《群面技巧》专题
-
 麦风科技 AI产品实习1面
麦风科技 AI产品实习1面1.调研需求哪方面有难度 2.产品经理发现客户需求无法满足 3.如何评估产品的功能优先级 4.面对陌生工作怎么处理 第一次面试啊啊啊发挥不好慢慢来吧积累经验勇敢拼搏
-
 联想—技术运维工程师一面
联想—技术运维工程师一面1. 视频上传如果视频上传中断如何恢复处理(谷粒学院) 2. 视频1.5倍速,拖进度条如何流畅处理(谷粒学院) 3. 内存回收机制 4. kafka的应用场景 5. kafka和RabbitMQ的区别 6. Nginx的应用场景,你是如何使用的。 7. 阿里云对象存储的应用场景,讲一下对象存储是什么(他们服务器可能会做这个所以问的这个) 8. 常见的关系型数据库
-
 即构科技 前端实习岗面试
即构科技 前端实习岗面试9月4号下午2点半开始面的,面完后hr加微信5点约hr面,一天面完2次,整体感觉很不错,公司的技术路线很符合自己的技术栈发展;和面试官,hr聊的也很融洽,第一次感觉到原来面试也可以嘻嘻哈哈的,之前都是一本正经的谈技术问题,这次真的就和朋友聊天一样很自然 分享一下面试的问题: 面试官介绍公司和部门业务(api,sdk之类的文档编写) 自我介绍 对api的理解,知道restful API吗? 用过什么
-
 淘天-丰富性技术-前端一面
淘天-丰富性技术-前端一面为什么要定义React hooks,这个对比直接定义函数有什么优点? 如何搭建一个组件库,组件库要如何设计 如何使用Jest进行测试 如果要对一个网页进行单元测试,要如何进行设计 如果要给一个项目添加单元测试要如何保证单元测试的效率 最近有使用大模型技术吗? 如何结合大模型来进行单元测试,实现自动化测试 如何通过大模型实现从PRD转换为目标代码?有那些流程和优点缺点?如何解决缺点提供代码稳定 We
-
 联芸科技 嵌入式软件 面经
联芸科技 嵌入式软件 面经一面: 1、先是大概问一下项目 2、static原理,static全局变量没有初始化时,读取到的值(0,因为bss段) 3、bss段怎么初始化的 4、栈 5、malloc原理,操作系统堆内存 6、编译器的expect unlike关键字(这俩我真不懂) 7、cache原理与多级cache结构,高速缓存行的结构,缓存一致性问题,汇编中的cache flush指令 8、cpu多级流水,分支预测原理以及
-
 紫光云技术支持实习面经
紫光云技术支持实习面经总体流程比较轻松,面试官全程鼓励(重点是不开摄像头) 1.自我介绍 我提到了希望以后发展成云计算或者大数据方面的工程师,面试官说这是运维岗,不是开发岗,问问我的意见,我说运维和开发其实是相辅相成的(主要是暴露野心了试图原场) 2.Linux命令简单考察 3.实习地点北京是否同意 我追问有无住宿提供,无 4.实习周期一年是否愿意 倒贴一年谁愿意,还是运维岗(我们老师强烈避坑的岗位)😢(由于是硬性要
-
 迪普科技C开发实习一面
迪普科技C开发实习一面6/25公众号投递 7/1笔试,13选择,两代码分析填空,两算法 7/8突然电话面试,20min 自我介绍 平时有什么兴趣爱好 杭州可以吗? 研究生论文弄好了吗? 学的是自学的吗? 了解过我们公司做什么的吗?(Linux内核网络相关) 平常C多还是C++多? 基础 GCC编译过程?链接在做什么? include< >和include“ ”区别 变量有符号和无符号的区别? int的数据范围。 有符号
-
 顺丰科技——2024暑期实习面试
顺丰科技——2024暑期实习面试岗位:机器学习算法工程师 一面: 1.自我介绍 2.线程和进程的区别,什么时候用多进程,什么时候用多线程(这个属于给自挖坑了) 3.实习项目问题,项目目标是怎么定的,用的什么算法,算法原理是什么(这个算法偏控制论) 4.比赛问题:xgboost原理,特征怎么构造的,怎么选择的 5.有没有了解transform方面的(可惜我对nlp接触的太少) 6.课题问题:这个偏简单数据分析,都没啥建模,没说很多
-
 零跑科技测试工程师面经
零跑科技测试工程师面经这家公司面试总共 3 轮,技术面两轮,第一轮电话面,第二轮线下主管面,最后HR面。 技术面难度还可以,问的比较细,主要是根据你简历上面的项目进行提问和深挖,如果都是你自己老老实实做过的东西,一般都是答得上来的。后面会根据你的项目问一些延伸问题,对某某部分有了解吗?然后会问一些相关问题,主要考察一下你掌握的深度,回答不出来也没什么关系。 总体面试体验感还是不错的,面试官很亲切,很nice。
-
 参数技术苏州分公司面经
参数技术苏州分公司面经双非本双非硕研一软件工程学硕在读,小论文基本搞定了所以想找暑期实习,投了其他大概四五家都没声音,这家公司基本是秒回。 hr处理非常快,第一天下午投的秒查看,第二天一早就给我打电话,安排我面试,工作内容基本也就是开发协助吧,一天200早八晚五或者早九晚六。现在看来感觉就是hr刷kpi。 投递的岗位要求是:1,计算机相关专业在读。2,有关系型数据库经验。 *加分项是会java,c# 。会jira和会g
-
Elasticsearch集群'master_not_discovered_exception'
问题内容: 我已经安装了Elasticsearch 2.2.3并在2个节点的集群中进行了配置 节点1(elasticsearch.yml) 节点2(elasticsearch.yml) 如果我知道我有: 进入节点1的日志有: 改为进入节点2的日志: 哪里出错? 问题答案: 我解决了这一行: 每个配置文件的主机名都必须带有此行
-
Elasticsearch集群API
此API用于获取有关集群及其节点的信息,并对其进行更改。 对于调用此API,需要指定节点名称,地址或。 例如, 或者 响应 集群运行状况 此API用于通过追加关键字来获取集群运行状况的状态。 例如, 响应 集群状态 此API用于通过附加’‘关键字URL来获取有关集群的状态信息。状态信息包含:版本,主节点,其他节点,路由表,元数据和块。 例如, 响应 群集统计信息 此API有助于使用’‘关键字检索有
-
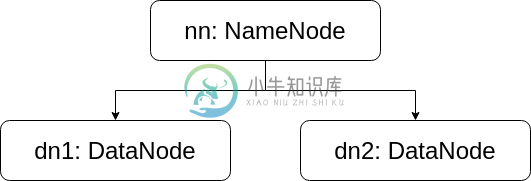 5.0 HDFS 集群
5.0 HDFS 集群主要内容:部署集群HDFS 集群是建立在 Hadoop 集群之上的,由于 HDFS 是 Hadoop 最主要的守护进程,所以 HDFS 集群的配置过程是 Hadoop 集群配置过程的代表。 使用 Docker 可以更加方便地、高效地构建出一个集群环境。 每台计算机中的配置 Hadoop 如何配置集群、不同的计算机里又应该有怎样的配置,这些问题是在学习中产生的。本章的配置中将会提供一个典型的示例,但 Hadoop 复
-
群聚法 Clustering
EX 12:Spectral clustering for image segmentation
-
Weblogic 12c群集
消息图标-警告所有选定的服务器当前处于与此操作不兼容的状态,或者与正在运行的节点管理器无关,或者您无权执行请求的操作。不会执行任何操作。