《德州仪器》专题
-
 杭州银行总行开发面经
杭州银行总行开发面经6.21 打电话确认意向 6.28发笔试邀请 笔试是行测(阅读理解、图标理解、逻辑推理、两部分性格测试) 7.1面试邀请 7.3面试 面试全程7分钟 自我介绍 项目介绍 项目职责 用到的技术 为什么来杭州 愿不愿意转java 结束 感觉像kpi 没问啥专业问题 也可能我是cpp
-
 tplink杭州 图像算法提前批
tplink杭州 图像算法提前批1面6.6 2面6.11 3面6.21 123面都是问的项目,三面还问了一些爱好还有为啥nlp转cv之类的。感觉三次面试都挺轻松的,打磨好自己的项目就行,有少量反问因为我没表达清楚。二面我提了一嘴大一学过c,然后被问了一个问题答不上来,其他基本都还好。 反问: 杭州初期是否提供宿舍,业务相关这些 看能不能给offer了
-
 杭州端点后端一面面经
杭州端点后端一面面经#我的失利项目复盘##24届暑假实习#5.22 晚 7 点 电话面 1、 自我介绍 2、hashmap 底层原理 扩容机制 3、多线程的创建方式 4、线程池参数和执行流程 5、MySQL 索引 分类 6、索引为什么用B+tree 7、讲一下聚集索引和非聚集索引的区别。 8、Innodb 和 MyIASM 的区别。(这里我认为应该从B树结构开始谈起) 9、讲一下MVCC(准备大说特说,这块背的贼熟练
-
 郑州某公司java开发面经
郑州某公司java开发面经1.自我介绍 2.谈谈你对spring的理解 3.spring和springmvc都有一个ioc容器,两个ioc容器哪个优先? 4.你如何理解ioc的,如何实现,控制反转是什么意思? 5.谈谈你对线程的理解,进程和线程的关系,进程是什么? 6.java中如何创建线程? 7.你用过哪些集合? 8.set的底层结构是什么? 9.hashmap的底层结构 10.是什么时候把红黑树加入hashmap的?
-
 23秋招 阿里高德部门机器学习 面经
23秋招 阿里高德部门机器学习 面经更新:已挂 9月1号投递的算法工程师-机器学习岗,高德部门 9.5一面 (50min) 总结:面试分四部分:简历项目+基础知识+场景题+做题 自我介绍 简历项目比赛介绍+提问 问了许多深度学习和机器学习的基础知识: 卷积 vs 全连接 怎么理解卷积? 图片的物体发生位移或扰动,对CNN有影响吗? 池化的作用 随机森林 vs GBDT 随机森林和GBDT的基分类器可以改成线性分类器或者其他吗? 分类
-
注入模拟对象时测试仪器过程崩溃
我正在尝试运行UI测试。当我不嘲笑任何注入的依赖时,一切都运行得很好。当我将模块的@provides return切换到mocked对象时,我会得到以下消息: 已开始运行测试 测试仪器过程崩溃。 下面是一些测试代码: 什么都不能打印出来。 但如果我把模拟的共享数据转换成真实的数据 嘲弄一些其他模块也会带来相同的结果,而嘲弄其他模块工作良好。 有什么想法吗?
-
JaCoCo离线仪器和集成测试覆盖率报告
我一直在尝试在JBoss服务器中实现JaCoCo离线代码覆盖,使用仪表化的EAR进行部署和jacococagent.jar,以便跟踪针对所述JBoss运行的外部集成测试的代码覆盖。 我一直在关注这样的指南: http://www.eclemma.org/jacoco/trunk/doc/offline.html http://automationrhapsody.com/code-coverage
-
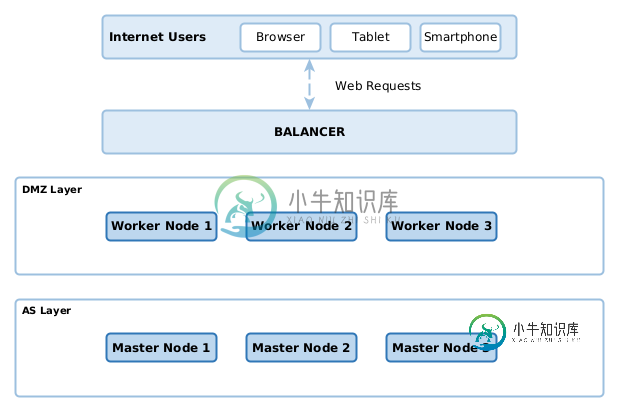 库伯内特斯·德普洛伊姆斯
库伯内特斯·德普洛伊姆斯我在Kubernetes是个新手。我想知道在kubernetes环境中最好的生产部署场景是什么。 在过去的学派中,我习惯于将Web服务器(例如Nginx或Apache)放在DMZ层,而将其放在其他层(我们称之为层)。这样,只有web服务器在DMZ上,恶意攻击只能在web服务器VM上进行。 据我所知,K8S部署不再需要这种方法;这是因为K8S自己处理网络、吊舱和流量。所以我在考虑最确定的部署方案。
-
 宁德时代 数字化开发 面经
宁德时代 数字化开发 面经25min 1.自我介绍 2.讲一下本科专业和研究生专业,分别学了啥 3.讲项目 4.Java主流框架讲一下 5.两个项目讲一下,团队怎么分工的,有没有移动端用户使用 6.对宁德时代的看法 7.讲专利,的创新点 8.个人优缺点 9.职业规划 10.反问 #宁德时代#
-
 宽德投资,一次无语的面试
宽德投资,一次无语的面试上来就说你这项目实习都没啥想问的 就说随便问 linux内核版本号是什么,你当时用的是什么 c++文件读取方式,c用什么,区别 创建进程的函数有哪些,怎么改变进程的大小 创建失败的原因 socket里面read和send函数区别 read函数底层实现原理 ip报文头部格式具体有哪些东西都是干什么的 (ip报文我都说完了他非说不对….)#秋招#
-
 梅卡曼德C++开发实习面经
梅卡曼德C++开发实习面经这次面试面试官挺好的, 就是感觉的我答的一般般, 由于问了一些比较细微的知识点, 不太记得了... 梅卡曼德C++开发实习-30min 整形和浮点的存储 浮点数的等0的判断 对于内存的理解 虚拟内存和物理内存的关系 进程和线程与虚拟内存 虚拟内存的分布 函数调用对内存的使用 多态的底层及原理 set和map的理解及使用场景 map和unordered_map的结构及使用场景 反问-后续流程/工作任
-
大查询时间火花卡桑德拉
全能的开发者们。我在Spark中运行一些基本的分析,在这里我查询多节点Cassandra。我正在运行的代码以及我正在处理的一些非链接代码是: Spark的版本是1.6.0,Cassandra v3。0.10,连接器也是1.6.0。键空间有,表有5列,实际上只有一行。如您所见,有两个节点(OracleVM中制作的虚拟Macine)。 我的问题是,当我测量从spark到cassandra的查询时间时,
-
格拉德尔:什么是依赖关系?
在学习gradle时,我似乎是Java的构建工具。但我不明白依赖到底是什么。Gradle中的依赖项部分到底是什么意思?它有什么用途?
-
卡桑德拉的本地传输请求
我通过以下链接获得了有关卡桑德拉的本地传输请求的一些要点:卡桑德拉中的本地传输请求是什么? 根据我的理解,我在卡桑德拉执行的任何查询都是本机传输请求。 我经常在Cassandra中收到请求超时错误,我在Cassandra调试日志和使用< code>nodetool tpstats时观察到以下日志 1) 状态是什么 2)这个值是什么:表示?它有多有害 3)如何调整?
-
在卡桑德拉中建模多租户
我有几个客户,每个客户都由一个“租户”代表 我想知道将这个概念建模的最佳方法是什么,我做了大量的研究,发现了这个课题:http://cassandra-user-incubator-apache-org.3065146.n2.nabble.com/Modeling-multi-tenanted-Cassandra-schema-td7591311.html 我知道有几种可能性 租户提供一个密钥空间