《数据挖掘》专题
-
1.3.9 数据协作
在数据表格内,可以选择单条或者多条数据,进行分享协作,即指定给团队内没有该数据权限的人,进行操作 指定给某个成员后,数据表格新增一列属性“记录负责人” 该成员登录系统后,切换到该团队,即可看到此数据,可对数据进行编辑操作 具体步骤如下: 1.打开基础数据,点击某个图层名称,点击,展开图层列表,勾选数据。 2.点击“数据协作”,邀请协作人 3.两种方式搜索邀请成员: 输入手机号搜索,搜索完成后,点击
-
1.3.8 移动数据
勾选表格里数据,表格头部工具会有变化,点击 按钮,支持单条、批量数据移动; 注意: 移动后,数据将会以被移动到的目标图层为准,字段显示、样式都与目标图层保持一致
-
1.3.7 导出数据
勾选表格里数据,表格头部工具会有变化,点击按钮,支持批量、单条数据下载,导出Excel文件 注意: 网点表格,导出时需要选择坐标点的坐标系,Excel文件里不仅包括网点的属性信息,还有网点的坐标信息 区划表格,导出的Excel文件里只包含区划的属性信息,没有坐标点位置 线路表格,导出的Excel文件里只包含线路的属性信息,没有坐标点位置
-
1.3.6 删除数据
在数据表格里,勾选序号,表格头部工具会有变化,点击按钮,支持单条、批量数据的删除
-
1.3.5 统计数据
选择数据表格头部 图标,可以选择表格内数值型字段进行各种条件统计; 选择:选择本图层里数值型的字段名称 统计方式:选取求和、求平均数、求最大值、求最小值 点击“计算”后,统计结果在表格底部进行显示
-
1.3.4 筛选数据
选择数据表格头部 图标,可以选择表格内字段进行复杂条件筛选; 筛选结果在表格内显示; 选择: 选择图层内字段名称 约束条件: 对选择的该字段指定条件,条件一般有等于、小于、大于等(数值型字段)、或者包含、不包含等(文本型字段)... 约束值:输入需要限制的值 可以支持多种条件同时筛选、或者任选其一条件满足;
-
1.3 数据表格
属性字段增删改 字段内容不可重复 修改属性字段内容 筛选数据 统计数据 删除数据 导出数据 移动数据 数据协作
-
 歌尔大数据
歌尔大数据自我介绍 数仓分层 为什么分层 为什么建模 星型模型,雪花模型 数据库的三范式 范式建模和维度建模的区别,优缺点 如果给你一个任务,一个月完成,你怎么规划 反问 oc
-
 shopee数据开发
shopee数据开发刚刚oc了,有没有佬可以介绍下shopee food的情况,bp搜推算法 #shopee#
-
 Discover 数据分析
Discover 数据分析Discover数据分析一面 - Phone Interview - 全英文 手机开了自动拦截垃圾电话,前面几个电话没接到之后才反应过来关了。(被假中国海关的诈骗电话骚扰无数次) 1. 自我介绍 2. 最喜欢的课程,为什么? 3. 怎么知道Discover和这个工作的? 4. 有在信用卡领域的工作经验吗?(没有,只知道刷卡😂) 5. 对简历一个项目详细介绍 6. SQL where和group
-
 博世大数据
博世大数据一面 英文自我介绍 mr的shuffle zookeeper选举 spark内存管理 hbase中region的拆分 数仓中都有什么表 怎么处理缓慢变化维,拉链表有用过吗 yarn的架构 namenode ha的实现 namenode启动过程中怎么确定哪个是active哪个是standby spark sql用的多吗 手撕 中等leetcoode,合并区间 二面 自我介绍 家哪里的 对博世有什么了
-
 ZDNS大数据岗
ZDNS大数据岗一面:55min 0、自我介绍 1、介绍一下项目,一个离线,一个实时。离线Hive on Spark 实时:Flink + Kafka 2、Spark作业流程、Client,Cluster模式 3、Flink水位线,窗口,FlinkSQL,时间语义和SparkStreaming区别 4、Hive事实表、应用场景 5、实时项目怎么做的,FlinkSQL怎么用的 6、查找算法,排序算法有啥,说说冒泡,
-
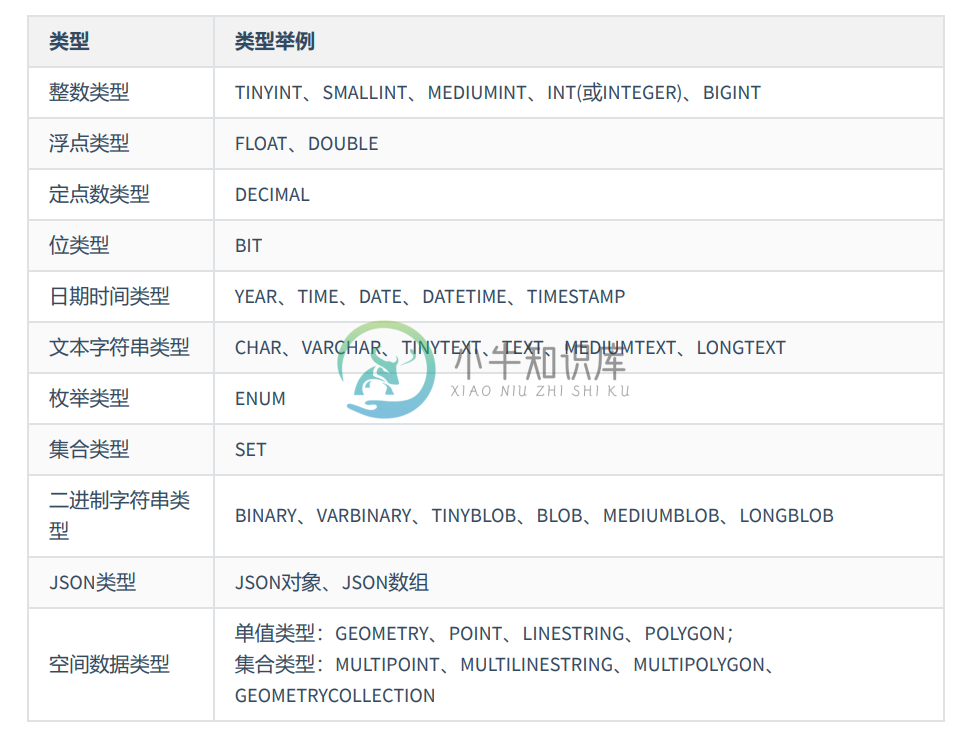 mysql数据类型
mysql数据类型主要内容:FLOAT和DOUBLE,浮点数与定点数,TIMESTAMP和DATETIME,char与varchar,BINARY与VARBINARY类型,BLOB类型1.整数类型 2.浮点类型 3.定点数 4.位类型:BIT 5.日期类型 6.文本字符串类型 7.TEXT类型 8.ENUM类型 9.SET类型 10.二进制字符串类型 11.JSON类型 1.整数类型 整数类型 大小 有符号范围 无符号范围 描述 TINYINT 1byte (-128,127) (0,255) 小整数值 SMAL
-
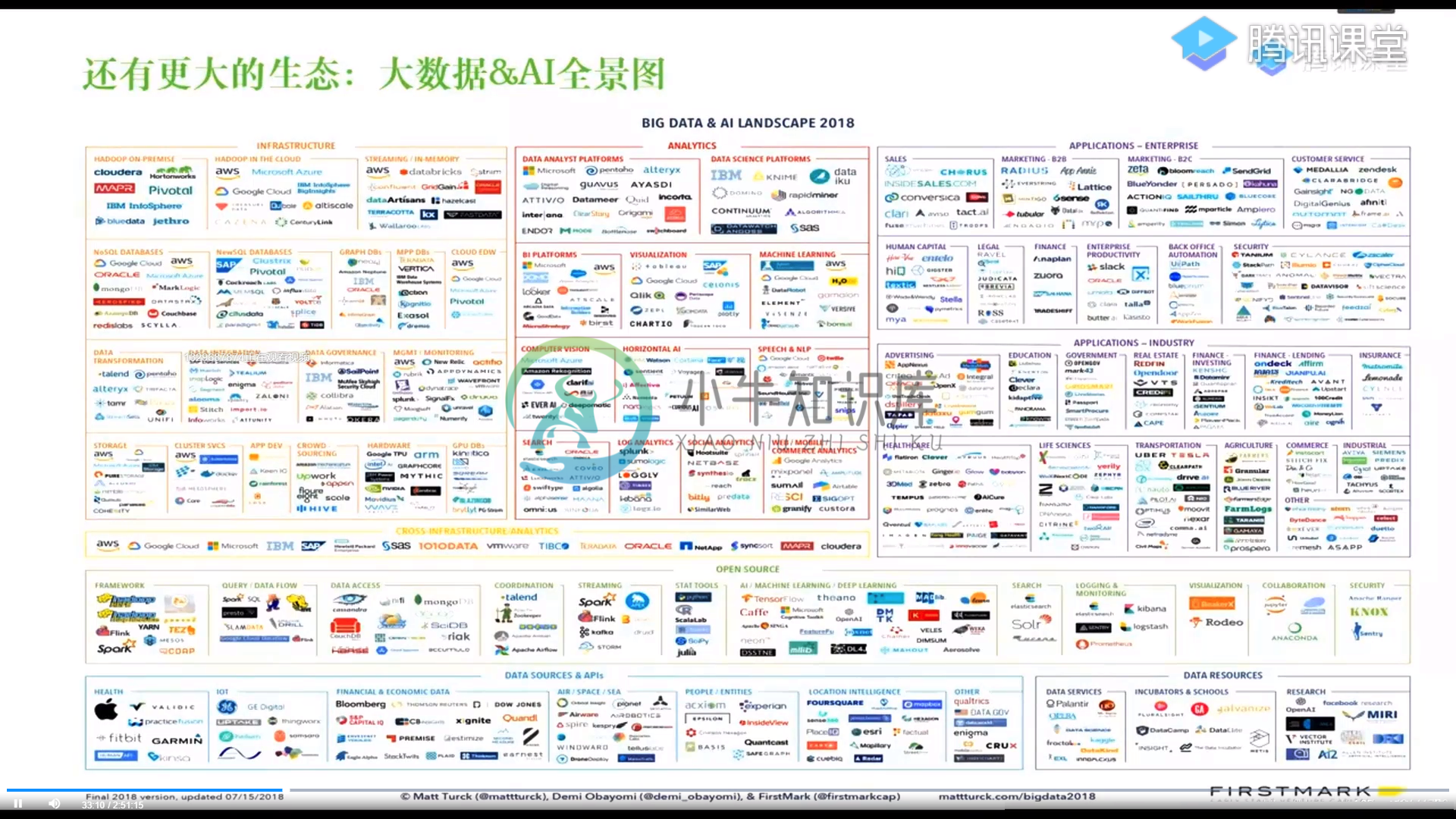 大数据生态
大数据生态fink生态 spark生态 hadoop生态 大数据技术体系与主流技术栈
-
大数据认证
2018年的20个主要的大数据认证 “大数据”一词反映了一个非常实际的增长趋势。到2020年,每个人每秒将产生1.7MB数据。根据调研机构IDC公司的调查,2020年全球数据量将增加到44万亿GB。数以亿计的智能手机和数十亿台物联网(IoT)设备每分钟产生的近300万个Facebook帖子和近300万个视频,每秒约有40,000次谷歌搜索查询。 而大数据认证的数量也在不断增加,尽管不尽相同。这些资