《商业分析》专题
-
如何在weebly在线商店产品分类页面中设置SEO标题和元描述
我有一个简单的查询在weebly网站,我已经更新了SEO标题和元描述的产品类别网页,但它不是更新的网站。 在weebly网站上有没有其他的选项来更新SEO标题和元描述。?
-
 欧莱雅-电商运营岗群面面经 一些我自己的压箱底小分享
欧莱雅-电商运营岗群面面经 一些我自己的压箱底小分享回答注意点: 舆论影响 用数据、报告的角度出发,不是“我觉得” 给别人留机会 立场坚定 创新 不要急:控制住个人情绪 Pre需要storytelling不是复述:大的主题吸引住眼球、先是利益背景,然后Why,再是How 所有话题都参与,哪怕是不擅长的领域 思路注意点: 先方式方法,后想为什么❌ 消费者导向(搞清楚独特的消费者特质,这个群体有而其他群体没有的) 品牌导向(根据品牌核心价值以及主张出发
-
降维 - PCA(主成分分析)
1 主成分分析原理 主成分分析是最常用的一种降维方法。我们首先考虑一个问题:对于正交矩阵空间中的样本点,如何用一个超平面对所有样本进行恰当的表达。容易想到,如果这样的超平面存在,那么他大概应该具有下面的性质。 最近重构性:样本点到超平面的距离都足够近 最大可分性:样本点在这个超平面上的投影尽可能分开 基于最近重构性和最大可分性,能分别得到主成分分析的两种等价推导。 1.1 最近重构性
-
Python中的主成分分析
问题内容: 我想使用主成分分析(PCA)进行降维。是否已经有numpy或scipy,或者我必须使用自己滚动? 我不只是想使用奇异值分解(SVD),因为我的输入数据具有很高的维数(约460个维数),因此我认为SVD比计算协方差矩阵的特征向量要慢。 我希望找到一个预制的,已调试的实现,该实现已经对何时使用哪种方法以及哪些可能进行的其他优化进行了正确的决策,而这些优化我都不知道。 问题答案: 您可以看看
-
快速排序:分区分析
我正在学习快速排序在第四算法课程,罗伯特塞奇威克。 我想知道quicksort代码的以下分区是长度为n的数组中比较的个数。
-
1.请问社交电商为什么兴起?2.请你说出三个社交电商,目标用户,商业模式,优势?3.你认为哪一个杀出了红海,请简述一下其理由?4.基于微信生态的电商,你觉得它们会给阿里京东造成什么影响?"
本文向大家介绍1.请问社交电商为什么兴起?2.请你说出三个社交电商,目标用户,商业模式,优势?3.你认为哪一个杀出了红海,请简述一下其理由?4.基于微信生态的电商,你觉得它们会给阿里京东造成什么影响?"相关面试题,主要包含被问及1.请问社交电商为什么兴起?2.请你说出三个社交电商,目标用户,商业模式,优势?3.你认为哪一个杀出了红海,请简述一下其理由?4.基于微信生态的电商,你觉得它们会给阿里京东
-
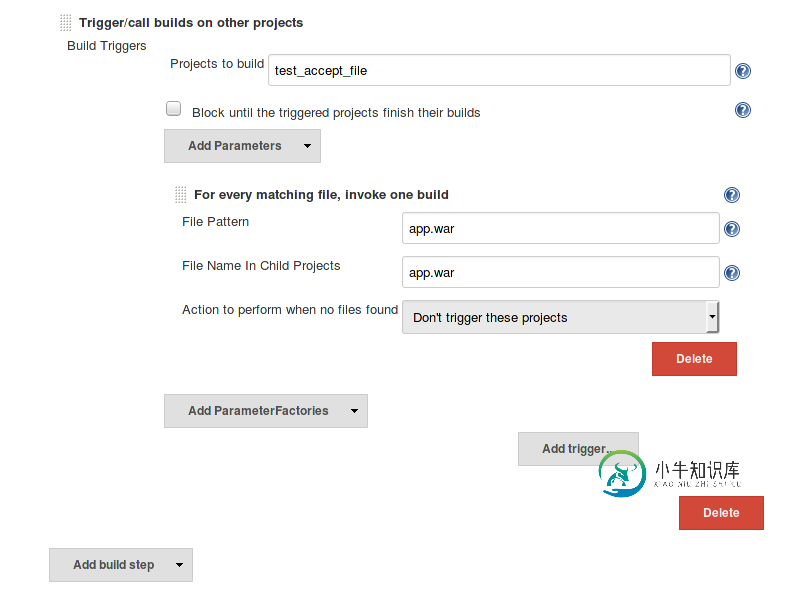 如何将文件传递到阻止上游作业的下游作业?
如何将文件传递到阻止上游作业的下游作业?问题内容: 我要完成的工作是从分支中签出代码,将其合并到分支,构建,运行测试,如果测试成功则推送到分支。 测试应在需要的单独工作中运行。 我当前的设置如下: Job 从中检出,将其合并并构建 作业会在“ 后期制作”步骤中 触发作业(需要预先创建) 如果成功,则在 发布构建操作中推送到分支 __ 我尝试使用 Copy Artifact Plugin, 但是问题在于,在 Post构建步骤中 触发时,我
-
是否可以将Jenkins自由式作业转换为多配置作业?
问题内容: 我在詹金斯(Jenkins)有很多自由式工作,我想转换为多配置工作,这样我就可以在一项工作下跨多个平台进行构建。这些作业指定了很多构建参数,我不想通过创建新的多配置作业来再次手动设置它们。当前,每个作业都将其构建限制为我们一直在构建的平台,而我看到的唯一其他选择是克隆现有作业,并将限制更改为新平台。这不是理想的选择,因为我需要维护2个工作,其中唯一的区别是目标平台。 我没有看到通过UI
-
Jenkins executor忙-加载条作业,但没有链接或id-幽灵作业
Jenkins重启后,我们发现很少有节点执行器繁忙。占据executor的作业有条带的蓝白加载条,并且没有链接到任何特定的构建(事实上,该作业没有正在进行的构建)。所以我们没有id或ui方式来中止它,您可以在这里看到: 詹金斯节点上的工作是什么样子的 现在,我想找到一种方法,在不真正调查问题原因的情况下杀死它,也许它与Jenkins管道作业相关,不会在UI中完成——但在我们的情况下,我们没有基本的
-
Spring Batch Admin现有作业在新作业注册后不再可启动
目前,由于一个我无法解决的问题,我一直在将Spring Batch Admin(SBA)集成到我们的项目中。希望有人能给我一个建议。 我们使用了示例SBA应用程序(Github的当前版本),只添加了一个Tasklet。我通过/job配置上传Spring批处理描述(XMLs)。SBA的json API使用。这工作正常。在SBA的HTML页面中,我看到该作业已注册并可启动。它可以通过API(/jobs
-
Azure Web作业未启动并始终给出“未找到作业功能”
我正在尝试使用触发器运行Azure网络作业,但我的时间作业方法没有触发。我收到了下面的消息。 未找到工作职能。尝试将您的作业类和方法公开化。如果您正在使用绑定扩展(例如ServiceBus、定时器等。)确保您已经在启动代码中调用了扩展的注册方法(例如config。UseServiceBus()、config。使用定时器()等。). 我正在使用配置。UseTimers() 但仍显示消息。不确定以下代
-
在Jenkins中将作业A的工作空间url传递给作业B
我有两个管道作业作业作业A和作业B。我需要通过作业A的工作空间url(比如 /var/lib/jenkins/workspace/JobA)被作业B使用。主要的想法是我试图复制由于maven构建而生成的目标文件夹的内容,但我不想使用复制工件插件或存档工件插件来实现同样的目的。 我尝试过使用“此作业已参数化”选项,其中作业A是作业B的上游,但我无法使用该选项。 有人能帮助实现同样的目标吗?
-
如何在作业结束时运行脚本,即使作业被取消?
这是我目前在GitHub上使用的工作流程 我有一台windows 10计算机,它使用GitHub runner监听传入的作业。在传入作业时,如果正在向主分支推送脚本ci_主机。py使用“--master”标志运行,该标志会启动一个VM并对其运行多个测试。最终,在测试结束时,脚本将VM恢复到预先配置的快照。 因此,基本上我试图实现的是,当通过GitHub操作web界面取消作业时,处理测试的脚本在作业
-
如何从数据流作业内部获取数据流作业 ID - JAVA
在我当前的架构中,多个数据流作业在不同阶段被触发,作为ABC框架的一部分,我需要捕获这些作业的作业id作为数据流管道中的审计指标,并在BigQuery中更新它。 如何使用JAVA从管道中获取数据流作业的运行id?有没有我可以使用的现有方法,或者我是否需要在管道中使用google cloud的客户端库?
-
如何使一个石英作业创建另一个作业后执行?
我想用Quartz实现下面的算法,但不确定是否可以做到。这是我第一次尝试使用石英。 用户通知作业-此作业计算每月报告并向用户发送电子邮件,它需要用户id和用于生成自定义用户报告的其他参数 可能需要生成10,000多个这样的报告 null 如何确保每月作业在单个事务中执行,以便识别所有需要每月报告的用户,并安排作业通知他们 如何立即安排作业在创建它们的作业之后立即执行? 我用的是Spring 3.2