《数据分析面试》专题
-
 百度大数据一面
百度大数据一面4.27 1h B2B,百度电商部门 介绍完自己直接开始写算法题 随机数据的峰值,如 1 2 3 6 5 8 7,返回 6 或 8都行,要求时间复杂度O(lgN) 斐波那契数列,要求时间复杂度O(lgN),矩阵解法 求两个字符串的最长公共子串,如 abcedfgh 和 bcedgh 最长公共子串是bced 求两个字符串的最长公共子序列,如 abcedfgh 和 bcedgh 最长公共子序列是bce
-
如何将数据集分割/划分为训练和测试数据集,例如进行交叉验证?
问题内容: 将NumPy数组随机分为训练和测试/验证数据集的好方法是什么?与Matlab中的或函数类似。 问题答案: 如果要将数据集分成两半,可以使用,或者需要跟踪索引: 要么 有多种方法可以重复分区同一数据集以进行交叉验证。一种策略是从数据集中重复采样: 最后,sklearn包含几种交叉验证方法(k折,nave -n-out等)。它还包括更高级的“分层抽样”方法,这些方法创建了针对某些功能平衡的
-
MYSQL-将数据拆分为多行
问题内容: 我已使用从IMDB收集信息并将其传输到MYSQL数据库的应用程序导入了一些数据。 似乎这些字段尚未标准化,并且在1个字段中包含许多值 例如: 有没有办法将这些值分开,然后将它们插入到另一个表中,而不重复呢? 我进行了一些谷歌搜索,发现我应该使用PHP处理此数据。但是我一点都不了解PHP。 无论如何,仅使用MYSQL即可转换此数据? 问题答案: 您可以使用存储过程,该过程使用游标来解
-
 layui实现数据分页功能
layui实现数据分页功能本文向大家介绍layui实现数据分页功能,包括了layui实现数据分页功能的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了layui实现数据分页功能,供大家参考,具体内容如下 官网layui table演示页面 示例截图: 页面引入layui.css、 layui.js 前台js 业务逻辑层 sql 其中sql在计算总数totle时可以这么写 以上就是本文的全部内容,希望对大家的学习
-
ajax实现数据分页查询
本文向大家介绍ajax实现数据分页查询,包括了ajax实现数据分页查询的使用技巧和注意事项,需要的朋友参考一下 用ajax实现对数据库的查询以及对查询数据进行分页,供大家参考,具体内容如下 主页面代码 js代码 处理页面1 处理页面2 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
Django的计数和分组依据
问题内容: 我有一个看起来像这样的模型: 我想要为每个类别选择项目的计数(只是计数),因此在SQL中,它会像这样简单: 有没有相当于做这种“ Django方式”?还是纯SQL是唯一的选择?我熟悉Django中的count()方法,但是我看不出group by如何适合那里。 问题答案: 正如我刚刚发现的,这里是如何使用Django 1.1聚合API进行此操作:
-
将一列数据分成三列
我在excel中有一个列,其中包含名字、姓氏和职位名称的混合。唯一可以观察到的模式是——在每一组3行中,每第1行是名字,第2行是姓氏,第3行是工作标题。我想创建3个不同的列,并隔离此数据示例数据: 我想要:约翰,布什,经理,作为一行,分别放在名字,姓氏和职务下面的三个不同的栏中。像- 我们如何才能完成这项任务?
-
javascript数据类型示例分享
本文向大家介绍javascript数据类型示例分享,包括了javascript数据类型示例分享的使用技巧和注意事项,需要的朋友参考一下 前面我们介绍了javascript的数据类型,今天我们通过一些例子再来温故一下,希望大家能够达到知新的地步。 END 童鞋们是否对javascript的数据类型有了新的认识了呢,希望大家能够喜欢。
-
Spring数据可分页和LIMIT/OFFSET
我正在考虑将我们传统的jpa/道解决方案迁移到Spring Data。 但是,我们的前端之一是SmartGWT,它们的数据库组件仅使用限制/偏移逐步加载数据,这使得难以使用Pagable。 这会导致问题,因为无法确定限制/偏移量最终是否可以转换为页码。(这可能因用户滚动方式、屏幕大小等而异)。 我查看了切片等,但无法找到在任何地方使用限制/偏移值的方法。 想知道有没有人有什么建议?最理想的情况是,
-
数据分支和应用转换
我刚刚开始使用数据流,对于如何实现分支,我没有什么问题。
-
Cassandra中的数据重新分区
作为卡桑德拉数据分区的后续,我得到了vNodes的想法。感谢“西蒙·丰塔纳·奥斯卡森” 当我尝试使用vNodes进行数据分区时,我有几个问题, 我尝试观察2节点中的分区分布() 因此,根据我在两个节点中的观察,随着一个范围的扩展,节点61的值从-9207297847862311651到-9185516104965672922。。。 注意:分区范围从9039572936575206977到90199
-
属性的Spring数据Rest分页
我有两个使用分页和排序存储库定义的资源: 画廊/{id} 一般来说,这两种资源的分页都是根据使用的存储库类型提供的。 画廊本身包含一个图像列表 我现在可以通过 画廊/1/图片 是否也可以为这些子列表启用分页?或者,处理这些大列表的REST样式是什么。 事先谢谢你,圭多
-
火花数据帧范围分区
[新加入Spark]语言-Scala 根据文档,RangePartitioner对元素进行排序并将其划分为块,然后将块分发到不同的机器。下面的例子说明了它是如何工作的。 假设我们有一个数据框,有两列,一列(比如“a”)的连续值从1到1000。还有另一个数据帧具有相同的模式,但对应的列只有4个值30、250、500、900。(可以是任意值,从1到1000中随机选择) 如果我使用RangePartit
-
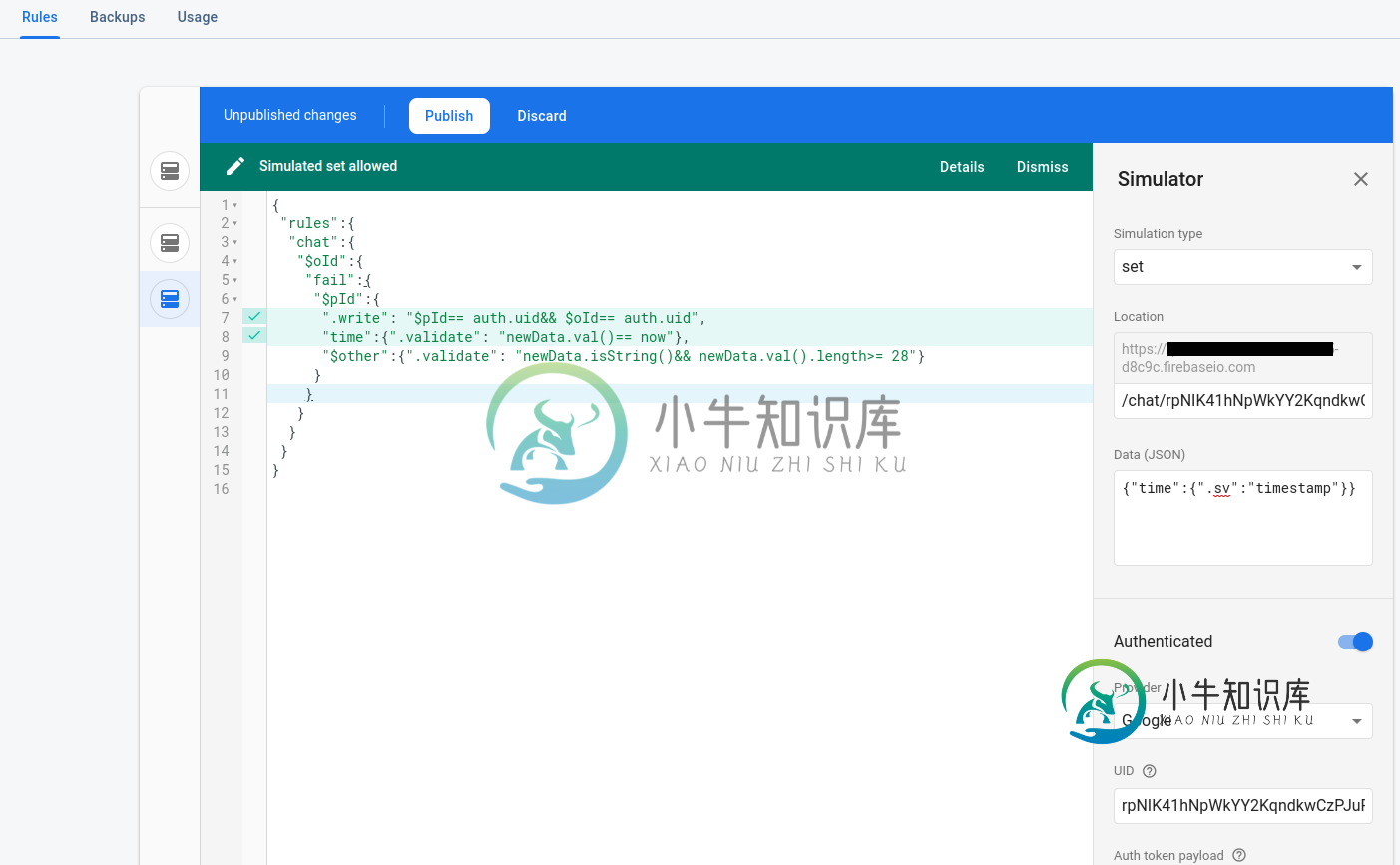 Firebase实时数据分片规则
Firebase实时数据分片规则更新2019-11-03:添加了错误的实时最小复制。在Chrome中加载链接后,点击ctrl shift i并选择控制台以查看输出。我已经尽力确保这正是我最初的项目代码所做的;我们看看情况是否如此,嗯?碎片的规则文件与下面的原始帖子相同。该源代码可在GitHub上获得。 原文: 这些规则在模拟器中工作,但在我真正的网络应用程序中不工作。模拟器路径和有效负载与下面数据库日志输出中显示的相同。 (将两
-
数据结构与算法 - 分治
分治和回溯其实本质上就是递归,只不过它是递归的其中一个细分类。可以认为 分治和回溯 最后就是 一种特殊的递归 或者是较为复杂的递归即可。 分治算法,即分而治之(divide and conquer,D&C),把 一个复杂问题 分成 两个或更多 的相同或相似 子问题,直到最后子问题可以简单地直接求解,最后将子问题的解合并为原问题的解。 分治法的核心思想就是,将原问题分解成小问题来求解,只要遵循三个步