《性能》专题
-
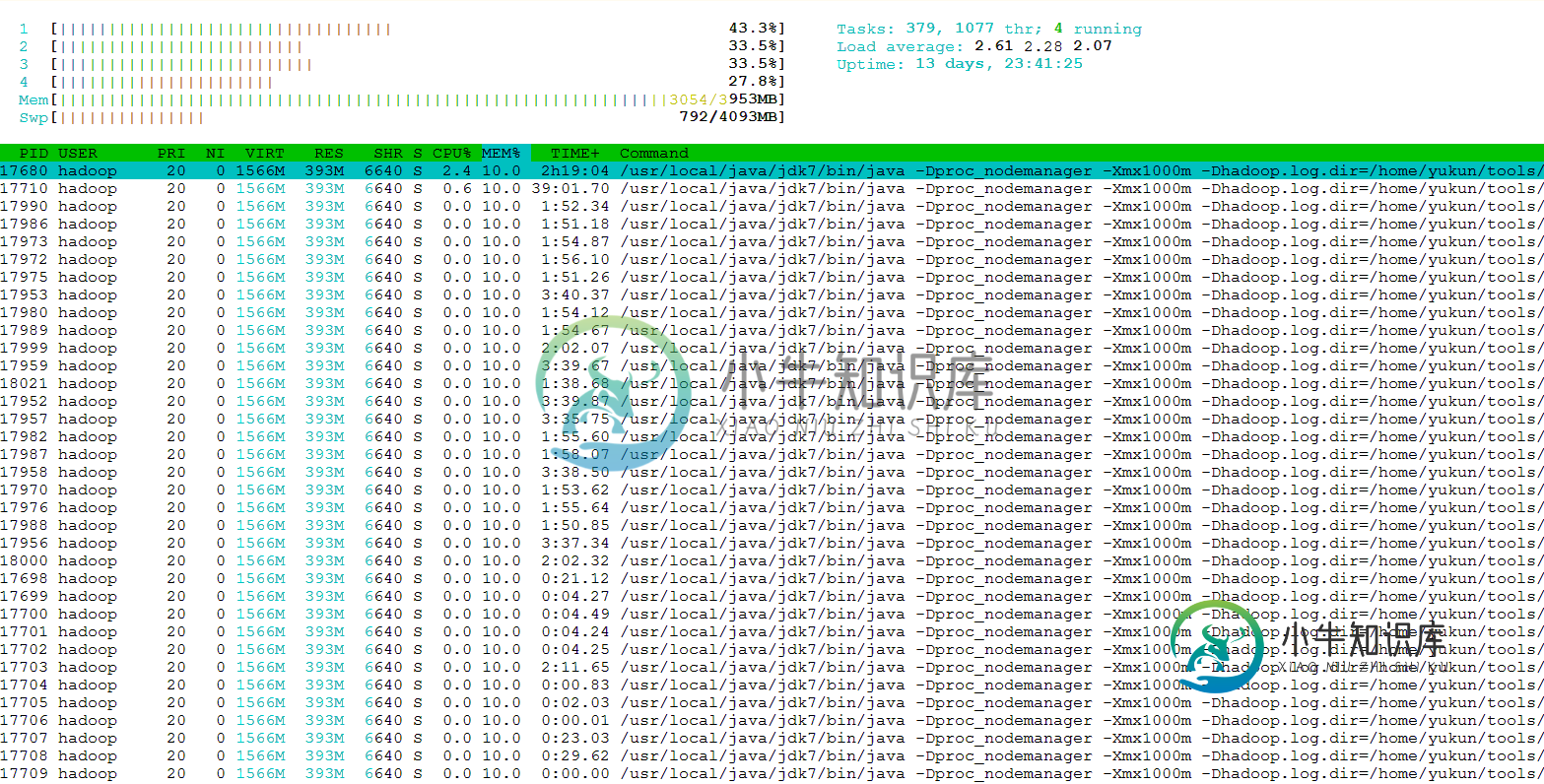 hadoop纱单节点性能调优
hadoop纱单节点性能调优我在我的Ubuntu VM上有hadoop 2.5.2单模式安装,它是:4核,每个核3GHz;4G内存。这个VM不是用于生产的,只用于演示和学习。 然后,我使用python编写了一个vey简单的map-reduce应用程序,并使用该应用程序处理49个XML。所有这些xml文件都很小,每个文件都有数百行。所以,我期待一个快速的过程。但是,big22令我惊讶的是,它花了20多分钟才完成这项工作(该工作
-
SecurityContext#setAuthentication能保证可见性吗?
我在我的项目中使用spring security。 我有更改登录的功能。为了实现这个目标,我使用以下代码 但现在我正在详细研究这段代码,并看到身份验证字段不是易变的,因此不保证可见性: 我应该用自己的同步来包装代码以实现可见性吗? 我读过https://stackoverflow.com/a/30781541/2674303 在单个会话中接收并发请求的应用程序中,相同的SecurityContex
-
Hibernate@DynamicUpdate(value=true)@SelectBeForeUpdate(value=true)性能
首先,我会试着解释我对它的理解,以知道我对它的理解是否正确。 只更新实体中的修改值 在之前创建,以了解哪些属性已被更改,这在实体已在不同会话上加载和更新时非常有用 在中,哪个更好或更快,一次更新实体中的所有字段,还是
-
Java性能问题-Tomcat WebappClassLoader锁定
在过去的几天里,当我使用Java6、Struts3框架和Tomcat7服务器对我的产品进行性能测试时,我一直面临着这个奇怪的问题
-
Spring无功高负荷性能差
我有一个spring boot webflux应用程序,默认情况下使用Netty。其中一个业务需求,我们有要求,要求应超时在2秒内。 当很少的请求被发送到应用程序时,一切都很好,但是当请求负载增加时(比如Jmeter每秒并发超过40或50次),由于每个请求的时间超过2秒阈值,有时所有请求都会超时。 如果有人能告诉我该做什么,那将是一个巨大的帮助。在这一点上,我没有更多的改进,并认为我可能已经看错了
-
短路评估的性能影响
免责声明:我对反向工程字节码没有太多的经验,所以请不要对我太苛刻,如果这可以“轻松”回答我的问题。
-
 Spring mvc野蝇postgresql性能调整
Spring mvc野蝇postgresql性能调整我花了很多时间试图找出导致我的应用程序工作非常缓慢的原因,也许有人会帮助我检查问题所在。 版本: 操作系统:Debian GNU/Linux 7.9(wheezy) 关于我的应用: 带有静态登录页面、信息页面和登录的简单Web应用程序重定向到私人区域。公共页面是静态的,在登录期间首先查询数据库,然后尝试为登录用户获取内容。 问题是什么: 当我浏览这样配置的页面时: 没有问题,所有的东西都被装上了飞
-
VueJS、Vuetify、Data-Table-Expandable、性能问题
我的VueJS和Vuetify项目有问题。我想创建一个包含可扩展行的表。这将是一个订单表,有可能看到购买的产品为每一个。对于一个页面,它应该显示至少100行订单。为此,我使用了Vuetify框架中的。 准备好一切后,我意识到它可以工作,但是对于每一行的扩展,我必须等待几秒钟(太长了--它必须是一个快速的系统)。为了展开所有可见的记录,需要等待20秒以上,并且整个页面滞后。 我从标准的Vuetify
-
递归的意外性能结果
我想知道为什么我用这两对递归的明显例子得到了意想不到的表现。 相同的递归函数在结构中更快(rec2 VS rec1),相同的递归模板函数在虚拟参数中更快(rec4 VS rec3)! 使用更多参数的C++函数是否更快?! 下面是尝试的代码: 我得到这样的输出: 我已启用:Windows 8.1/i7 3630QM/Latch Qt ChainTool/C++14
-
 Inner join mysql性能搜索产品
Inner join mysql性能搜索产品我有两张桌子: 现在,如果有人正在寻找关键字“car”,它会看看下面的表词: 这样的单词非常快。 问题是,当我想用这个词得到独一无二的产品时。这些表与words.id和products_words.word连接。 我使用了以下SQL: 我不明白它为什么要看1799211行?我需要告诉MySql先看words表,选择F.E。10个ID和给我带来独特的产品与这些ID的Word。 我做错了什么? 谢谢你
-
如何提高cassandra的写性能?
我有一个名为Emails的列族,我正在将邮件保存到这个CF中,编写5000封邮件需要100秒。 我使用的是i3处理器,8gb内存。我的数据中心有6个节点,复制因子=2。 我们存储在卡桑德拉中的数据大小会影响性能吗?影响写入性能的所有因素是什么,如何提高性能? 预先感谢..
-
JPA/Hibernate提高批插入性能
我有一个数据模型,在一个实体和11个其他实体之间有一对多的关系。这12个实体一起代表一个数据包。我遇到的问题是,在这些关系的“多”端发生的插入数量。其中一些可以有多达100个单独的值,因此要在数据库中保存一个完整的数据包,最多需要500次插入。 我在InnoDB表中使用MySQL 5.5。现在,通过对数据库的测试,我发现在处理批插入时,它可以轻松地每秒执行15000次插入(对于加载数据,插入次数甚
-
过滤图像的最快性能
上下文:我试图用Java创建一个动画。动画是简单地采取一个图像,并使它出现从最暗的像素到最亮。 问题:定义像素转换的内部算法不是我的问题。我对Java和一般计算都是新手。我做了一些研究,知道有很多API有助于图像筛选/转换。我的问题是表现,理解它。 对于实现,我创建了一个方法,它执行以下操作: 接收BufferedImage。 获取BufferedImage的WritableRaster。 使用s
-
MYSQL视图查询性能问题
我有5个SQL表 存储 工作人员 部门 SOLD_Items staff_rating 我创建了一个视图,将这四个表连接在一起。最后一个表(staff_rating),我希望在接近项目被出售的时间(sold_items.date)获得视图行的rating列。我尝试了以下SQL查询,这些查询工作正常,但存在性能问题。 SQL查询1 SQL查询2 SQL查询%2比SQL查询%1快。但这两种方法都存在性
-
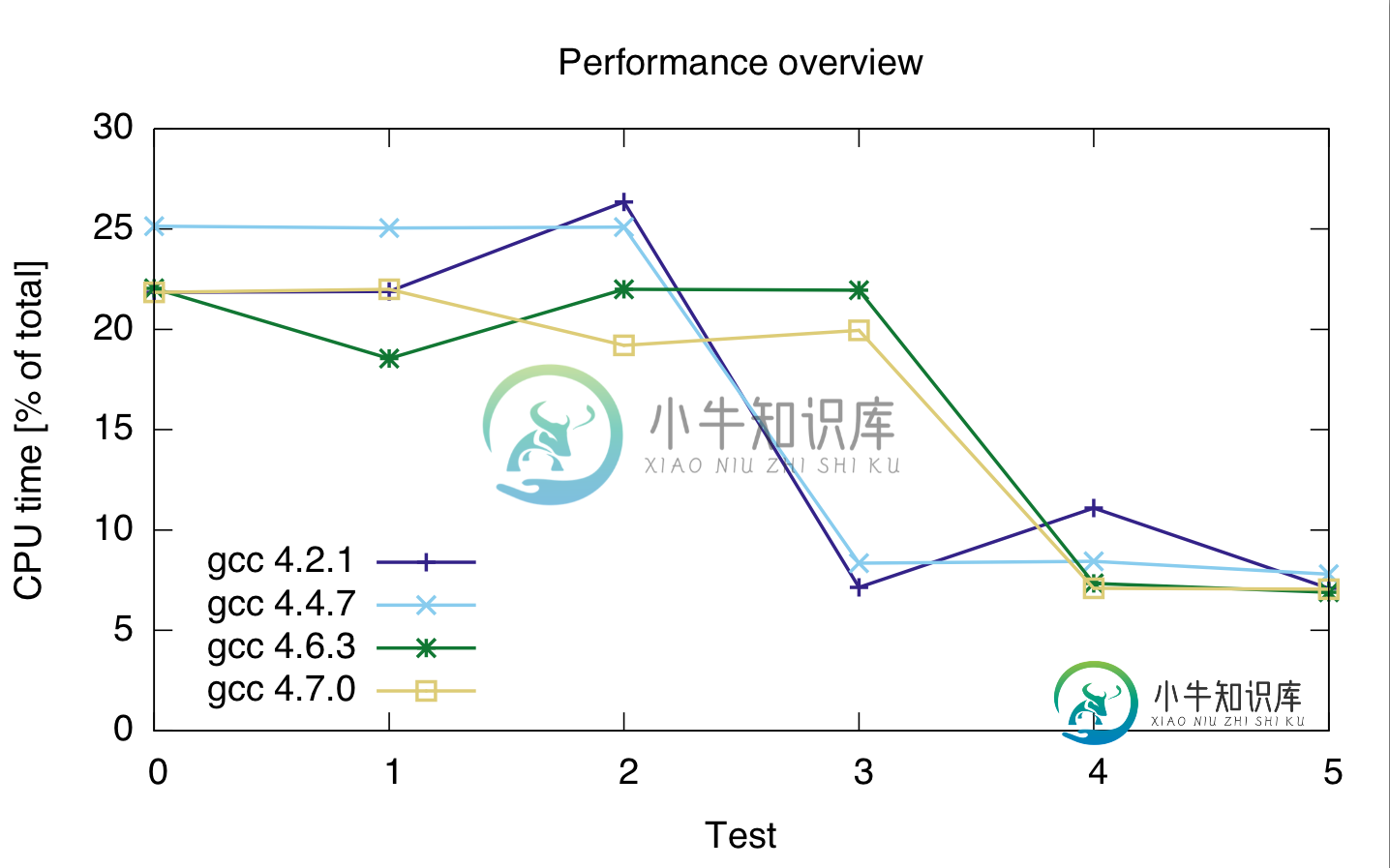 从size_t到double的铸造性能
从size_t到double的铸造性能TL;DR:为什么乘法/转换数据的速度很慢,为什么这因平台而异? 我遇到了一些不完全理解的性能问题。上下文是一个相机图像采集卡,其中以100 Hz的速率读取和后处理128x128 uint16_t图像。 在后处理中,我生成一个直方图 ) 令人惊讶的是,比? 更新4: 我在一台机器上用不同的数据类型和不同的编译器又做了一些测试。结果如下。 对于testd 0 - 2,相关代码为 和平方为双精度, ,