《YY直播》专题
-
将Dataframe直接保存到csv到s3 Python
我有一个熊猫的数据文件,我想上传到一个新的CSV文件。问题是我不想在将文件转移到S3之前将其保存在本地。是否有类似于to_csv的方法可以直接将数据文件写入s3?我使用的是boto3。 以下是我目前所拥有的:
-
Java&Apache-Camel:从直接endpoint到文件endpoint
我可以通过使用以下伪测试启动路由(关键是我可以通过)手动启动路由) 扩展 只是一个标记接口 加载SpringContext和stuft 问题是,我必须设置文件名。我读过一些camel设置header的东西(在文件endpoint期间)。它是一个带有时间戳的通用字符串,如果我不设置文件名-写入的文件将获得这个通用字符串作为文件名。
-
可直接访问的数据结构Java
我有以下情况: 只能扩展的数据结构(我只能在尾部添加内容) 我需要能够跟踪我已经看到的元素(我有一个索引,理想情况下我希望能够从这个特定元素开始再次遍历列表) 我希望读取永远不会阻塞,并且添加的新元素只会锁定队列的尾部而不是整个队列 这是一个由多个线程大量修改的结构。 最佳的数据结构是什么? ArrayList.如果能够直接访问使用索引看到的最后一个元素,这将是理想的,但它会导致并发修改异常。我可
-
如何创建不直接赋值的JTable
001/电视购买/约翰·史密斯/真 002/冰箱购买/让·史密斯/假
-
Intellij Idea中任意位置的垂直柱
Intellij Idea在第120栏有一条垂直线。 有没有办法将其移动到任意列(我希望每行100个符号)?
-
为什么不直接上传 xls 文件?
我使用dropwizard制作了一个非常传统的文件上传方法。 所以我在资源中有一个这样的方法 里面没有什么特别的,它只是保存到一个路径,使用java.nio库,就像这样 它只是不会上传excel文件。我在其他地方读到excel文件和它们的底层类型受到怀疑。请问我需要做什么?
-
调试垂直。Eclipse内部的x-Maven-Projekt
我目前正在使用maven在Eclipse中开发Vert. x应用程序。我做了Projekt-Setup,如下所述:http://vertx.io/maven_dev.html 一切进展顺利,项目成功构建,服务器通过maven启动配置以调试模式成功启动,目标是:package vertx:runMod 但是,如果我设置了一个断点,调试器会停在正确的位置,并向我显示正确的堆栈跟踪,但它不会向我显示源代
-
 Android sdk 18 TextView gravity不能垂直工作
Android sdk 18 TextView gravity不能垂直工作我对SDK 18有一个问题。我的文本视图的重力不能垂直工作。但它正在使用sdk17。 图片和代码: 列表视图标题。xml格式: AndroidManifest.xml AndroidManifest.xml 带有黑色背景的textview Android:background = " # 000000 " 如果有人有主意。我试着用match_parent改变wrap_content。 唯一有效的是
-
在Aero窗口中禁用垂直同步
我正在为Windows(XP、Vista、7、8)开发一个窗口化(非全屏)OpenGL应用程序,其中VSync和GPU帧队列会导致非常明显的(和糟糕的)输入延迟。我使用了wglSwapBufferEXT来禁用VSync,并在SwapBuffers之后使用glFinish来防止帧排队。 问题是,在启用Aero的Windows版本上,输入延迟仍然存在。禁用Aero可以解决这个问题,但我们不想强迫用户这
-
SparkSQL-直接读取拼花地板文件
我正在从Impala迁移到SparkSQL,使用以下代码读取一个表: 我如何调用上面的SparkSQL,这样它就可以返回这样的东西:
-
垂直JPanel手动定位:哪种布局?
根据我的要求: null 详情: 我想通过只指定组件的垂直位置,将它们垂直地放在列容器中(像垂直框)。在不失去BoxLayout等布局的其他好处的情况下,最好的方法是什么? 在垂直框中,必须使用填充物来设置组件的垂直位置,或者通过调整组件的大小来设置组件的垂直位置,这样的可能性是不存在的: null
-
Selenium Java查找项,直到页面加载
我有这样的代码 但之后我尝试在页面上查找元素,WebDriverWait会一直等到页面完全加载,然后开始搜索。如果我尝试这样的事情
-
通过直线连接问题配置JDBC
使用mapr沙箱如果我尝试通过beeline连接到配置单元,使用以下命令: 它连接无问题 如果我尝试使用实际地址连接: 错误:无法使用JDBC URI:JDBC:hive2://192.168.48.138:10000:null(状态=08S01,代码=0)0:JDBC:hive2://192.168.48.138:10000(关闭)>打开客户端传输 我可以通过cli看到hiveserver2正在
-
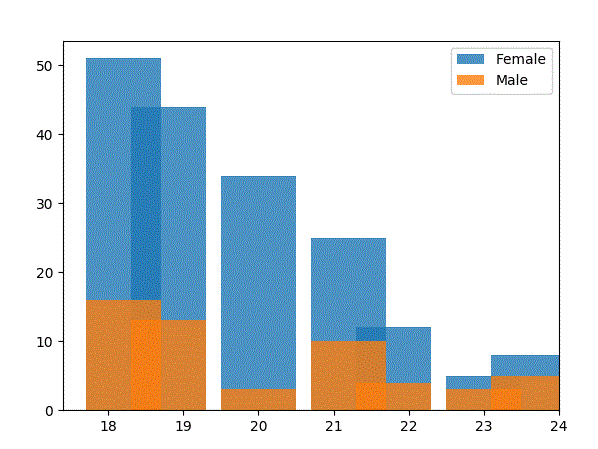 如何阻止pyplot重叠直方图仓?
如何阻止pyplot重叠直方图仓?我确信有一个简单的答案,我只是看错了东西,但是我的pyplot直方图发生了什么?这是输出;数据包含年龄在18至24岁之间的参与者,没有分数年龄(没有人是18.5岁): 为什么箱子是这样交错的?当前宽度设置为1,所以每个条应该是一个箱的宽度,对吗?当宽度小于0.5时,问题会变得更糟,因为条形看起来像是在完全不同的条盒中。 代码如下: 谢谢!
-
 如何删除Android Studio中的垂直线?
如何删除Android Studio中的垂直线?