《还愿》专题
-
什么使用更多内存,Class对象还是该类的实例?
我正在为餐馆提供的菜肴做模型。我可以做一个像这样的菜类: 关于内存使用,最好为每个盘创建盘的实例,<代码>盘。新(“咖喱鸡”,…) 为了澄清起见,ChickenCurry类将只包含一个构造函数,其中它设置了适当的字段,如下所示: 哪个使用更多的资源,还是?差异可以忽略不计吗?我计划拥有数千个这样的对象,因此即使是10 KB的差异也值得考虑。 我正在使用JRuby,所以在回答时请考虑JVM,但也欢迎
-
协议缓冲区(.proto)文件实现,效率不同还是相同?
在编写时。gRPC的原型文件我注意到我可以。 1)在一个. proto文件中包含我的所有消息(请求和响应)以及所有rpc。 2) 在各自的rpc中写入每个rpc。原型文件。 我可以看到,当我有两个访问相同消息的RPC时,在同一个文件中写入协议缓冲区会更方便。然而,我更愿意在可能的情况下将它们分开,以采用更模块化的方法。 我的问题是,忽略偏好这两种方法之间是否有效率差异?此外,如有任何关于本公约的信
-
我应该在服务器端还是客户端执行API请求?
我正在尝试使用ExpressJS和Coffeescript制作一个网络应用程序,它从亚马逊、LastFM和必应的网络应用程序接口中提取数据。 用户可以从特定乐队请求特定专辑的价格、即将到来的音乐会时间和乐队的位置等数据,等等...诸如此类的东西。 我的问题是:我应该使用和在客户端进行这些API调用,还是应该在服务器端进行?我已经完成了客户端请求;我如何从服务器端进行API调用 我只想知道最佳实践是
-
还在用if(obj!=null)做非空判断,带你快速上手Optional
本文向大家介绍还在用if(obj!=null)做非空判断,带你快速上手Optional,包括了还在用if(obj!=null)做非空判断,带你快速上手Optional的使用技巧和注意事项,需要的朋友参考一下 1.前言 相信不少小伙伴已经被java的NPE(Null Pointer Exception)所谓的空指针异常搞的头昏脑涨, 有大佬说过“防止 NPE,是程序员的基本修养。”但是修养归修养,也
-
使用工作流引擎、状态机引擎还是自己滚动?
我很困惑。我正在为我的公司开发一个基于grails的内部工具。此工具中的一个组件是简单的问题跟踪程序(帮助台功能)。我有一些领域对象,比如Problem、Question和NewFeature。每个域类都有不同的工作流。 我最初的想法是在域对象中滚动我自己的状态机功能。然后我在google上搜索状态机引擎和工作流引擎。现在我迷路了。 我想听听其他开发者是如何解决这个问题的。你使用Drools、Jb
-
我可以确定Java程序是使用Java还是JavaW启动的
问题内容: 这与另一个用户先前提出的问题有关,该问题询问如何在EclipseIDE中检测代码是否正在运行。 我注意到Eclipse总是使用而不是来启动程序。(这并不意味着启动的程序是从Eclipse启动的)。 我可以找到使用传递的参数 但这并不能告诉我它是使用还是启动的。 有没有办法找出它是使用还是启动的? 为什么Eclipse用于启动程序? 问题答案: System.console()将返回,因
-
如何从运行时构建的上下文中还原状态机?
问题内容: 我有一个状态机 我有一个模型,例如 Order 。模型保留在DB中。我从数据库中提取模型,现在我的模型处于状态。我想继续使用状态机处理模型,但是状态机的实例将以初始状态 DRAFT 开始处理,但是我需要从状态 INVITATION 继续处理。换句话说我要执行 并执行动作。我不想在DB中保留状态机的上下文。我想将stateMachine的状态设置为运行时模型的状态。我怎样才能正确地做到这
-
请问测试路由器怎么测,用命令行还是界面?
本文向大家介绍请问测试路由器怎么测,用命令行还是界面?相关面试题,主要包含被问及请问测试路由器怎么测,用命令行还是界面?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 可以采用lperf这个命令, Lperf是一个网络性能测试工具,可以测量最大tcp和udp带宽,具有多种参数和特性,可以记录带宽,延迟抖动,数据包丢失,通过这些信息可以发现网络问题,检查网络质量,定位网络瓶颈。 iperf的
-
Kafka 判断一个节点是否还活着有那两个条件?
本文向大家介绍Kafka 判断一个节点是否还活着有那两个条件?相关面试题,主要包含被问及Kafka 判断一个节点是否还活着有那两个条件?时的应答技巧和注意事项,需要的朋友参考一下 (1)节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每个节点的连 接 (2)如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太久
-
Dubbo默认使用什么注册中心,还有别的选择吗?
本文向大家介绍Dubbo默认使用什么注册中心,还有别的选择吗?相关面试题,主要包含被问及Dubbo默认使用什么注册中心,还有别的选择吗?时的应答技巧和注意事项,需要的朋友参考一下 推荐使用 Zookeeper 作为注册中心,还有 Redis、Multicast、Simple 注册中心,但不推荐。
-
如何确定数字在SQL Server中是浮点数还是整数?
问题内容: 我需要在sql server中编写以下查询: 请帮助我,谢谢。 问题答案:
-
 从Firebase存储访问文件还是从Firebase宿主访问文件?
从Firebase存储访问文件还是从Firebase宿主访问文件?以下是场景: 当我从Firebase存储访问文件时: 我从存储桶(.html、.png、.zip等)获取文件(小,但不超过2MB)。 将文件存储在我本地存储中,这样应用程序就不需要再次下载它,从而消耗服务器的带宽。 每次应用程序需要时从本地存储中使用它。 当我从Firebase宿主访问文件时: null 主持的优点:会更快。链接 PS: 1。我关心的是带宽而不是安全性。
-
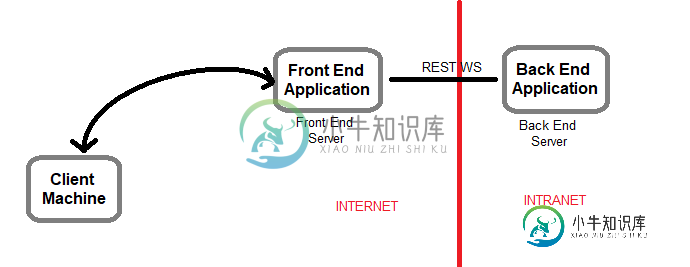 请求是从客户端到后端,还是从前端到后端?
请求是从客户端到后端,还是从前端到后端? -
Android Kotlin Room实体数据类应该是var、val还是不在乎?
我试图保持传统,这就是为什么我最近几天在一个Android项目中重构一些Kotlin代码的原因。我查看了许多Room实体数据类示例,但仍然没有获得在Room上下文中使用val/var的最佳实践。我认为合适的方法应该是val,因为它位于持久层,应该创建关于这些实体的DTO(数据传输对象),这些实体可以修改。有人能保证或否认这个假设吗!?
-
批量标准化:按维度固定样本还是不同样本?
当我读到一篇论文《批量规范化:通过减少内部协变量转移来加速深层网络训练》时,我想到了一些问题。 在报纸上,它说: 由于训练数据中的m个样本可以估计所有训练数据的均值和方差,因此我们使用小批量来训练批量归一化参数。 我的问题是: 他们是选择m个示例,然后同时拟合批次范数参数,还是为每个输入维度选择不同的m个示例集? E、 g.训练集由x(i)=(x1,x2,…,xn)组成:固定批次的n维,执行所有拟