《性能》专题
-
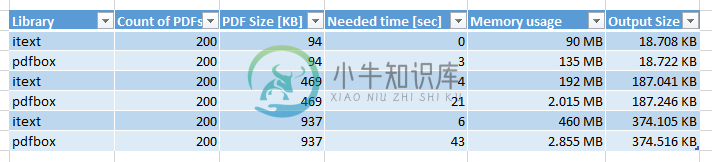 将itext替换为pdfbox性能
将itext替换为pdfbox性能我正在评估将我们的pdf处理从itext替换为pdfbox。我用200个单页pdf(94KB、469KB、937KB)做了一些测试,并将它们合并到我们应用程序中的一个pdf中。PDFBox版本:2.0.23。itextversion:2.1.7。以下是测试结果: 这是itext实现: 这是pdfbox实现: 我也尝试过使用pdfbox的pdfmerger。性能几乎与其他pdfbox实现相同。但对于
-
Jeter性能测试:Thread泄漏
JMeter可以在java应用程序中检测线程泄漏吗?也就是说,可以通过JVisualvm观察线程泄漏,但是JMeter没有任何插件等可以检测Java应用程序中的线程泄漏。如果没有,那么有没有其他性能测试工具可以检测java应用程序中的线程泄漏,为什么Jeter不能这样做?
-
Spring批处理-性能调整
我们开发了一个Spring批处理应用程序,其中我们有两个流程。1.向前2.向后。我们只使用文件读/写,不涉及数据库。 > 正向场景:输入文件将包含22个字段的记录。通过执行序列号生成和添加一些填充字段等操作,将22个字段转换为32个字段。根据国家代码,输出将被分成最多3个。每个块将有250K条记录。(如果记录以百万为单位,则将为同一国家生成多个文件)。 800万张唱片需要36分钟。 800万记录将
-
尾递归函数的性能
各种各样的书籍、文章、博客帖子表明,将递归函数重写为尾部递归函数可以加快速度。毫无疑问,对于生成斐波那契数或计算阶乘等琐碎情况,它会更快。在这种情况下,有一种典型的重写方法,即使用“辅助函数”和用于中间结果的附加参数。 尾部递归很好地描述了尾部递归函数和非尾部递归函数之间的差异,以及如何将递归函数转换为尾部递归函数。对于这种重写来说什么是重要的-函数调用的数量是相同的(重写之前/之后),不同之处在
-
使用AspectJ的性能损失
我想为我的方法创建一个发送计时器指标的注释。我想做这样的事情: 然后,我想使用AspectJ进行度量收集逻辑,如下所示: 我想了解的是,我不知道如何对其进行基准测试,在这里使用此注释时是否会有性能损失。
-
spring上的aop性能(idk,aspectj)
我试图在Spring framework 4.1.6和 AOP方法有clean、jdk动态代理和aspectJ。 我给他们提了一到五个简单的建议,并检查了每个建议的运行时间。 结果: jdk动态代理: null aspect1:2.499秒。 aspect2:2.574 方面3:2.466 方面4:2.436 方面5:2.563 aspectJ(ctw): null 方面1:2.648 方面2:2
-
改进ListView性能的建议
我正在使用自定义列表视图来显示图像和文本。下面是我的列表视图项的布局文件和后面的代码。我会在帖子的底部解释我的问题。 下面是将必要信息加载到列表视图中的后端代码。 12-21 03:54:20.827:D/OpenGrenderer(1248):启用调试模式0 12-21 03:54:20.955:我/编舞(1248):跳过36帧!应用程序可能在其主线程上做了太多的工作。 12-21 03:54:
-
SQL Server删除性能问题
我有一张大约有一百万行的桌子。我们的部分维护包括每天删除旧行,但这需要大约40分钟。 delete语句是: 我能做些什么来提高性能吗? 谢谢 根据要求: ([cder\u ID]ASC)在[PRIMARY]上具有(PAD\u INDEX=OFF,STATISTICS\u NORECOMPUTE=OFF,IGNORE\u DUP\u KEY=OFF,ALLOW\u ROW\u LOCKS=ON,AL
-
性能Mongodb java驱动程序
驱动程序版本为: 我的问题是,当我使用api find和一些来自java的过滤器时,操作需要15秒。 我检查了mongo服务器日志文件,发现跟踪是一个命令,而不是一个查询: 2015-09-01T12:11:47.496+0200I命令[conn503]命令b.$CMD命令:计数{count:“logs”,查询:{timestamp:{$GTE:新日期(1433109600000)},aplica
-
效率低下的EhCache性能
使用thoses和JPA属性 Ehcache对于相同的查询不是有效的, 问题与QueryCache类的函数namedParameters.hashCode()有关,它为同一个查询生成不同的HashCode! 这与类有关 它为同一个数组对象[01,1]生成一个不同的(新的)hachCode! 此hashCode方法对于数组应该是递归的
-
Azure EventHub:发送异步性能
在日志中,我有将近1秒(~800毫秒)的值,为什么会有这么长的执行时间?
-
bool vs int数组的性能
在Go中玩一些简单的代码时,我注意到使用bool数组而不是int数组(它只使用0/1的值)可以大大加快速度。 函数使用布尔 - 1.397s 函数使用国际 - 1.996s 我本来希望这两个编译器都能提供相同的性能,因为在机器级没有本机bool类型,所以我本来希望编译器能生成类似的汇编代码。 由于差异很大,我对这个结果的有效性表示怀疑。 我使用命令“go-build-filename.go”进行构
-
流的性能。排序()。限制()
Java Streams同时使用和方法,这两种方法分别返回流的排序版本和仅返回流中指定数量项的流。连续应用这些操作时,例如: 排序是以排序项的方式执行的,还是对整个列表进行排序?换句话说,如果是固定的,那么这个操作是否在中?留档不会单独指定这些方法的性能,也不会相互关联指定这些方法的性能。 我提出这个问题的原因是,这些操作的明显必要实现是排序然后限制,这需要时间。但是这些操作可以一起在中执行,智能
-
Cassandra查询日志和性能
1) 有没有办法记录在Cassandra中执行的查询 2)为了提高性能,我了解cqlsh中的TracingON是一个很好的功能,用于跟踪我们在cqlsh中执行的单个查询。但是是否有一种方法来分析Cassandra查询,它给出了执行时间、查询数据大小等。,
-
卡桑德拉写入性能
我们有这个Cassandra集群,想知道当前的性能是否正常,我们可以做些什么来改善它。 集群由位于同一数据中心的3个节点组成,每个节点的总容量为465GB,堆容量为2GB。每个节点有8个内核和8GB或RAM。不同组件的版本为 工作量描述如下: 空格键使用org.apache.cassandra.locator。SimpleStrategy布局策略和复制因子为3(这对我们非常重要) 工作负载主要由写