《贝壳找房内推》专题
-
JS深度拷贝Object Array实例分析
本文向大家介绍JS深度拷贝Object Array实例分析,包括了JS深度拷贝Object Array实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了JS深度拷贝Object Array。分享给大家供大家参考,具体如下: 遇到的问题 typeof [] 结果为 object typeof {} 结果为 object [] instanceof Array 结果为 true {} i
-
贝宝抓取授权:立即拿到钱
在Angular应用程序中,我授权一个订单,并希望稍后在服务器上捕获它(Spring Boot)。服务器请求的实现方式如下:https://github.com/paypal/checkout-java-sdk/blob/developer/checkout-sdk-sample/src/main/java/com/paypal/authorizeintentexamples/captureOrd
-
日元对贝尔曼福特的改善
我一开始从维基百科上得到著名的颜教授对Bellman-Ford算法的优化,后来我在几本教科书的练习部分发现了同样的改进(例如,这是Cormen中的24-1问题和Sedgewick的“算法”中的网络练习N5)。 以下是改进: Yen的第二个改进首先在所有顶点上指定一些任意的线性顺序,然后将所有边集划分为两个子集。第一个子集Ef包含所有边(vi,vj),因此i 不幸的是,我没有找到这个界| V |/2
-
贝尔曼·福特:所有最短路径
我已经成功地实现了Bellman-Ford,当边具有负权重/距离时,找到最短路径的距离。我无法让它返回所有最短路径(当最短路径有联系时)。我设法用Dijkstra获得所有最短的路径(给定的一对节点之间)。贝尔曼-福特有可能吗?(只是想知道我是否在浪费时间)
-
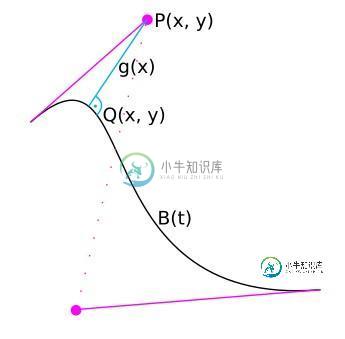 贝塞尔曲线到点的垂直线
贝塞尔曲线到点的垂直线我需要得到一条三次(2D)bezier曲线B(t)的点Q,其中从点Q到另一个给定点P的直线与bezier曲线垂直相交。 我知道:P,B(t) 我寻找:Q(基本上我想要g的斜率,但当我知道Q时,我可以很容易地计算出来,但g的斜率已经足够了) 注意,我认为这个ansatz是错误的。这只是为了完整性而包括的。 其中B(x)是笛卡尔坐标系下的bezier曲线,B'(x)是(笛卡尔坐标系下的)导数,k是与y
-
机器学习:贝叶斯、KNN、决策树
贝叶斯分类:贝叶斯分类是一类分类算法的总称,这类算法均已贝叶斯定理为基础,故统称为贝叶斯分类。 先验概率:根据以往经验和分析得到的概率。我们用 \small P(Y) 来代表在没有训练数据前假设\small Y拥有的初始概率。 后验概率:根据已经发生的事件来分析得到的概率。以 \small P(Y|X) 代表假设\small X 成立的情下观察到 \small Y数据的概率,因为它反映了在看到训练数据\small X后\small Y成立的置信度。
-
 分贝通产品运营2面面经
分贝通产品运营2面面经1.自我介绍 2.你在上一份产品助理实习的主要职责是什么? 需求文档、开发沟通、产品内容设计、数据清洗、数据精确度分析 3.实习中有没有遇到什么较难解决的问题?是怎么解决的? 技术层面 python、SQL的一些功能不熟悉——周末花时间学 重复大量的数据需要搜集、处理——自学爬虫等,自动化处理重复性工作,给自己学习其他内容留足时间 其他层面 对于产品涉及到的某些行业不够了解——读研报,做脑图梳理
-
朴素贝叶斯 - i100、i500健康手环
现在我们要为iHealth公司销售健康手环产品,从而和Nike Fuel、Fitbit Flex竞争。iHealth新出产了两件商品:i100和i500: iHealth 100 能够监测心率,使用GPS导航(从而计算每小时运动公里数等),带WiFi无线,可随时上传数据到iHealth网站上。 iHealth 500 除了提供i100的功能外,还能监测血液含氧量等指标,且提供免费的3G网络连接到i
-
在贝格乐建立远程数据库
Tips 在贝格乐,您的帐户需要具有管理员的权限才能创建Git数据库。如果您的帐户没有管理员的权限,可以委托有此权限的人来创建数据库。友情提示:您可以使用免费方案的贝格乐空间哟。 从这里获取空间 请登录到贝格乐,然后,从创建数据库的项目菜单中点击“Git”。如果您的空间还没有任何项目,请先创建一个项目。 如果页面没有显示“Git”标签,请先激活Git功能。“项目设置” > 在 “Git设置”
-
3.3 拷贝、粘贴画布的某部分
本节,我们将仍然探讨drawImage()方法的另一个有趣的用法——拷贝画布的某部分。首先,我们在画布的中央绘制一个黑桃,然后拷贝黑桃的右半部分并粘贴到左边,再拷贝黑桃的左半部分并粘贴到右边。 图3-4 拷贝画布的某个部分 绘制步骤 按照以下步骤,在画布中央绘制黑桃,然后把图形的某部分拷贝、粘贴回画布: 1. 定义画布上下文: window.onload = function() { //
-
查找最近24小时内已更改的文件
问题内容: 例如,我的Ubuntu机器上正在运行MySQL服务器。最近24小时内某些数据已更改。 哪些(Linux)脚本可以找到最近24小时内已更改的文件? 请列出文件名,文件大小和修改时间。 问题答案: 要查找特定特定目录及其子目录中最近24小时(最后一整天)内修改的所有文件,请执行以下操作: 应该是你喜欢的 在之前是非常重要的-这意味着任何改变一天或更短前。相反,“ 之前” 表示至少一天前发生
-
jQuery或javascript查找页面的内存使用情况
问题内容: 有没有办法找出网页或jquery应用程序正在使用多少内存? 这是我的情况: 我正在使用jquery前端和一个以JSON提供数据的restful后端构建数据密集型webapp。页面被加载一次,然后一切都通过ajax发生。 用户界面为用户提供了一种在用户界面内创建多个选项卡的方式,每个选项卡可以包含大量数据。我正在考虑限制它们可以创建的选项卡的数量,但我认为仅在内存使用量超过特定阈值时才限
-
如何在文本框中找到并键入内容
问题内容: 我无法找到并以错误结束。 java.lang.Error:未解决的编译问题:Wait类型的until(Function)方法不适用于自变量(new Function(){})函数无法解析为类型 类型为By的方法id(String)不适用于com.junit.qa.testFluent.myDynamicElement(testFluent.java:49)上的参数(By) 问题答案:
-
用爬虫找出哪个div包含“主要内容”
所以...我们如何确定哪个是页面的“主div”? 我很确定谷歌会这么做。他们肯定知道元素在页面上的位置,例如,如果某些东西位于“主要内容”或页脚中。他们怎么会知道这些? 我可以看到的在大范围内做到这一点的方法是: 编辑:我想一种渲染它的方法是不渲染每一个单独的页面。而是呈现域。例如。如果域结构是http://example.com/post/1-post-name/,我可以保存它的一个呈现,下次我
-
如何在带有BS4的div元素内部找到?
我正在制作一个python脚本,给出Scratch.mit.edu网站上的前5个特色项目。我正在使用请求获取数据。具有这些项目标题的元素位于div标记中,但当我使用bs4时,它不显示div标记的子项或后代。我怎么看标签里面? 我已经尝试了find_all()、find()、.descendents和.children。 我需要 的输出 匿名用户 API 使用页面用来更新内容和解析json响应的ap