《大数据开发》专题
-
向Cassandra写入大火花数据帧-性能调整
我在Spark 2.1.0/Cassandra 3.10集群(4台机器*12个内核*256个RAM*2个SSD)上工作,很长一段时间以来,我一直在努力使用Spark Cassandra connector 2.0.1向Cassandra写入特定的大数据帧。 这是我的表的模式 用作主键的散列是256位;列表字段包含多达1MB的某种结构化类型的数据。总共,我需要写几亿行。 目前,我正在使用以下写入方法
-
使用熊猫的“大数据”工作流[已关闭]
在学习熊猫的过程中,我已经尝试了好几个月来找出这个问题的答案。我在日常工作中使用SAS,这是非常好的,因为它提供了非核心支持。然而,SAS作为一个软件是可怕的,原因还有很多。 有一天,我希望用python和熊猫取代SAS,但我目前缺乏大型数据集的核心外工作流。我说的不是需要分布式网络的“大数据”,而是文件太大,无法放入内存,但又小到足以放入硬盘。 我的第一个想法是使用在磁盘上保存大型数据集,只将我
-
使用Sqoop将大型机数据摄取到Hadoop中
我发现SQOOP1.4.6可以连接到大型机,它可以从大型机PDS中提取数据,并将其放入hdfs/hive/hbase或accolumo中。 我想知道它是支持打包的十进制数据类型还是只支持简单的数据类型?有人能帮我了解一下SQOOP1.4.6支持什么大型机文件格式吗? 提前致谢 参考https://sqoop.apache.org/docs/1.4.6/sqoopuserguide.html
-
分析Protobuf与JSON并遇到数据大小问题
在Java,我的任务是查看JSON格式与Protobuf格式相同的数据的数据大小和处理速度(创建数据的速度)。 对于JSON,我使用了jackson,创建了一个类,其中包含一个字段,称为subscriptionlist。每个将对应于一个订阅。我从一个文件中读取,每一行都是“”字段分隔的,有523个字段。我遍历每个字段,为键指定订阅列名,为值指定列值。我遍历每一行以创建所有1000个订阅,将它们放入
-
Cucumber:场景大纲-在运行时访问数据表
在我们的cucumber特性文件中,我们使用了场景大纲,在运行脚本之前,我们需要在运行时填充数据。 基于数据文件中传递的城市路线,我们使用一个API创建PNR,该API返回给我一个实际的PNR。创建的PNR值需要存储在场景数据表中。 如果我们有场景,我们可以使用DataTable函数访问函数内部的值。我们有任何类与场景大纲数据表交互吗 例如。 请让我知道如果现有的类或替代方案来解决这个问题。
-
处理大型数据对象,应该释放CLOB吗?
我使用Oracle数据库和驱动程序,我使用从ResultSet获取Clob,然后在方法中将其转换为String:
-
不同大小数据帧的合并和重复值
我需要合并两个不同大小的数据帧。较大的一个()有一列有几个重复的值(),较短的一个()有列,但其值不重复。df2还有一个ID列。我需要在中使用中的ID的新列,根据中的重复值重复。下面的例子可能会让它更清楚。 .
-
 上海银行 总行科技大数据岗 笔试
上海银行 总行科技大数据岗 笔试lz投递的是数据开发工程师方向 1. 笔试共两个半小时,分为两个部分 2. 第一部分是行测,共60道题目,具体题型分布不太记得了,限时60min 3. 第二部分是专业笔试,限时90min (1)单选 23题 (2)多选5题 (3)判断7题 单选、多选、判断主要考察数据库、Hadoop相关知识 (4)编程填空题18题 都是SQL题,难度适中#上海银行#
-
 【2023届】中国重汽-大数据技术与应用
【2023届】中国重汽-大数据技术与应用9.26投递——12.13面试 面试时间:6分钟 面试官:2人 自我介绍 论文专利情况 有没有法律、财务方面的学习(???我不懂) 介绍一下毕业设计 高考分数、生源地 在校期间获奖情况 是否参加学生会 是否接受地点、岗位调剂
-
 人大金仓数据库测试一面面经(10.26)
人大金仓数据库测试一面面经(10.26)1.自我介绍 2.数据库语言,DDL,DQL,DML... 3.考察数据库语言,建表,更改等 4.事务的四大特性 5.利用session模拟读已提交(完蛋,一点都不会) 6.对隔离的理解 7.项目中你如何进行测试,自己的项目 8.使用什么进行测试的,Jmeter 9.Jmeter怎么进行并发的检测,设置线程数(问性能测试) 10.linux的基本命令 11.软件测试模型VW 12.熟悉python
-
 8.5快手数据分析一面(大概率凉凉)
8.5快手数据分析一面(大概率凉凉)#快手信息集散地##快手##数据分析##秋招# 全程大概50mins 1、自我介绍 2、实习内容 主要关注哪些核心指标 异动分析怎么排查,怎么归因 有没有给业务侧做过有用的决策/数据支持 实习中最大的收获 公司和竞品公司的一个对比,优势是什么 3、手撕代码 指定日期的产品价格(详细可去**找,貌似有原题) 没撕出来呜呜呜呜呜,大概率寄了😭😭😭 4、对以后的发展规划,包括城市/行业 对数分岗位
-
 宁德时代大数据算法工程师一面
宁德时代大数据算法工程师一面上来先自我介绍然后让自己挑一个项目介绍。后续面试官问了很多问题 1 特征工程如何做 2 特征筛选都有哪些介绍一下 3 随机森林原理 4 支持向量机介绍一下 5 深度学习框架会哪些介绍一下 6 transformer介绍 7 attention机制都有哪些介绍一下 8 lstm原理以及相比于rnn的优势 9 时间序列预测都有哪些方法 10 介绍一下arima算法 11 数据库都会哪些 12 深度学习
-
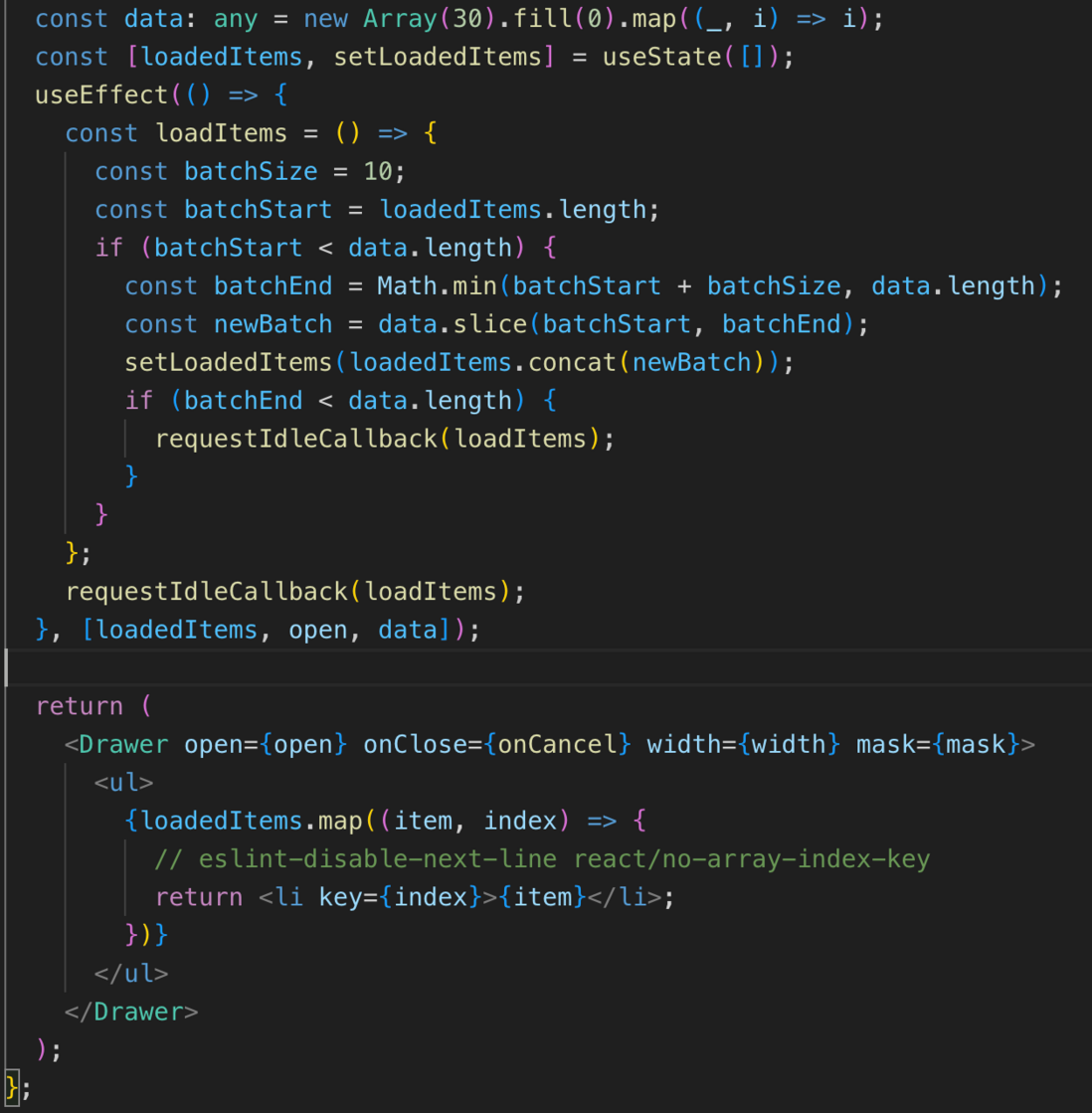 javascript - React中使用requestIdleCallback优化大量数据渲染?
javascript - React中使用requestIdleCallback优化大量数据渲染?如何在react中使用requestIdleCallback来实现大量数据的渲染优化? 目前通过这种方式处理之后最后一组数据屏幕一直闪烁,请教一下大佬们。 这里只是测试的数据,之所以没采用虚拟列表是因为真实数据中的每一项的高度不固定,虚拟列表处理起高度计算有点复杂。
-
 腾讯云智大数据前端 hr面经+许愿
腾讯云智大数据前端 hr面经+许愿#许愿# ★日期:5.13 一、自我介绍 二、了解个人信息和求职意愿 1. 你是哪里人?学校在哪里? 2. 你知道我们公司的base地点都有哪些吗?你知道你正在面的部门base是哪里吗? 3. 你能谈谈对武汉的看法吗?如果把国内城市排个序,你怎么排? 4. 能接受来武汉实习吗? 5. 二线城市的话,薪资会比一线城市少不少哦 6. 你现在有收到哪些offer? 7. 为什么没有打算考研? 8. 你的
-
python - psycopg2处理大数据量SQL在execute(sql)卡死?
题目描述 sql='select * from A',A表有8百万数据 前段时间写了数据库互相导数据的Python脚本,是Oracle导入postgreSQL,使用cx_Oracle执行execute(sql)没有任何问题。这次是postgreSQL导入postgreSQL,使用psycopg2执行execute(sql)就直接卡死在这一行了,并且内存占用持续上升。 自己的思路 数据库连接是没有问