《数据研发工程师》专题
-
利用“写时复制”功能将数据复制到Multiprocessing.Pool()工作进程
问题内容: 我有一些看起来像这样的Python代码: 在阅读了有关内存在其他StackOverflow答案中的工作方式的答案(例如该Python多处理内存使用情况)后,我的印象是,这种内存使用方式与我用于多处理的进程数量成比例,因为它是写时复制和我尚未修改的任何属性。但是,运行顶部时,我确实会看到所有进程的高内存,它表示我的大多数进程正在使用大量内存(这是OSX的最高输出,但是我可以在Linux上
-
是否可以使用节点工作线程执行数据库插入?
我最近读到了Node的“worker_threads”模块,该模块允许在多个线程中并行执行Javascript代码,这对于CPU密集型操作非常有用。(注意:这些不是Chrome在浏览器中制作的web Worker) 我正在构建一个功能,我需要在不阻塞浏览器的情况下执行大量的Postgres INSERT。 问题是:在我实例化worker的Javascript文件中,不允许导入任何内容,包括本机节点
-
425无法打开我的程序上的数据连接,而Filezilla工作
我尝试制作一个FTP客户端,它在活动模式下上传一个文件(C和linux的socket库)。当我想在本地服务器(LAN)上发送文件时,我的程序工作,但当我想在远程服务器(WAN)上发送文件时,它不工作。我有一个错误425无法打开数据连接。我做了很多研究,通常这个问题来自NAT(它可能会阻塞数据连接端口)。但是我试过使用Filezilla(在活动模式下),它成功了。所以我没有发现数据连接的问题在哪里。
-
数据绑定在AngularJS中如何工作?
问题内容: 数据绑定在框架中如何工作? 我尚未在其网站上找到技术细节。数据从视图传播到模型时,或多或少地清楚了它是如何工作的。但是,AngularJS如何在没有设置者和获取者的情况下跟踪模型属性的变化? 我发现有些JavaScript观察程序可以完成这项工作。但是Internet Explorer 6和Internet Explorer 7不支持它们。那么AngularJS如何知道我更改了以下内容
-
primeface 3.2可数据incell编辑不工作
我有一个带有incell编辑的数据表,它可以正确显示记录,但当我尝试编辑一行时,更改不会反映出来。以下是xhtml代码: 以下是托管bean函数: 或者,我也尝试了:
-
CAS数据库身份验证不工作
继续我先前的问题。我正在研究CAS 5,以便根据需要进行修改。在CAS教程的帮助下,我现在已经完成了自定义身份验证。现在,我向pom添加了以下依赖项。xml,通过以下链接连接到数据库。 并在应用程序中添加了数据库身份验证属性。属性 但这不起作用意味着 类型org.apereo.cas.configuration.model.support.jdbc.QueryJdbcAuthentiationPr
-
数据表ajax。重载()和。clear()不工作
我有一个标签部分创建与引导3.对于其中一个选项卡,选项卡内容是可数据的。数据在服务器端生成,在初始负载下工作正常。但是,我试图在onChange函数内部使用ajax.reload(),并且数据不刷新。我也尝试过使用Clear()方法,但是数据没有被清除。我已经验证了函数正在启动,并且返回的AJAX响应是有效的JSON,而不是空的。我的控制台没有错误,只是什么都没发生。 我使用的是Datatable
-
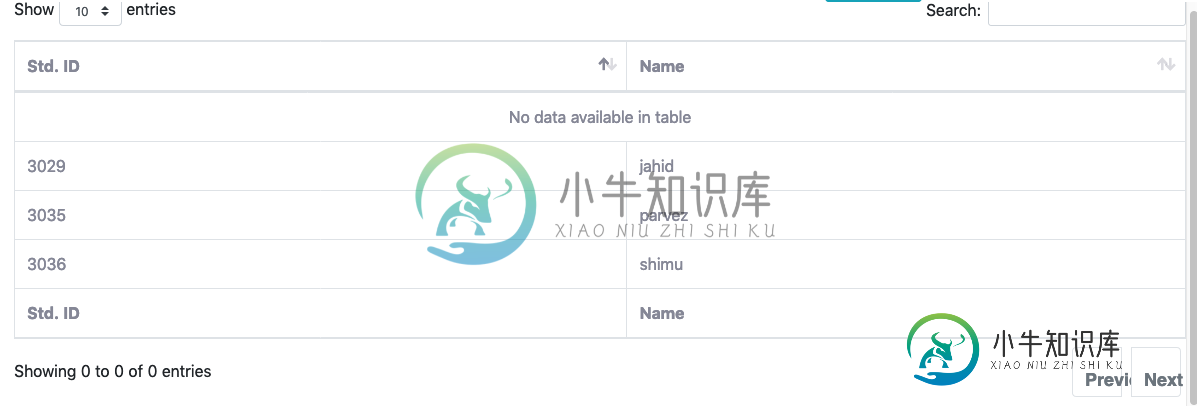 bootstrap4数据表搜索选项不工作
bootstrap4数据表搜索选项不工作我使用bootstrap4数据表来显示行限制 > HTML代码 Ajax填充代码 Onload我使用了下面的代码 我用过bellow js
-
Spring云数据流DLQ配置不工作
我正在尝试在Spring云数据流中配置DLQ。下面是流定义以及我如何部署它 在自定义转换处理器代码中,我已经提到过 这意味着若消息包含错误,那个么RunTimeException和我想在DLQ中捕获这些消息。但当我运行代码时,似乎没有得到任何名为test tran的Kafka DL队列。 我是否需要设置更多属性来启用DLQ,还是需要更改代码中的某些内容以正确使用DLQ。 自定义转换代码 Trans
-
搜索(免费)数据库迁移工具
问题内容: 我正在寻找一种工具来将包含DDL和内容的数据库转储为纯SQL- Sript,以便可以将其以纯文本格式存档。我知道例如Oracle转储工具或MySQL转储,但是是否有一个工具可以连接到不同的数据源并完成工作?GUI会很棒。 问题答案: 查看http://squirrel-sql.sourceforge.net/。Gui,跨平台,并使用jdbc驱动程序支持任何数据库。
-
使用熊猫的“大数据”工作流
在学习熊猫的过程中,我已经尝试了好几个月来找出这个问题的答案。我在日常工作中使用SAS,这是非常好的,因为它提供了非核心支持。然而,SAS作为一个软件是可怕的,原因还有很多。 有一天,我希望用python和pandas取代SAS的使用,但我目前缺乏大型数据集的核心外工作流。我说的不是需要分布式网络的“大数据”,而是文件太大而无法放入内存,但又太小而无法装入硬盘。 我的第一个想法是使用将大型数据集保
-
芹菜工作者数据库连接池
我使用芹菜独立(不在Django内)。我计划在多台物理机器上运行一种辅助任务类型。该任务执行以下操作 接受XML文档。 转换它。 进行多个数据库读写 我正在使用PostgreSQL,但这同样适用于使用连接的其他存储类型。过去,我使用数据库连接池来避免在每次请求时创建新的数据库连接,或者避免连接打开时间过长。然而,由于每个芹菜工人都在一个单独的过程中运行,我不确定他们实际上如何能够共享游泳池。我是不
-
熊猫当月工作日股价数据
上面的问题是假设一周有7天。它试图计算每周有7天。我的数据是由(工作日)每日价格组成的,有时可能会因为市场因假期关闭而错过一周的几天。 我的问题是如何找到给定日期的一个月中的一周。注:我突出了“给定日期”,因为这个过程每天都在处理,所以任何展望到月底的答案都可能不起作用。 我的尝试是向前看,但不是最佳的: 如果你发现这个问题有任何问题,或者它是重复的,请告诉我。我已经寻找了一段时间的解决办法。
-
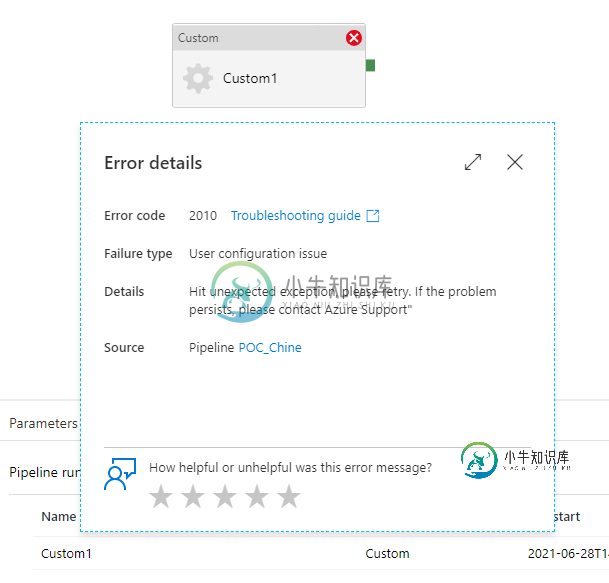 Azure数据工厂-批处理帐户-BlobAccessDenied
Azure数据工厂-批处理帐户-BlobAccessDenied我试图使用数据工厂中的自定义活动在批处理帐户池中执行存储在Blob存储中的python批处理。 我学习了微软教程https://docs.microsoft.com/en-us/azure/batch/tutorial-run-python-batch-azure-data-factory 根据执行情况,它发生在所有ADF参考文件上,也发生在我的批处理文件上。 我是新手,不知道该怎么解决这个问题。
-
Spring数据映射不按预期工作
我有一个具有两个外键和多对一关联(到表、检查点和设置)的表选项:db Schema。 完整堆栈跟踪是: org.springframework.dao.DataIntegrityViolationException:不能执行语句;SQL[N/A];约束[null];嵌套异常是org.hibernate.exception.constraintViolationException:在org.spri