《大数据开发》专题
-
将大写应用于Python中Pandas数据框中的列
本文向大家介绍将大写应用于Python中Pandas数据框中的列,包括了将大写应用于Python中Pandas数据框中的列的使用技巧和注意事项,需要的朋友参考一下 在本教程中,我们将看到如何在DataFrame中使名称列变为大写。让我们看看实现目标的不同方法。 示例 我们可以使用upper()方法将其大写,从而为DataFrame分配一列。 让我们看一下代码。 输出结果 如果运行上面的程序,您将得
-
Spring Boot通过RESTendpoint将大型数据库导出到csv
我需要构建一个Spring Boot应用程序,它公开一个RESTendpoint,以将一个巨大的数据库表导出为具有不同过滤器参数的CSV文件。我正试图找到一个有效的解决这个问题的办法。 目前,我使用spring数据jpa查询数据库表,该表返回POJO列表。然后使用Apache Commons CSV将此列表作为CSV文件写入HttpServletResponse。这种方法有几个问题。首先,它将所有
-
如何使用Spring MySQL和RowCallbackHandler管理大型数据集
问题内容: 我正在尝试使用Spring和JdbcTemplate遍历MySQL中表的每一行。如果我没记错的话,它应该很简单: 我收到一个OutOfMemoryError,因为它试图读取整个内容。有任何想法吗? 问题答案: 在 javadoc中已经指出: 向JDBC驱动程序 提示 应从数据库中获取的行数 驱动程序实际上可以自由地应用或忽略提示。一些驱动程序忽略它,一些驱动程序直接应用它,一些驱动程序
-
特别大的数据量,如何实现查找,排序?
本文向大家介绍特别大的数据量,如何实现查找,排序?相关面试题,主要包含被问及特别大的数据量,如何实现查找,排序?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 1)、位图法 位图法是我在编程珠玑上看到的一种比较新颖的方法,思路比较巧妙效率也很高。 使用场景举例:对2G的数据量进行排序,这是基本要求。 数据:1、每个数据不大于8亿;2、数据类型位int;3、每个数据最多重复一次。 内存:最多
-
GCP数据流Kafka(作为Azure事件中心)->大查询
我有一个启用了Kafka的Azure Event Hub,我正试图从Google Cloud的数据流服务连接到它,以将数据流式传输到Google Big Query。我成功地可以使用Kafka CLI与Azure Event Hub交谈。但是,使用GCP,5分钟后,我在GCP数据流作业窗口中收到超时错误。 Azure EH已启用Kafka- 为了设置启用Kafka的事件中心,我遵循此GitHub页
-
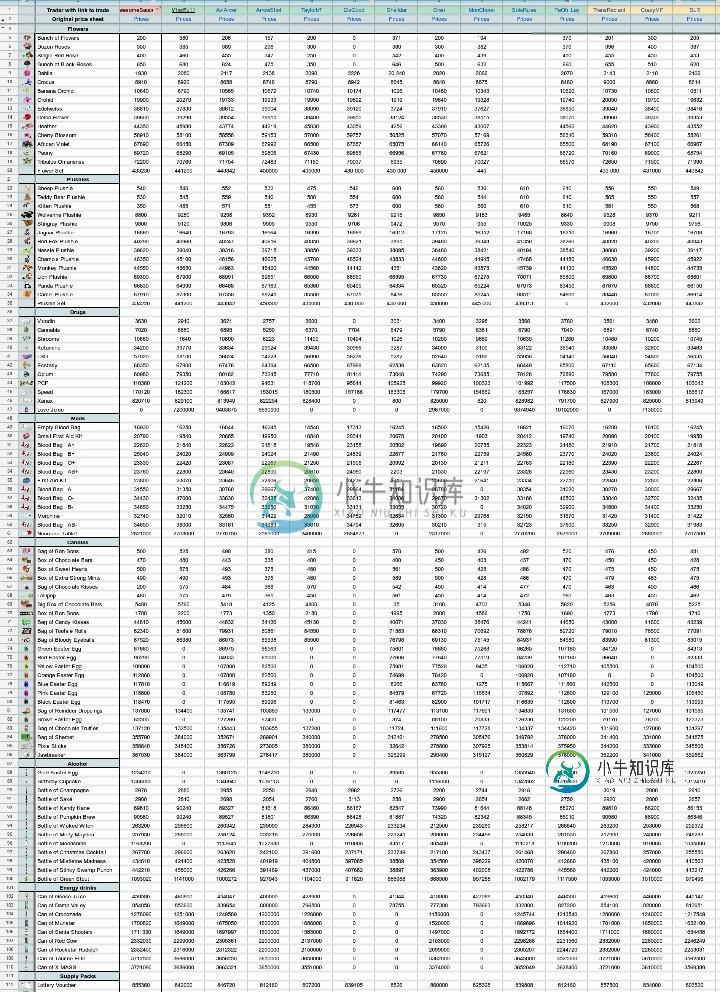 我无法从另一个大工作表导入数据
我无法从另一个大工作表导入数据我无法从我的另一张表中导入数据。它相当大,有超过500行和100列。(我不知道这是否重要,但它有大约50张,我想从第一个最大的导入) 导入TML和导入数据花费的时间太长,然后说源太大。 但我想要的是,它一直在说内部错误。 你对我如何导入数据有什么建议吗?甚至可能是如何更改源以便可以从中导入? 要导入到的工作表
-
错误414:如何处理GET返回的大量数据?
因此,我需要能够从数据库中返回大量数据以进行图形化。目前,我正在通过ajax使用GET,并通过php简单地生成必要的html。这对于少量数据很有效,但是每当我请求超过大约一年的数据时,我就会出现错误414。有人有更好的方法的建议吗,或者知道如何更改限制?谢谢。
-
spring数据cassandra中预处理语句的批量大小
我在日志中收到以下警告: WARN[本机传输请求:17058]2014-07-29 13:58:33776 BatchStatement。[keyspace.tablex]的java(第223行)批准备语句的大小为10924,超过了指定的阈值5120乘以5804。 有没有办法在Spring数据卡桑德拉指定大小? Cassandra 2.0.9和spring数据Cassandra 1.0.0-REL
-
如何在大型数据集中求全局平均值?
我正在编写简单的mapreduce程序来查找我的数据(许多文本文件)中存在的平均值,最小数字和最大数字。我想使用组合器首先在单个映射器处理的数字中查找所需的内容会使其更有效率。 然而,我关心的事实是,为了能够找到平均、最小数或最大数,我们将要求来自所有映射器(因此所有组合器)的数据进入单个缩减器,以便我们能够找到通用平均、最小数或最大数。这在较大数据集的情况下将是一个巨大的瓶颈。 我相信在hado
-
从不同数据类型的ArrayList中获取最大值
我正在开发一个程序,提示用户输入姓名、年龄和性别。该程序应该从每个输入中给我一个姓名、年龄和性别的列表,并告诉我谁是该列表中年龄最大的人。我已经创建了一个数组列表来保存这些值,我可以使用增强循环打印出姓名、年龄和性别。我遇到的问题是让程序打印出数组列表中最高(最老)的数字。我已经创建了一个替代方法,通过创建一个只有年龄的附加数组列表来实现这一点,但是我似乎没有找到从原始数组列表中获取这一点的方法。
-
如何利用Java高效编制大数据映射表
考虑我有两个表的场景,和。我想创建第三个表,它只是一个包含两列的映射表,和的主键。表A和表B分别包含8000万条和1.5亿条记录。目前,我在DB2(即我的DB)中编写了一个存储过程,它将首先连接和选择两个表中的记录,并使用游标进行迭代。在这个迭代过程中,我将插入到第三个表中,并执行一个中间提交。 现在,这个存储过程运行了很长时间(大约5小时)来完成这个操作,因为在DB2存储过程中不可能插入多行(这
-
Azure Database ricks中DBFS的数据大小限制是多少
我在这里读到,AWS数据砖的存储限制为单个文件的5TB,我们可以存储任意数量的文件,那么同样的限制是否适用于Azure数据砖?或者,是否对 Azure 数据砖应用了其他限制? 更新: @CHEEKATLAPRADEEP感谢您的解释,但是,有人能分享一下背后的原因吗:“我们建议您将数据存储在挂载对象存储中,而不是DBFS根目录中” 我需要在Power BI中使用DirectQuery(因为数据量巨大
-
将数据从非常大的文本文件导入JTable
我正在制作一个应用程序,它处理存储在文本文件中的大量数据。本质上,应用程序浏览一个. txt文件,一旦找到,应用程序需要把文件中的所有数据放入JTable,然后我需要对数据执行一些过滤操作,然后将其导出。. txt文件中的数据格式如下: 有数千行。每行由双类型数字组成(A、B……均为1.3、2.0等) 我通过手动添加数组中的所有列名,然后将表的模型设置为 我已经把行作为'空'在这里,因为我不知道我
-
过滤大型数据帧的更快方法是什么?
我想对大约40万行的数据帧进行排序,其中包含4列,用if语句取出大约一半: 到目前为止,我一直在测试以下4个中的任何一个: 或与.loc相同 或者将if(非in)改变为if(in)并使用: 或者尝试将emptyline设置为具有值,然后将其附加: 因此,从我到目前为止设法测试的内容来看,它们似乎在少量行(2000)上都可以正常工作,但是一旦我开始获得更多的行,它们所需的时间就会呈指数级增长。.at
-
如何使用Realm解析大型JSON并存储数据
我真的被阻止使用Realm解析和存储数据,我有一个大的JSON,我创建了所有的类模型,就像RealM的例子一样。 这是我的错误:由:org引起。json。JSONException:io的0处的值fr。领域例外。RealmException:无法在io上映射Json。领域领域com上的createObjectFromJson(Realm.java:860)。实例截击2。ImagesActivity