈溢出异常。在这种情况下,第一个方法在理
-
p7s文件内容
有没有人知道p7s文件的内容? 文件中至少有一个数字签名,我可以很容易地找到它,但我想捕获文件中包含用私钥加密的部分的部分,即数字签名的不可否认部分。 0版本 1 8X(信息类型) %3%1到下一信息的偏移量(文件长度-%4) (变量+4)x509证书(嵌入,集合成员:CA电子邮件) (变化)交叉证书对信息,未知类类型 (变化)未知类类型的证书(如果需要,用尾随的零填充) 最后,我检查集合中的证书
-
JVM堆栈内存
我们Java开发人员有时会使用来确保我们为每个特定于线程的堆栈提供了1MB的空间。现在,我经常感到困惑,JVM从哪里借用了1MB,从堆或系统内存中借用,或者Java为线程分配任何特定的内存。你能帮我理解一下吗? 此外,我们是否有一个可视化(插件)运行时工具,可以以可理解的方式显示堆和堆栈的内容? 提前感谢。
-
PowerShell内联If(IIf)
Microsoft Connect已经退役,但好消息是,对PowerShell(Core)语言中三元运算符的支持似乎正在进行中。
-
Java内存和Windows
今天我注意到一些有意义的事情,但是我不能准确地解释语义。 基本上,我创建了一个简单的旧java方法,其中有一个永无止境的while循环。在这个循环中,我创建了一些字符串并将它们放在HashMap中。我真正想要的是一个在一段时间内运行并建立其内存利用率的进程。 } 该过程从< code>-Xms512m -Xmx512m开始。 一旦开始,我可以使用来查看我的java进程。我试图理解的位是虚拟内存和物