《大数据开发》专题
-
在oracle SP中用更大的数据类型替换varchar2
我使用的是oracle verion 10。PL/SQL中存在使用varchar2变量的存储过程。代码不断追加varchar2变量。当varchar2变量大小超过32767时,它不能追加任何值。现在我想将数据类型更改为long或clob(为了容纳更多的字符),但它不起作用。如何修改这里的代码,使其具有与clob或LONG相同的附加功能? 示例附加x:=x'mydata';
-
将大量数据写入 TD 引擎时出现问题
我正在尝试将我的应用程序移植到TDEngine,该应用程序通过其无模式接口将ImpxDb数据写入TDEngine。我认为这应该很容易,但实际上并不容易。 爪哇代码如下: 我在控制台上得到了结果: 传感器,设备 Id=传感器0 电流=10.2,json$j=“{”f6“:”tt“,”f7“:”aa“,”f0“:”tt“,”f1“:”aa“,”f2“:”tt“,”f3“:”aa“,”f4“:”tt“,
-
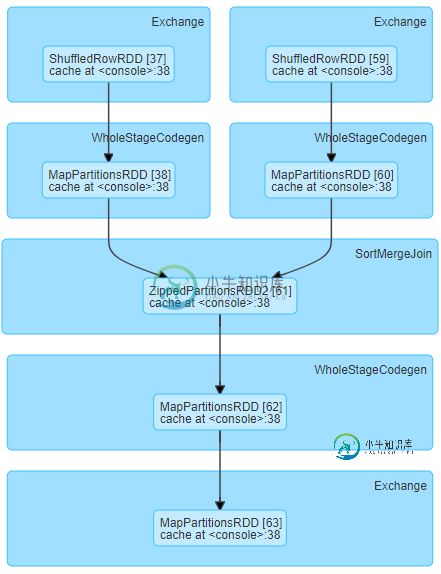 火花洗牌读取小数据需要大量时间
火花洗牌读取小数据需要大量时间我们正在运行以下阶段DAG,对于相对较小的洗牌数据大小(每个任务约19MB),我们经历了较长的洗牌读取时间 一个有趣的方面是,每个执行器/服务器中的等待任务具有等效的洗牌读取时间。这里有一个例子说明了它的含义:对于下面的服务器,一组任务等待大约7.7分钟,另一组等待大约26秒。 这是同一阶段运行的另一个例子。该图显示了3个执行器/服务器,每个执行器/服务器具有相同的洗牌读取时间的统一任务组。蓝色组
-
优化数据流池大小以提高点火性能
我正在使用ignite2.6,其中有数据流节点,从kafka消耗数据并放入Ignite缓存。服务器平均负载较高,吞吐量降低。 我已经尝试为缓存中定义的索引内联设置索引大小,这样可以提供良好的性能,但也增加了服务器内存利用率和较高的平均负载。请说明在这种情况下增加datastreamer线程池大小会产生什么影响。
-
如何确定Apache Spark数据帧中的分区大小
我一直在使用SE上发布的问题的一个极好的答案来确定分区的数量,以及跨数据帧的分区分布需要知道数据帧Spark中的分区详细信息 有人能帮我扩展答案来确定数据帧的分区大小吗? 谢谢
-
 思必驰大数据日常实习岗位面经(OC)
思必驰大数据日常实习岗位面经(OC)找了半个月的实习,面试了20多家,在同程HR面之后还被挂的惨痛经历之后,终于找到了一家不错的公司。(现在大环境下大数据实习太难找了,基本都是外包要人,BAT我都是一面挂,有些是简历挂) 下面讲讲我记得的一些问题 一面(40分钟) 自我介绍 熟悉二叉树吗,细说有多少种二叉树,哪些二叉树是用来排序的,并且将各个树的特点讲讲 了解MySQL存储引擎嘛,说说自己看法 计算机网络,TCP,UDP区别。Htt
-
 爱奇艺风控大数据Java日常实习(已OC)
爱奇艺风控大数据Java日常实习(已OC)选一个你觉得做的最好的项目,说一说 深挖项目,多问为什么这样设计,为什么这样做 选一个Java的项目,说一下 三级缓存是怎么实现的 那么一级缓存(nginx访问redis)和三级缓存redis的区别是什么,去掉了三级缓存可以么 介绍一下令牌桶算法数据结构,和漏斗桶的区别,为什么选令牌桶不用漏斗桶 如何保证mq消费者端更新数据库可以成功 如何保证消息可以不重复消费,使用redis做幂等是完全安全的么
-
 国企金融科技部门大数据实习面经
国企金融科技部门大数据实习面经目前已offer。 面试内容: 1.自我介绍:我就说了一下学校专业学的课然后之前的几段实习是做什么的。 2.SQL:这一块没有问具体的题目,问了一些窗口函数比如三个求rank的函数,sum() over 和groupby求和的区别,join后面跟where和on的区别,inner join 和left join使用场景这种,其他的记不清了。 3.Hadoop:问了Hadoop的组成,操作HDFS的
-
 中国移动技术中心(大数据方向)广州
中国移动技术中心(大数据方向)广州自我介绍 实习中遇到什么难题吗 项目中mq是用来做什么的 git命令 之前做过大数据的项目吗 就15min,也不知道咋筛人 但估计凉,因为没有大数据的项目
-
 海康研究院大数据算法工程师面经
海康研究院大数据算法工程师面经🧐背景:211交通工程出身,读研转到本校航运学院,做船舶交通大数据挖掘,涉及机器学习。 🧐自身情况:sci在投,一篇会议论文接受,一个专利发表。 🤐一志愿是九月初的技术支持工程师,因为后知后觉,发现不懂网络协议,没参加笔试。 👾10.25投大数据算法,以交通认知方向。笔试主要是机器学习内容,选择题,问答题,以及一道编程。 👾11.7日收到电话面试,讲了一下基本情况。 👾11.8日一面技
-
 大数据分析师应该具备的知识架构
大数据分析师应该具备的知识架构算法选取在算法选取方面,个人感觉也是要结合业务来实施。首先,要弄清楚业务那边主要关注的是什么指标。而与这一个指标相关的参数有那些,这些参数都是如何来影响这些指标的。至于算法的准确度,这一点,可以通过对数据颗粒度的细化来不断提高。不同的代码对系统的资源调度是不同的,而若你对算法的了解程度最大限度决定了你最终产品的反应快慢! 但据《财经》记者调查,这些有政府和国资背景的大数据交易所大部分生意寥寥,纯市
-
服务器 - 企业是怎么大量存储数据的?
英特尔的 至强处理器 及其对应的主板,能挂载的存储器数量是有限的,那企业是如何管理多个存储器的? 是通过交换机等网络设备实现的?还是通过服务器主板自带功能实现的(类似于 英特尔 至强处理器对应的主板 可以挂载两个CPU,是不是至强处理器主板间具有特殊的通讯方式?)
-
 已offer|携程大数据分析工程暑期实习
已offer|携程大数据分析工程暑期实习▫️Timeline:3.13投递 - 3.15完成综合考试 - 3.27请求转到第二志愿 - 4.11一面 - 4.21二面 - 4.25HR面+英语测评 - 4.26收offer ▫️bg:美本专业对口,一段相关实习,两个项目(1机器学习,1rfm) ▫️一面(~45mins) - 职业学业规划 - 回国时间&到岗时间&实习时长 - 自我介绍 - 介绍实习内容 - 实习怎么搭建指标体系 - 实
-
根据文件大小滚动时,将数据复制到 HDFS 需要时间
我有一个用例,我想使用flume将远程文件复制到hdfs中。我还希望复制的文件应与HDFS块大小(128MB/256MB)对齐。远程数据的总大小为33GB。 我使用avro源和接收器将远程数据复制到hdfs中。类似地,在接收端,我正在进行文件大小滚动(128,256)。但是从远程机器复制文件并存储到hdfs(文件大小128/256 MB)中,flume平均需要2分钟。 水槽配置:阿夫罗源(远程机器
-
最大并发socket.io连接数
因为Websockets构建在TCP之上,所以我的理解是,除非端口在连接之间共享,否则您将受到64K端口限制的约束。但我也看到过使用Gretty进行512K连接的报告。所以我不知道。