《德州仪器》专题
-
无法解析类com。云蜂。哈德逊。插件。文件夹文件夹
我试图使用groovy脚本从jenkins收集数据并收到错误: 无法解析类com。云蜂。哈德逊。插件。文件夹文件夹 下面是代码: 错误是: rg.codehaus.groovy.control.MultipleCompilationErrorsExceptio n:启动失败: Script1.groovy: 12:无法解析类com.cloudbees.hudson.plugins.folder.文
-
如何解决构建中不同版本库的错误。格拉德尔?
我正在开发Android,并尝试实现GPS和谷歌地图。 构建。gradle(模块:app)如下所示 但它在编译com时显示了错误。Android支持:appcompat-v7:26' 。错误是 但是我在构建中没有看到任何版本25。gradle。我错过什么了吗?提前谢谢。
-
使用相同的GLTF模型两次在反应-三纤维/德瑞/Three.js
在这个最小反应三光纤应用程序中,我尝试加载并包含相同的GLTF型号两次: 看到这个代码沙盒了吗 然而只有第二个
-
Windows上Node.js+ibm_db+DB2 LUW 9.7的代码页问题(例如德文元音)
我们可以使用npm包IBM_DB从Widows客户端上的node.js成功访问IBM DB2 LUW Server9.7。 但是在ibm_db SQL查询的结果集中的chacarter编码确实存在问题。JavaScripte结果集中的数据在涉及德语元数时已经出现了错误。 我们还检查了数据库中的SQL列字符集: 给出结果1252。 其他徒劳的尝试: null Windows 10 node.js 1
-
我不能理解曼德布罗特分形代码的一些东西
这是计算功能代码。我听说“逃跑”应该是。因为如果()小于,它就不会无限大。但是在这个代码中,转义是。为什么?为什么?
-
朱莉娅·塞特和曼德尔布罗特·塞特是什么关系?
我写了一个mandelbrot集,我读过关于julia集的文章,它非常相似,但到底是什么关系呢?我能用mandelbrot公式画一个julia集吗?起始参数是什么?请阅读我的mandelbrot集合代码: 我不确定mandelbrot集对于z是迭代的,julia集对于c是迭代的,这意味着什么?我需要更改代码吗? 更新:我更改了代码,但它不起作用。我的想法是从$re和$im开始,而不是从0开始: 更
-
卡桑德拉:对时间序列数据时间戳的范围查询
我正在尝试评估Cassandra DB在存储和检索不同通道的时间序列数据方面的性能。 数据以文件格式记录,最大记录速率为8个样本/秒,每个样本都有一个以毫秒为单位的时间戳。给定时间记录的通道数可能会有所不同。 受以下链接的启发,我使用时间序列数据建模入门创建了以下表: 创建表uhhdata ( ch_idx int,date timestamp,dt timestamp,val float,PRI
-
时间序列数据的卡桑德拉:如何调整分区大小?
我正在尝试使用Cassandra来存储来自一些传感器的数据。我读了很多关于Cassandra的时间序列数据模型的文章。我从时间序列数据建模入门开始,“时间序列模式2”看起来是最好的方法。所以我创建了一个复制因子为2的键空间和一个这样的表 其中是唯一的设备ID,是一天(例如2017-08-30),是时间戳。 我的查询是 如您所见,我需要从多天中检索数据,这意味着在我的集群中读取多个分区。在我看来,查
-
卡珊德拉·CQL准备陈述的速度比没有准备的慢?
最近,我们对一些Cassandra集群进行了压力测试,比较了一致性级别、准备好的/未准备好的语句和同步/异步执行模式的所有组合的性能,在每种配置中,最高的性能总是异步运行的(任何/一个)未准备好的语句的组合!! 对于有意义的位,任何/一个一致性级别的限制都较少,因此应该是最快的。此外,异步运行查询,因此利用并行计算应该比按顺序运行它们更快,但是准备好的语句和非准备好的语句呢? 我们总是读到和听到(
-
卡桑德拉 节点发生故障时自动故障转移延迟
我是卡珊德拉的新成员。 我在两台 Debian VMware 机器上创建了 2 个 cassandra 2.1 节点。在 asp.net mvc 中,我使用了 datastax 驱动程序 2.1.5,实际上没有任何问题,但是当我关闭或禁用其中一个节点上的网络时,应用程序似乎有 5 或 10 秒的延迟来自动连接其他节点。 当两个节点启动时,查询在c00:00:00.0620413秒内运行,当一个节点
-
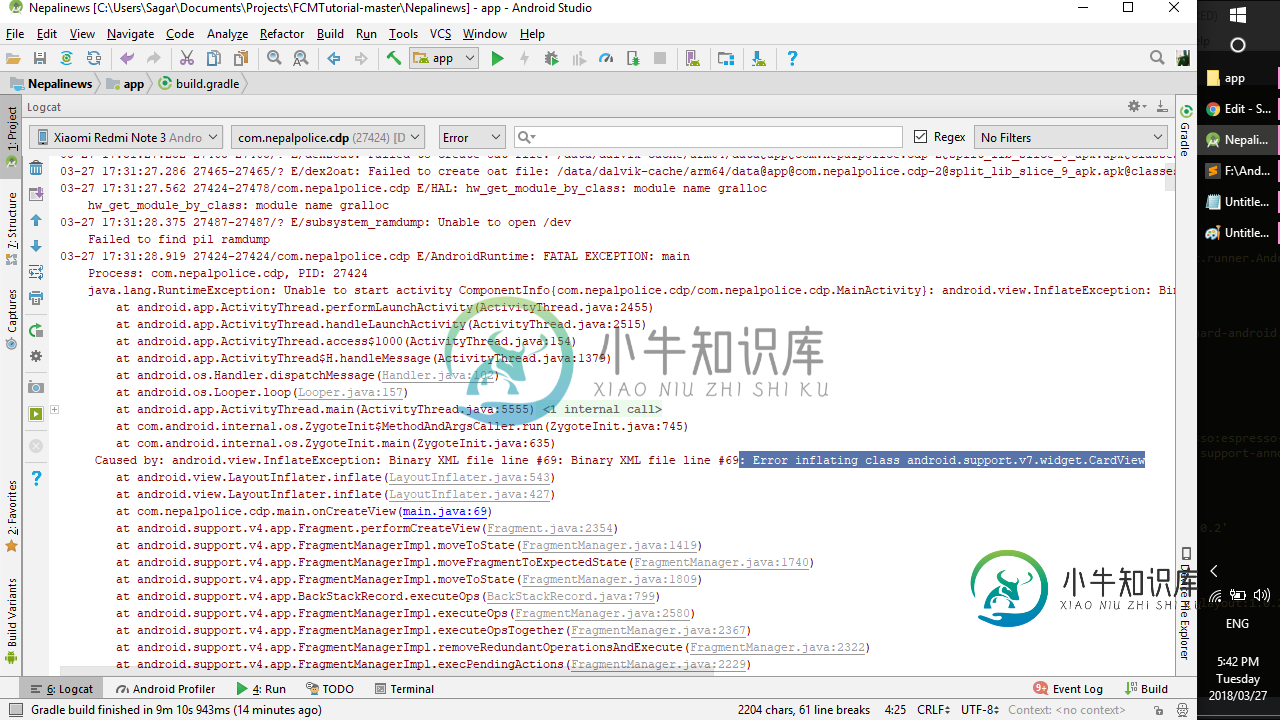 如何解决:错误inflating类android。支持v7。小装置。卡德维尤
如何解决:错误inflating类android。支持v7。小装置。卡德维尤我对这个错误感到非常沮丧。我完成了我的项目,并在我的Android 4.4.2版设备上运行,它成功运行,然后我成功上传到Playstore,并再次从Playstore安装,但它仍然运行良好。。。。。 但后来我收到了很多朋友的车祸报告。然后我借用了我朋友的Android6.0.1版设备,从Android Studio运行应用程序,在Splashactivity启动后,应用程序突然崩溃。Splasha
-
将Kafka Topic迁移到新集群(以及对德鲁伊特的影响)
我正在从Kafka的话题中摄取数据到德鲁伊。现在,我想将我的Kafka Topic迁移到新的KafkaCluster。在不重复数据和不停机的情况下,有哪些可能的方法可以做到这一点 我考虑了以下将Topic迁移到新Kafka集群的可能方法。 手动迁移: 在新的Kafka集群中创建具有相同配置的主题。 停止在Kafka集群中推送数据。 开始在新集群中推送数据。 停止从旧集群消耗。 从新集群开始消费。
-
为什么Python的模运算符(%)与欧几里德定义不匹配?
欧几里德的定义是, 给定两个整数a和b,其中≠ 存在唯一的整数q和r,使得a=bq r和0≤ R 根据以下观察,, 看起来运算符正在使用不同的规则运行。 link1没有帮助, link2给出了递归的答案,因为我不理解是如何工作的,所以很难理解是如何工作的 我的问题: 如何理解python中模运算符的行为?我不知道与操作员工作相关的任何其他语言。
-
复合分区和复合键会影响卡桑德拉的性能吗?
下面给出了3个表的CQL。两者具有相同的列结构,但在设置主键方面有所不同。 表1:没有复合主键 哪些设计具有更好的读/写性能?
-
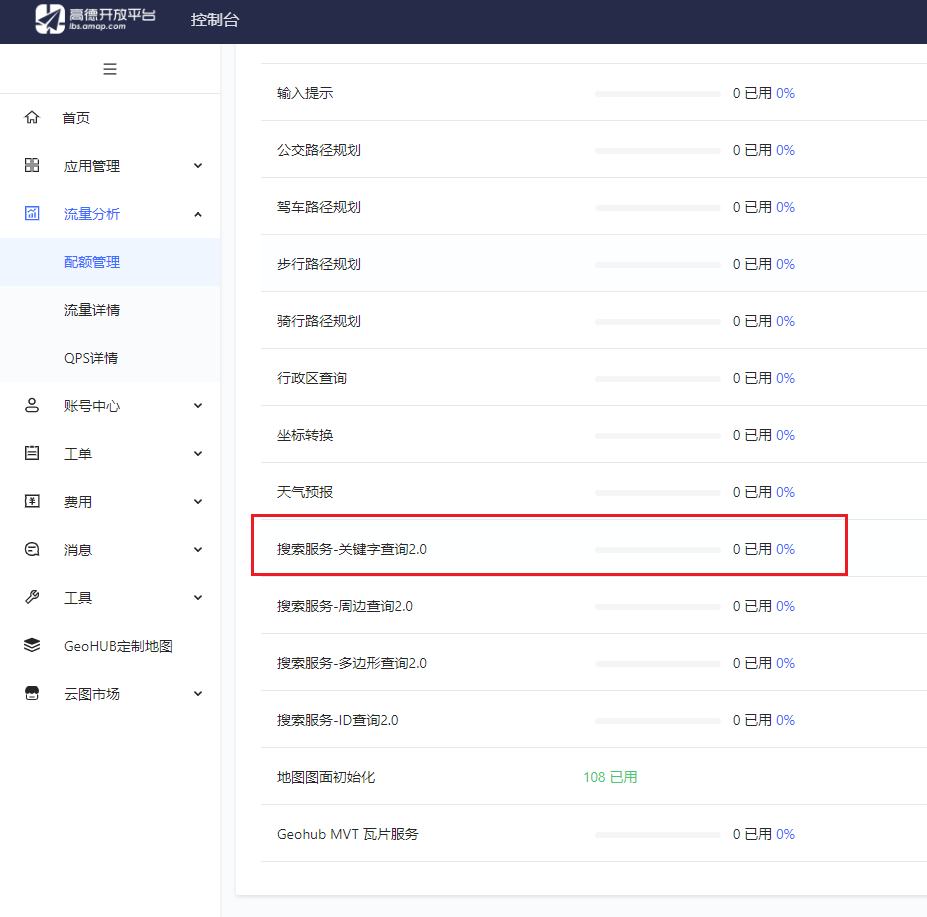 前端 - 高德地图JS API如何使用【关键字查询2.0】API?
前端 - 高德地图JS API如何使用【关键字查询2.0】API?请问高德地图 JS Api 如何使用 【搜索服务-关键字查询2.0】? 【高德地图开放平台】配额管理:https://console.amap.com/dev/flow/manage 我有通过在 创建地图实例时,提供 version:"2.0",使用JS API2.0。 还有在使用 高德地图 map.placeSearch API 时,提供 version:"2.0". 都没有用。