《大数据研发实习》专题
-
 美团数据运营实习面经
美团数据运营实习面经👥 面试题目 美团数据运营实习生面经(已offer): 这个实习是在实习僧上投递的,前面一直在忙校招等等的 这个面试当时面完没写笔记,现在凭回忆写写吧 1.自我介绍 2.面试官介绍自己部门的业务情况(优选-零售) 3.一句话概括自己的优势 4.我对零售业务的理解?是不是自己想做的? 5.讲一个自己做过的数分的案例 6.确认了一下到岗时间,可实习时长这些 7.SQL掌握情况如何 这轮面试是电话面试
-
 快手数据分析实习(凉经)
快手数据分析实习(凉经)👥 面试题目 投递渠道:实习僧,方向:电商的用户增长 下面就是面试问题啦: 1.基本工作情况确认(时间,时长) 2.现场手撕代码(这部分花的久):用户信息、用户行为两个表 问题一:筛选四月日活跃用户,不同性别groupby 问题二:筛选次日留存用户(前一日活跃、后一日也活跃) 3.问我对电商的理解 4.反问:我问了此岗位对于电商的工作内容,编程和业务的占比 面试感受:很直,对简历没有深挖,直接上
-
 字节商业化用户研究(实习面经)
字节商业化用户研究(实习面经)一面/mentor面 1、自我介绍,因为我本身是社会学和岗位比较匹配,所以特别强调了自己学到的工具和有过类似经历 2、围绕过往经历中和定性/定量分析的项目进行提问,我的回答中提到了对一份问卷的设计、处理数据的工具、数据分析的思路、以及最后的结果。 3、什么是商业化? 4、平时用字节的什么产品?追问在抖音上主要会刷些什么? 5、对于字节的工作强度会有什么concern吗? 6、觉得自己的性格是什么样
-
php实现通用的从数据库表读取数据到数组的函数实例
本文向大家介绍php实现通用的从数据库表读取数据到数组的函数实例,包括了php实现通用的从数据库表读取数据到数组的函数实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了php实现通用的从数据库表读取数据到数组的函数。分享给大家供大家参考。具体分析如下: 此函数不关心表结构,只需要指定表名、结构和查询条件既可以对表进行通用查询操作,非常实用。 希望本文所述对大家的php程序设计有所帮助。
-
如何定期从firebase实时数据库中获取数据。或提取数据并将其显示为实时数据
我是编程新手,我开始使用Ionic框架构建应用程序作为体验。我目前正在学习构建一个基本的社交媒体应用程序,匿名用户可以在该平台上发帖。 我现在处于用户可以评论帖子的阶段。但是,我很难在视图上显示每个帖子的实时评论数。 我计算评论的方法是从Firebase获取帖子数据,计算评论数量,然后显示给视图。 我尝试过使用间隔来每隔x秒获取post数据,以刷新post数据。这有点可行,但问题是离子内容(视图)
-
SQL Server数据库删除数据集中重复数据实例讲解
本文向大家介绍SQL Server数据库删除数据集中重复数据实例讲解,包括了SQL Server数据库删除数据集中重复数据实例讲解的使用技巧和注意事项,需要的朋友参考一下 SQL Server数据库操作中,有时对于表中的结果集,满足一定规则我们则认为是重复数据,而这些重复数据需要删除。如何删除呢?本文我们通过一个例子来加以说明。 例子如下: 如下只要companyName,invoiceNumbe
-
 经纬恒润数据事业部数据分析实习生面试
经纬恒润数据事业部数据分析实习生面试一位面试官,大概40分钟,只有一面 1.确认实习时间,什么时候开始实习,能做多长时间 2.自我介绍 3.面试官介绍了他们的四个方向 4.介绍项目,具体怎么做的包括了数据预处理,模型等 5.不用内置函数怎么算根号二,比如保留小数点后16位,想了半天,说了两种方法,说完第一种方法后面试官问还有没有其他的方法,说了第二种方法后面试官问还有没有其他的方法,没回答上来 6.田字格或九宫格从左上角到右上角不走
-
 26java实习,发发面经
26java实习,发发面经刚开始面,很容易紧张。不过运气都比较好,前两个都给发offer了 中秋节过后还有个字节的一面,虽然可能是kpi面,但还得好好准备一波。我基础还是太差了😔
-
 python数据库开发之MongoDB安装及Python3操作MongoDB数据库详细方法与实例
python数据库开发之MongoDB安装及Python3操作MongoDB数据库详细方法与实例本文向大家介绍python数据库开发之MongoDB安装及Python3操作MongoDB数据库详细方法与实例,包括了python数据库开发之MongoDB安装及Python3操作MongoDB数据库详细方法与实例的使用技巧和注意事项,需要的朋友参考一下 MongoDB简介 MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。 在高负载的情况下,添加更多的节点,可以保证
-
如何将大熊猫的每月数据转换为季度数据
问题内容: 我有月度数据。我想将其转换为1月份从1月份开始的3个月的“期间”。因此,在下面的示例中,前三个月的汇总将转换为q2的开始(所需格式:1996q2)。而将三个月度值汇总在一起而得出的数据值是三列的平均值。从概念上讲,并不复杂。有谁知道如何一口气做到这一点?潜在地,我可以通过循环来做很多艰苦的工作,并从中进行硬编码,但是我是熊猫的新手,正在寻找比暴力更聪明的东西。 所以我在寻找: 问题答案
-
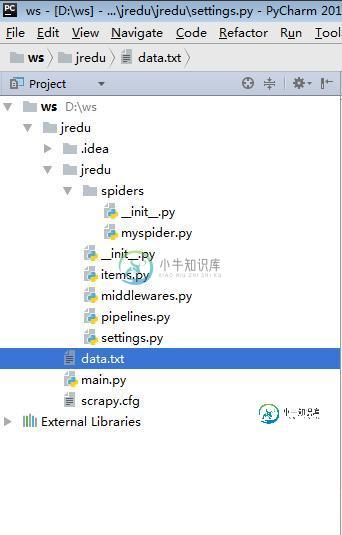 Python大数据之从网页上爬取数据的方法详解
Python大数据之从网页上爬取数据的方法详解本文向大家介绍Python大数据之从网页上爬取数据的方法详解,包括了Python大数据之从网页上爬取数据的方法详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python大数据之从网页上爬取数据的方法。分享给大家供大家参考,具体如下: myspider.py : items.py : middlewares.py : pipelines.py : settings.py
-
将大型本地数据库与服务器数据库同步(MySQL)
问题内容: 我需要每周将一个大型(3GB + / 40+个表)本地MySQL数据库同步到服务器数据库。这两个数据库完全相同。本地数据库会不断更新,每周大约需要用本地数据更新服务器数据库。您可以将其称为“镜像数据库”或“主服务器/主服务器”,但是我不确定这是否正确。 现在,数据库仅在本地存在。所以: 1)首先,我需要将数据库从本地复制到服务器。由于数据库大小和PHPMyAdmin的限制,使用PHPM
-
在其他数据框中查找最近点(包含大量数据)
问题很简单,我有两个数据帧: > 一个有90000套公寓和他们的经纬度 还有一个有3000个药房和他们的经纬度 我想为我所有的公寓创建一个新变量:“最近药房的距离” 为此,我尝试了两种花费大量时间的方法: 第一种方法:我创建了一个矩阵,我的公寓排成一行,我的药店排成一列,它们之间的距离在交叉点上,然后我只取矩阵的最小值,得到一个90000值的列向量 我只是用了一个双人床来搭配numpy: ps:我
-
pytorch下大型数据集(大型图片)的导入方式
本文向大家介绍pytorch下大型数据集(大型图片)的导入方式,包括了pytorch下大型数据集(大型图片)的导入方式的使用技巧和注意事项,需要的朋友参考一下 使用torch.utils.data.Dataset类 处理图片数据时, 1. 我们需要定义三个基本的函数,以下是基本流程 这里,我将 读取图片 的步骤 放到 __getitem__ ,是因为 这样放的话,对内存的要求会降低很多,我们只是将
-
弹性搜索未提供大量的页面大小数据
问题内容: 要获取的数据大小:大约20,000 问题:在python中使用以下命令搜索Elastic Search索引数据 但没有得到任何结果。 如果我给的尺寸小于或等于10,000,则可以正常工作,但不能与20,000相匹配, 请帮助我找到最佳的解决方案。 PS:在深入研究ES时发现此消息错误: 结果窗口太大,从+大小必须小于或等于:[10000],但为[19999]。有关请求大数据集的更有效方