《大数据开发实习》专题
-
 2022/09/21 兴业数金 数据开发(已OC)
2022/09/21 兴业数金 数据开发(已OC)2022/08/01一面 25min 两个面试官 项目介绍一下 大数据比赛集群搭建过程 Hadoop端口号 有哪些配置文件 Hadoop切片 hive和关系型数据库区别 内部表外部表 项目中用的是外部表还是内部表 flink和spark区别 rdd是什么 spark stage怎么划分 spark分区数怎么确定 类加载机制 索引越多越好吗 lock和synchronize ------------
-
 2023秋招—数据开发面经—卓望数码
2023秋招—数据开发面经—卓望数码分享前吐槽:面试不开摄像头,面试官的语气跟快断气了一样…… 1、有了解web开发、后端开发吗?(无) 2、线程和进程有哪些区别? 3、怎么看一个正在执行的JAVA程序的线程状态? 4、新生代和老年代主要是干什么的?比例是多少? 5、HDFS的服务组成有哪些?它们分别的作用是什么? 6、除了Hive之外,还用过其他数仓吗? 7、Flink的窗口主要是干什么的? 8、Flink的dataStream和
-
 汇量科技数据平台开发实习一面二面HR面已offer
汇量科技数据平台开发实习一面二面HR面已offer本人大四研0。感觉这次面试是本人经历的面试以来最有难度的一次,Mobvista看网上风评很好,希望疫情赶紧好起来,我想去实习了。 11.02 一面(1h) 1.自我介绍 2.项目介绍 3.货拉拉实习工作 4.docker镜像分层以及核心原理 5.HBase预分区、rowkey设计原则 6.是否了解spark on k8s,说的不太懂k8s 7.描述下spark on yarn的任务调度流程(clu
-
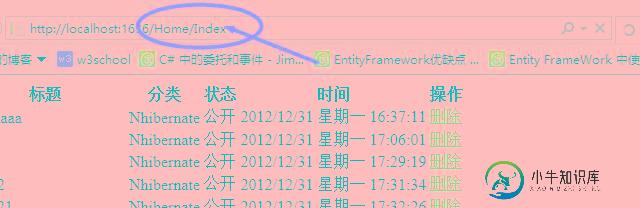 ASP.NET Mvc开发之删除修改数据
ASP.NET Mvc开发之删除修改数据本文向大家介绍ASP.NET Mvc开发之删除修改数据,包括了ASP.NET Mvc开发之删除修改数据的使用技巧和注意事项,需要的朋友参考一下 之前那篇文章介绍了ASP.NET MVC使用EF来查询数据和EF中DbQuery<T>泛型对象对数据的延迟加载。今天我们就来看看我们怎么使用EF来删除数据。 其实现在的Web开发通用的模式就是前端使用Js和JQuery来和后端进行数据交互。那么我们就在前端
-
Android开发中的持久数据存储
问题内容: 我是Java和Android开发的新手,我想问一下将数据存储到持久性存储的可用方法是什么?例如,我想在数据库或文件中存储字符串的集合。 请指教。谢谢。 问题答案: 正如您在问题本身中所说的那样,您可以使用文件或数据库。如果有更多数据,则可以使用文件和数据库(SQLITE);如果数据量较小,则也可以使用SharedPreferences。以下是其中所有链接的一个链接关于Android中的
-
socket.io发出数据将断开客户端
编辑:我设法把我的问题简化成一些非常简单的事情: 这段代码没问题: 这段代码断开了客户端的连接!:
-
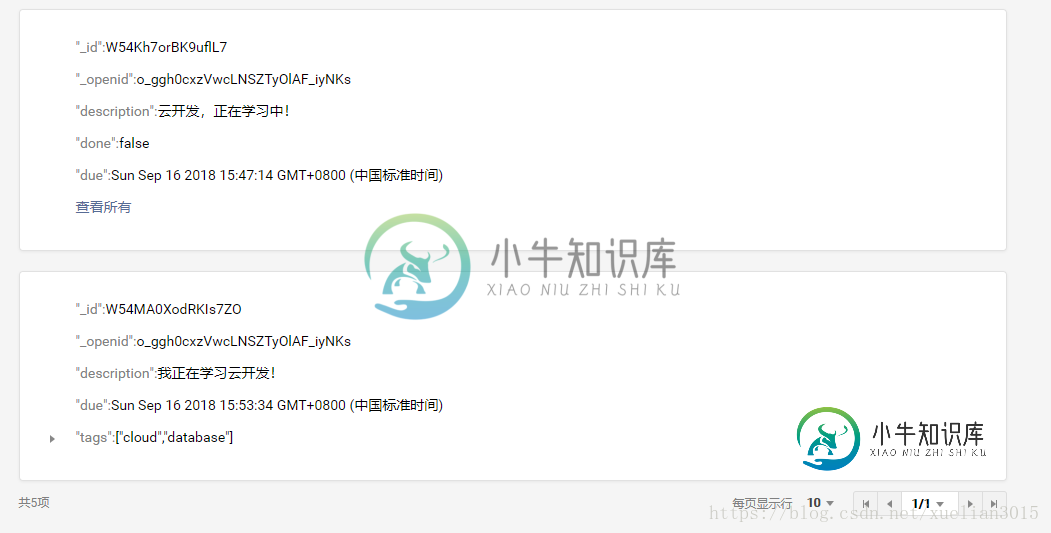 详解小程序云开发数据库
详解小程序云开发数据库本文向大家介绍详解小程序云开发数据库,包括了详解小程序云开发数据库的使用技巧和注意事项,需要的朋友参考一下 在云控制台操作云数据库,即创建数据库和插入数据等操作。 云开发数据库提供的数据类型:string、number、object、array、bool、GeoPoint(地理位置点)、Date(时间)、Null 其中的Date表示时间,精确到毫秒。小程序端用Javascript内置Date对象创
-
MongoDB同步开发和生产数据库
我们有一个包含对象集合的开发服务器。这些对象的实际积累是一个持续的过程,在这个本地开发服务器上运行标签、验证等的整个过程。一旦这些对象准备好生产,它们就会被添加到生产数据库中,从那时起,生产数据库将在其计算中使用它们。 我正在寻找一种简单地将增量(新对象)添加到生产数据库中的方法,同时将所有其他集合和旧对象保留在同一个集合中。到目前为止,我们一直使用MySql,所以这个过程只涉及运行数据库结构和数
-
 米哈游数据开发一面凉经
米哈游数据开发一面凉经我只记得这些了 一、java 1.String、StringBuffer、StringBuilder的区别;String为什么是不可变的字符序列?String类是final的吗? 2.java创建一个新对象的过程是什么样的?第一步是类加载器 3.java的垃圾回收机制 4.java的内存机制,方法区主要存的是什么? 5.hashmap的底层原理?使用链表的时候是头插还是尾插,为什么换为尾插了?什么
-
 9.14快手数据开发一面凉经
9.14快手数据开发一面凉经1.先自我介绍 2.然后介绍实习,之前的实习做的是离线数仓开发,聊的时候感觉面试官不懂数仓 3.那就做题吧 第一题 剑指 Offer 19. 正则表达式匹配,我知道是原题,也知道我面试必定做不出来,就直接说我不会 第二题 124. 二叉树中的最大路径和 ,虽然之前刷过,但完全不记得了,做的时候感觉完全是新题,直接中序遍历按最大连续子序列和的思路求了一个结果,面试官说是错的(当然事实上也确实是错的)
-
 浪潮 数据开发工程师 一面
浪潮 数据开发工程师 一面2022.10.14 10min 感觉自己被kpi了... 三个面试官 一个hr + 两个技术(其中一个全程在工作 没有看过摄像头) 1.自我介绍 2.你用过hadoop 说一下hadoop各组件干嘛用的 3.实时项目处理了多少数据 另一个技术没有问题 HR: 1.工作地点填写的全国怎么考虑的 2.应聘期望薪资 (看offershow给的挺低的,就随便报了个10k) 3.反问 哎 虽然面试很轻松
-
 2023秋招—数据开发面经—美的
2023秋招—数据开发面经—美的线下群面: 五分钟读题,然后每人简单自我介绍+说出对题目的答案,然后讨论20分钟,最后5分钟派一个人总结。 题目:(2选1) 1、如何构建数据中台? 2、设计一个智能家居,应该有哪些功能?用什么技术实现这些功能? 测评: 性格测试+图形推理+资料分析 二面: 1、自我介绍 2、详细介绍一下项目 3、实习的数据框架和项目的数据框架有什么区别吗? 4、数据采集还了解其他工具或架构吗? 5、数据加工处理
-
 美团23春招面经~数据开发
美团23春招面经~数据开发陆续分享点面经 虽然大部分都被挂了hh 希望能帮到大家 3.15 一面 1.自我介绍 2.题外话 怎么看待数仓和算法的联系 3.项目 4.介绍一下对大数据技术生态的了解 5. 怎么理解spark和hive 6.hive的逻辑架构 7.MR的流程 8.整个MR有几次排序 9.spark的shuffle 10.怎么确定spark分解成多少个task,即spark任务的并行度怎么指定 11.stage的
-
 得物 数据开发 kpi面13分钟
得物 数据开发 kpi面13分钟1.Java的数据结构相关 2.HashMap怎么解决哈希冲突的 3.HashMap和HashSet区别 4.Spark shuffle 5.Maven会用吗,怎么解决版本冲突? 6.实习相关 反问 做什么的?用什么? 偏底层,主要是做Spark和Flink底层的一些东西
-
二次开发 - 常用数据表说明
常用数据表说明: dede_archives|文档主表 dede_addonarticle|文章附加表 dede_addonimages|图片附加表 dede_addonshop|商品附加表 dede_addonsoft|软件附加表 dede_addonspec|专题附加表 dede_arctype|栏目表 dede_flink|友情链接表 dede_admin|系统管理用户表 dede_flin