《大数据开发实习》专题
-
 【字节提前批-大数据开发工程师-Data 一面】
【字节提前批-大数据开发工程师-Data 一面】【字节提前批-大数据开发工程师-Data 一面】 0 面试官自我介绍,介绍面试流程 有些奇怪的是 首先提到这个岗位不是xxx(记不清原话),偏向开发,询问是否能接受,当时我的理解是:可能这个岗位偏向大数据组件的开发,而我简历里没提及java,所以面试官想知道我是否还愿意继续面试该岗位? 随表示接受 1 自我介绍: 学校,专业,目前的实习单位和岗位,在校项目简述 2 对实习参与的项目的展开介绍:我实
-
 美的杭州研究院 大数据开发 一面面经
美的杭州研究院 大数据开发 一面面经面试时长 55min 一位很友善、技术水平很高的大哥 面试官自我介绍:来自美的数据库与大数据平台部门。主要做全集团的基础数据平台研发(分大数据平台,数据库平台两个方向)。Spark 部分快忘光了,正好趁这次机会复盘一下! 大数据相关: 面试官问:Hadoop 和 Spark的区别说一下? Hadoop的数据处理单位是block,Spark 提供了可供并行处理的数据抽象RDD Hadoop 对数据处
-
 2023秋招-大数据开发面试-阿里国际-一面
2023秋招-大数据开发面试-阿里国际-一面1、 确认专业,保研,成绩,排名 2、 课程内容,研究生课程等 3、 数据库底层索引的优劣势? 4、 我现在有一张表把所有字段都加索引了,这样好吗? 5、 存储过程和视图? 6、 视图字段是单独存储的吗? 7、 MR原理用你自己话简单描述。 8、 MR中数据倾斜的产生情况,你如何解决? 9、 一个复杂的SQL中发生了数据倾斜,你怎么确定是哪个group by还是join发生的? 10、 count
-
 2023秋招-大数据开发面试-阿里淘天-一面
2023秋招-大数据开发面试-阿里淘天-一面1、 是找大数据还是算法? 2、 对大数据领域的了解? 3、 从0-1建设数仓,你怎么做? 4、 数仓建设规范,依据? 5、 没想一块去,他想问建模思想之类的。维度、范式 6、 会哪些技术栈? 7、 Hadoop讲讲吧? 8、 为什么要有Hive,Hive作用? 9、 详细讲讲MR? 10、 数据倾斜发生的位置? 11、 Combiner了解吗? 12、 什么情况下不能用Combiner? 13、
-
 2023秋招-大数据开发面试-阿里淘天-二面
2023秋招-大数据开发面试-阿里淘天-二面1、 在XX实习,目前没有offer吗? 2、 实习和你项目的区别、实习项目主要做的内容? 3、 实习的难点? 4、 系统主要做的什么? 5、 讲讲MR? 6、 数据倾斜遇到过吗? 7、 除了null值呢? 8、 除了随机打散还有别的方案解决吗?
-
 腾讯社招(一面)面经;大数据开发工程师
腾讯社招(一面)面经;大数据开发工程师1. 请简述您如何理解腾讯的企业文化,并结合您的经验谈谈您如何融入这样的文化环境。 2. 在团队合作项目中,您通常扮演什么角色?请举例说明您如何在团队中发挥作用。 3. 描述一次您在项目中遇到困难或挑战的情况,以及您是如何解决问题的。 4. 请讲述一个您成功领导团队达成目标的经历,包括您采取的策略和最终结果。 5. 面对紧急且重要的任务时,您如何安排时间和资源以确保任务按时完成? 6. 请分享一个
-
 小米实习一面/盛泉恒元面试——数据开发
小米实习一面/盛泉恒元面试——数据开发早上去了盛泉恒元,公司感觉不错,小姐姐都很漂亮,基金公司没有想象中的西装革履,大家穿着都很随意。工作压力似乎也不大,就是面试有点狠,三个人审讯我,主管一顿说我项目不是企业实践的不行,太教科书。 我估计他们数据量小,数仓不需要分层那么多。不过嫌我数仓分层太多——太教科书就有点离谱了。还问我知不知道mr不用yarn,我寻思yarn那么好用,你为啥不用,你降级处理还要嫌我不实习实践所以不懂。然后告诉我就
-
 北京移动-IT开发与数据分析-暑期实习
北京移动-IT开发与数据分析-暑期实习1、自我介绍 2、自己的优点和缺点 3、兴趣爱好 4、社团经历 5、接受不接受转岗 个人感受:没意思,后悔说接受转岗了,另外就算面试时间不合适也可以直接换面试时间
-
 新中大科技实习 实施/二次开发面经 30min
新中大科技实习 实施/二次开发面经 30min三个人面试,leader、HR和技术组长,面试整体难度不大,偏向于基础 一 . 自我介绍 二 . Java 1.基本数据类型和引用数据类型 2.强制转换 3.i++和++i 4.说一下重载 5.顶级父类,Object类都有哪些方法 6.聊聊final关键字 7.形参和实参 8.==和equals 9.SpringBoot常用注解 10.说一下对前端了解多少(考JS) 三 . 数据库 1.结合项目,
-
 快手暑期实习二面6.15(数据平台-java开发实习生)
快手暑期实习二面6.15(数据平台-java开发实习生)1.问实验室和导师情况 2.HDFS架构 3.HDFS怎么保证数据一致性的 4.两个栈模拟链表 5.两阶跳台阶 6.n阶跳台阶 7.项目里面OOM遇到的问题和解决办法 8.Xms和Xmx参数大小限制,是否要一样 9.大数据下有没可能出现OOM的问题 反问 1.快手数据湖湖仓一体的情况 2.从头设计流引擎一般需要注意什么
-
 科大讯飞——大数据开发工程师(最汗流浃背的一集)
科大讯飞——大数据开发工程师(最汗流浃背的一集)面试内容 一面: 1、对那些数据库比较熟悉? 2、mysql优化? 3、数仓的架构,每一层的作用? 4、你做的项目中数据清洗放在哪一层? 5、数据怎么接入数仓的? 6、实时项目也做过?说一下flink处理数据的流程 7、任务断了,有重复数据怎么办?(我以flink为例说了怎么避免) 二面:不问技术 1、之前实习交过社保没? 2、从之前的上司那里学到了什么?只说一点 3、对未来的规划? 4、整体的实
-
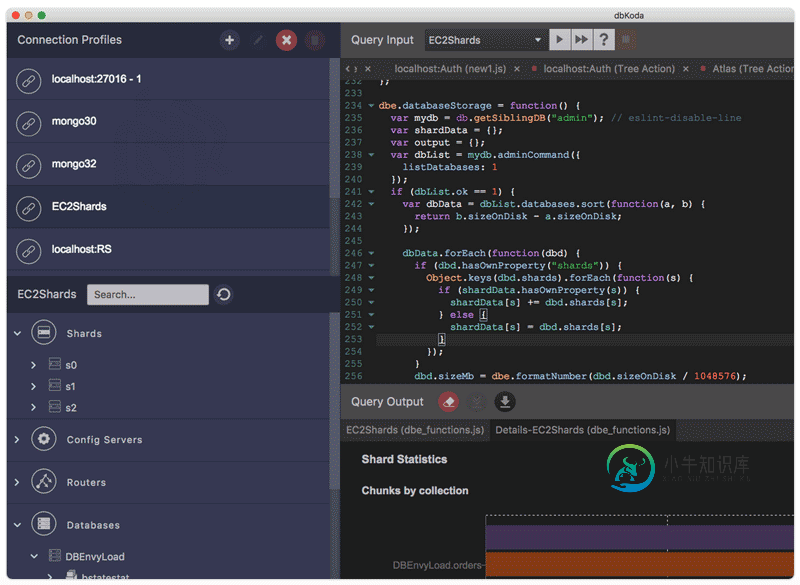 MongoDB开源数据库开发工具dbKoda
MongoDB开源数据库开发工具dbKoda本文向大家介绍MongoDB开源数据库开发工具dbKoda,包括了MongoDB开源数据库开发工具dbKoda的使用技巧和注意事项,需要的朋友参考一下 Southbank Software公司最近发布了 dbKoda 0.6.0 ,这是该软件的 首个发布版 。dbKoda是一款开源的 MongoDB 开发工具,采用JavaScript、 React 和 Electron 开发。下图显示了dbKod
-
 联通数科 一面 数据开发
联通数科 一面 数据开发昨天面的,三个面试官。 开始就是自我介绍。 1、第一个面试官问了问我一个数学建模的题目。我自己提了一嘴lstm,问了一下三个门 2、问了个sql题目,id不一样,邮箱有重复,怎么选出来,说用pandas也可以,问我pandas,不过我确实不常用pandas就没答出来 3、场景题,有通讯时间、地点、上网记录,如何判断哪些人是学生。 第二个问我懂不懂kafka、Hbase这些,我说不懂,就结束了。 感
-
 云智研发 数据开发 二面 35min
云智研发 数据开发 二面 35min1.自我介绍 2.项目细节介绍 3.针对一个指标讲讲你整个链路怎么设计的 4.数据交付时数据质量如何保证 5.如果现在调度的表都是高优先级,你这个表延迟产出了,怎么办 6.hive架构介绍 7.hive优化器会做什么,详细讲讲谓词下推 8.小文件产生原因,危害,解决方法 9.spark遇到的挑战 10.实时了解过吗 11.你们公司的数据链路,数仓分层是怎么样的 12.数据怎么采集的,binglog
-
大数据
Kubernetes community中已经有了一个Big data SIG,大家可以通过这个SIG了解kubernetes结合大数据的应用。 在Swarm、Mesos、kubernetes这三种流行的容器编排调度架构中,Mesos对于大数据应用支持是最好的,spark原生就是运行在mesos上的,当然也可以容器化运行在kubernetes上。当前在kubernetes上运行大数据应用主要是sp