《性能》专题
-
python和sqlite3的插入性能
问题内容: 我正在向SQLite3数据库中进行大批量插入,并且试图了解我应该期望的性能与实际看到的性能之间的关系。 我的桌子看起来像这样: 和我的插入看起来像这样: 元组列表在哪里。 目前,在一台2008年的Macbook上运行,在数据库中大约有1200万行的情况下,插入行花了我大约16分钟的时间。 这听起来合理吗,还是发生了什么大事? 问题答案: 据我了解,性能不佳的主要原因是浪费时间来执行许多
-
表与临时表的性能
问题内容: 数百万条记录的哪个更快:永久表 还是 临时表? 我只需要将其用于1500万条记录。处理完成后,我们将删除这些记录。 问题答案: 在您的情况下,我们使用称为临时表的永久表。这是大量进口的常用方法。实际上,我们通常使用两个登台表,一个带有原始数据,另一个带有清理后的数据,这使得研究提要中的问题变得更加容易(它们几乎总是我们客户发现向我们发送垃圾数据的新方式和多种方式的结果,但是我们必须
-
Python性能:是否尝试-否?
问题内容: 在我的一个类中,我有许多方法都从相同的字典中提取值。但是,如果其中一个方法尝试访问不存在的值,则它必须调用另一个方法以使该值与该键关联。 我目前已按以下方式实现此功能,其中findCrackDepth(tonnage)为self.lowCrackDepth [tonnage]分配一个值。 但是,我也有可能这样做 我假设两者之间存在性能差异,这与值在字典中的频率有关。这个差异有多大?我正
-
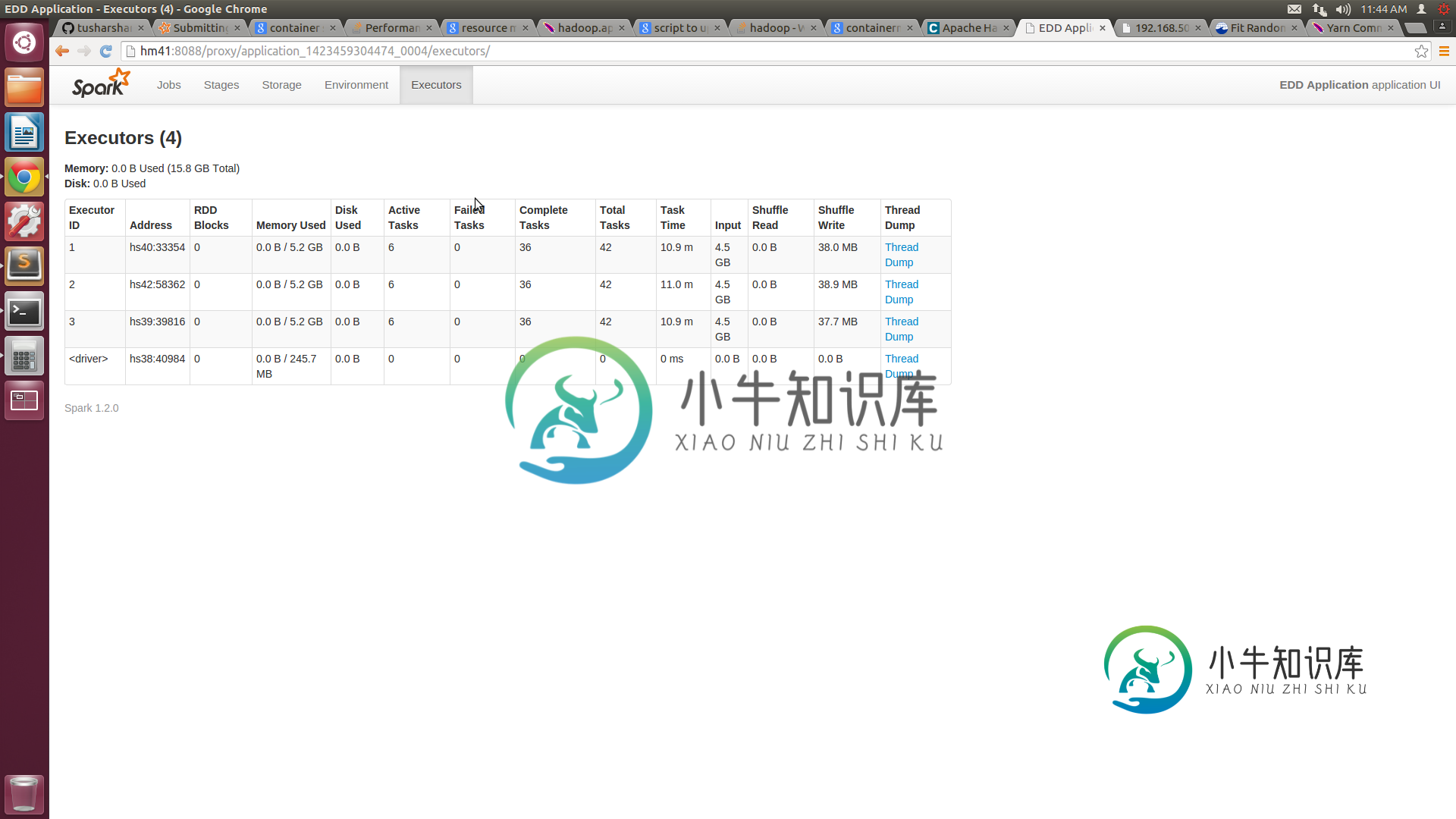 火花线的性能问题
火花线的性能问题我们正在尝试在纱线上运行我们的火花集群。我们有一些性能问题,尤其是与独立模式相比。 我们有一个由5个节点组成的集群,每个节点都有16GB的RAM和8个核心。我们已将纱线站点中的最小容器大小配置为3GB,最大为14GB。xml。向纱线集群提交作业时,我们提供的执行器数量=10,执行器内存=14 GB。根据我的理解,我们的工作应该分配4个14GB的容器。但spark UI仅显示3个容器,每个容器的容量
-
PHP中的FOR循环性能
问题内容: 当我的研究使我相信循环是PHP中最快的迭代构造…为了使它更清晰时,您认为以下哪个会更快? 示例一 示例二 我的逻辑是,在示例中的每次迭代中,在每次迭代中访问myLargeArray的长度比在示例二中访问简单的整数值要昂贵。那是对的吗? 问题答案: 第一种方法较慢,因为必须在循环的每次迭代中都调用该函数。该方法本身非常快,但是调用该函数仍然有一些开销。通过将其移动到循环之外,您正在执行所
-
Java拆分字符串性能
问题内容: 这是我的应用程序中的当前代码: 在对应用程序进行性能分析时,我注意到用于拆分字符串的时间不可忽略。 我还了解到,实际上需要一个正则表达式,这对我来说毫无用处。 所以我的问题是, 我可以使用哪种替代方法来优化字符串拆分? 我见过,但是速度更快吗? (我会尝试并测试自己,但是对我的应用程序进行性能分析需要花费很多时间,因此,如果有人已经知道答案,那么可以节省一些时间) 问题答案: 如果您的
-
Scala vs Java,性能和内存?
问题内容: 我热衷于研究Scala,并提出了一个似乎无法找到答案的基本问题:一般来说,Scala和Java在性能和内存使用方面是否有所不同? 问题答案: Scala使得无需意识到即可轻松使用大量内存。这通常非常强大,但有时可能很烦人。例如,假设您有一个字符串数组(称为),以及从这些字符串到文件的映射(称为)。假设您要获取地图中所有来自长度大于两个的字符串的文件。在Java中,您可能 ew!辛苦了
-
性能测试整体概念
本文向大家介绍性能测试整体概念相关面试题,主要包含被问及性能测试整体概念时的应答技巧和注意事项,需要的朋友参考一下 时间性能:软件的一个具体事务的响应时间。比如点击一个登陆按钮,到登录成功(失败)的反应时间,浏览器非常常见,ANR(Application not responding 应用程序无响应) 空间性能:软件运行时所消耗的系统资源,比如对内存和cpu的消耗 一般性能测试:软件正常运行,不向
-
性能:子查询或联接
问题内容: 我对子查询的性能/连接另一个表有一些疑问 这是我的SQL,现在这个东西可以运行大约一百万次或更多。我的问题是什么会更快? 如果我更改为() 或者 如果我将’HelpTable’添加到中并在中进行联接? edit1 好吧,此脚本仅运行与r个人一样多的人。 我的程序有2个模块,一个模块填充,另一个模块传输数据。该程序确实将2个数据库合并在一起,因此有时会使用相同的Key。 现在,我正在研究
-
Java中的StringBuilder性能测试
本文向大家介绍Java中的StringBuilder性能测试,包括了Java中的StringBuilder性能测试的使用技巧和注意事项,需要的朋友参考一下 在看KMP算法时,想要简单的统计一下执行时间和性能。 得出的结论是: Java的String的indexOf方法性能最好,其次是KMP算法,其次是传统的BF算法,当然,对比有点牵强,SUN的算法也使用Java来实现、用的看着不像是KMP,还需要
-
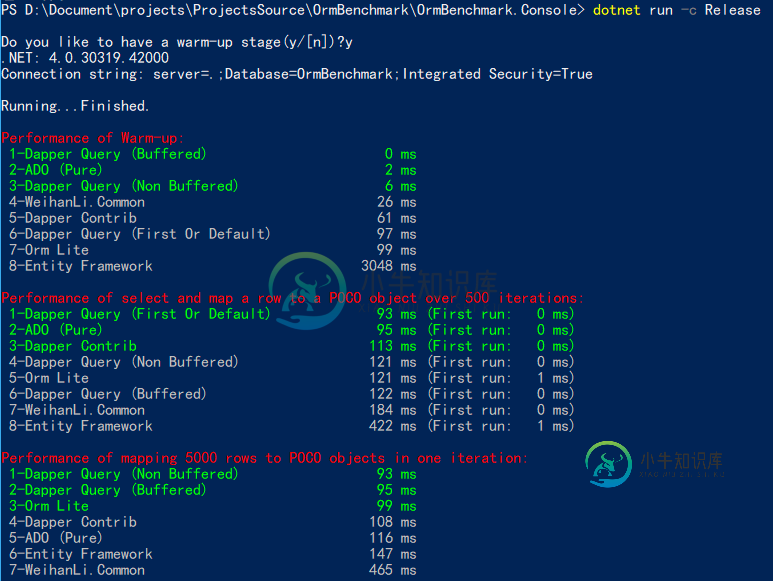 .NET Orm性能测试分析
.NET Orm性能测试分析本文向大家介绍.NET Orm性能测试分析,包括了.NET Orm性能测试分析的使用技巧和注意事项,需要的朋友参考一下 简介 OrmBenchmark 这个项目主要是为了测试主要的Orm对于 SqlServer 数据库的查询并将数据转换成所需 POCO 对象的耗时情况(好吧,实际上不完全orm,更像是SqlMapper ...) 测试结果: .NetFramework 4.6 有预热 .NetFr
-
多键映射-性能比较
我们的应用程序将大量数据存储在内存中,存储在多种不同类型的地图中,以便快速查找。为了保持简单(不考虑原始贴图),它始终是一个带有一个或多个键的贴图。性能对我们来说是一个很大的要求。 我想找到性能最好的地图实现,正如这里建议的那样,我比较了这些实现: > java中的包装键(元组作为键)。util。哈希图 元组作为网络中的键。openhft。科洛博克。收集地图搞砸HashObjObjMap,根据这一
-
AWS中的MongoDB性能问题
我们有以下MongoDB设置: 基础设施 3个在AWS中运行的副本集。此时,所有节点都位于同一可用性区域,并且都是i3。大型实例。其中2个节点在NVME驱动器上托管DB数据,1个节点在配置IOPS的EBS卷上托管它。 数据 数据设置有点可疑,但根据我对文档的理解,应该可以正常工作。 我们每个客户都有一个数据库——大约5.5万个。 每个数据库都包含几个具有特定于帐户的数据的集合。这些数据并没有什么特
-
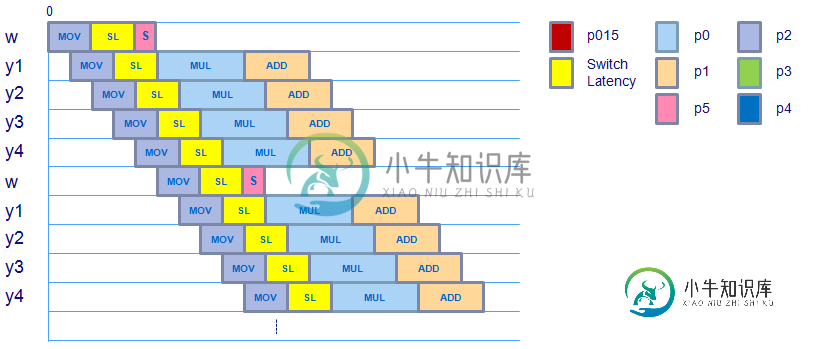 C代码循环性能[续]
C代码循环性能[续]这个问题继续我的问题(根据神秘主义者的建议): C代码循环性能 继续我的问题,当我使用压缩指令而不是标量指令时,使用内部函数的代码看起来非常相似: 该内核的测量性能约为每个周期5.6个FP操作,尽管我预计它的性能恰好是标量版本的4倍,即每个周期4.1,6=6,4个FP操作。 考虑到权重因素的变动(感谢您指出),时间表如下所示: 虽然在movss操作之后有一条额外的指令将标量权重值移动到XMM寄存器
-
Spring cloud stream rabbitmq性能测试
我已经用Rabbitmq绑定器设置了一个Spring Cloud stream。我想用Spring Cloud stream做性能测试。有什么方法可以用它做性能测试吗?