《大数据开发》专题
-
使用J2ME存储大量数据的最佳实践
问题内容: 我正在开发一个J2ME应用程序,该应用程序具有要存储在设备上的大量数据(大约1MB,但是可变)。我不能依靠文件系统,所以我卡住了记录管理系统(RMS),该系统允许多个记录存储,但每个记录存储空间都有限。我最初的目标平台Blackberry将每个限制为64KB。 我想知道是否还有其他人必须解决在RMS中存储大量数据的问题,以及他们如何进行管理?我正在考虑必须计算记录大小并在多个存储区中拆
-
Java:将大量数据序列化为单个文件
问题内容: 我需要将大量小对象的数据(大约2gigs)序列化为单个文件,以便稍后由另一个Java进程进行处理。性能是很重要的。谁能建议一个好的方法来实现这一目标? 问题答案: 您是否看过Google的协议缓冲区?听起来像是一个用例。
-
 mysql大数据查询优化经验分享(推荐)
mysql大数据查询优化经验分享(推荐)本文向大家介绍mysql大数据查询优化经验分享(推荐),包括了mysql大数据查询优化经验分享(推荐)的使用技巧和注意事项,需要的朋友参考一下 正儿八经mysql优化! mysql数据量少,优化没必要,数据量大,优化少不了,不优化一个查询10秒,优化得当,同样查询10毫秒。 这是多么痛的领悟! mysql优化,说程序员的话就是:索引优化和where条件优化。 实验环境:MacBook Pro MJ
-
如何将巨大的pandas数据帧保存到HDFS?
问题内容: 我正在处理熊猫和Spark数据帧。数据帧始终很大(> 20 GB),而标准的火花功能不足以容纳这些大小。目前,我将我的pandas数据框转换为spark数据框,如下所示: 我进行这种转换是因为通过火花将数据帧写入hdfs非常容易: 但是,对于大于2 GB的数据帧,转换失败。如果将spark数据框转换为熊猫,则可以使用pyarrow: 这是从Spark到Panda的快速对话,它也适用于大
-
 Python对接六大主流数据库(只需三步)
Python对接六大主流数据库(只需三步)本文向大家介绍Python对接六大主流数据库(只需三步),包括了Python对接六大主流数据库(只需三步)的使用技巧和注意事项,需要的朋友参考一下 作为近两年来最火的编程语言的python,受到广大程序员的追捧必然是有其原因的,如果要挑出几点来讲的话,第一条那就python语法简洁,易上手,第二条呢? 便是python有着极其丰富的第三方的库。 所以不管你使用的关系型数据库是oracle,mysq
-
将大熊猫数据帧分块写入CSV文件
问题内容: 如何将大数据文件分块写入CSV文件? 我有一组大型数据文件(1M行x 20列)。但是,我只关注该数据的5列左右。 我想通过只用感兴趣的列制作这些文件的副本来使事情变得更容易,所以我可以使用较小的文件进行后期处理。因此,我计划将文件读取到数据帧中,然后写入csv文件。 我一直在研究将大数据文件以块的形式读入数据框。但是,我还无法找到有关如何将数据分块写入csv文件的任何信息。 这是我现在
-
php快速导入大量数据的实例方法
本文向大家介绍php快速导入大量数据的实例方法,包括了php快速导入大量数据的实例方法的使用技巧和注意事项,需要的朋友参考一下 PHP快速导入大量数据到数据库的方法 第一种方法:使用insert into 插入,代码如下: 最后显示为:23:25:05 01:32:05 也就是花了2个小时多! 第二种方法:使用事务提交,批量插入数据库(每隔10W条提交下)最后显示消耗的时间为:22:56:13 2
-
如何在非常大的数据集上训练Word2vec?
问题内容: 我正在考虑对word2vec进行Web爬网转储上超过10 TB +大小的海量大规模数据的培训。 我对iMac上的c实现GoogleNews-2012转储(1.5gb)进行了亲自培训,花了大约3个小时来训练和生成矢量(对速度印象深刻)。我没有尝试python实现:(我在某处读到,在300个矢量长度的wiki dump(11gb)上生成矢量大约需要9天的时间来生成。 如何加快word2ve
-
 Oracle的CLOB大数据字段类型操作方法
Oracle的CLOB大数据字段类型操作方法本文向大家介绍Oracle的CLOB大数据字段类型操作方法,包括了Oracle的CLOB大数据字段类型操作方法的使用技巧和注意事项,需要的朋友参考一下 一、Oracle中的varchar2类型 我们在Oracle数据库存储的字符数据一般是用VARCHAR2。VARCHAR2既分PL/SQL Data Types中的变量类型,也分Oracle Database中的字段类型,不同场景的最大长度不同。
-
如何在MAMP上导出/导入大型数据库
问题内容: 如何在MAMP上导出/导入大型数据库?使用PHPMyAdmin无法正常工作。 问题答案: 应该通过如下所示的终端来完成。 在终端中,使用以下命令导航到MAMP的文件夹 使用此命令导出文件。EG将是 行应该出现在说。在这里输入MySQL密码。请记住,这些字母不会出现,但是它们在那里。 如果需要导入,请使用BigDump,这是一个MySQL Dump Importer。
-
一种基于scikit-learn的大数据集热编码
我有一个大数据集,我计划对其进行逻辑回归。它有很多分类变量,每一个都有成千上万的特征,我计划在这些特征上使用一个热编码。我将需要处理小批量的数据。我的问题是如何确保一个热编码在第一次运行时看到每个分类变量的所有功能?
-
tf.data.数据集如何动态传递tf.io.FixedLenFeature的大小
我们有tfrecord文件,其中每个tfrecord文件都包含一个示例,但其中的功能包含一个值列表。我们正在使用以以下方式: 我们希望查找给定文件路径的行数,而不是对使用固定常量。 关于如何实现这一点有什么想法吗? 我们试着用这样的东西 但这失败了,因为tf。直到需要时,数据才会急切地评估文件路径(即,它仍然是一个tf.Tensor)
-
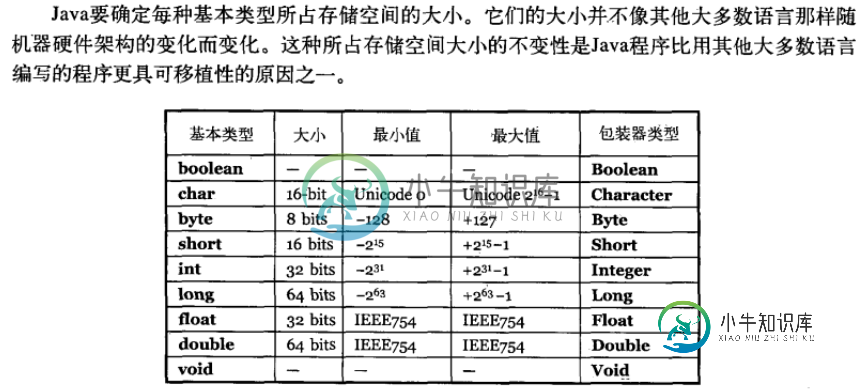 Java 的8种基本数据类型 及其大小?
Java 的8种基本数据类型 及其大小?本文向大家介绍Java 的8种基本数据类型 及其大小?相关面试题,主要包含被问及Java 的8种基本数据类型 及其大小?时的应答技巧和注意事项,需要的朋友参考一下
-
Spark如何处理大于集群内存的数据
如果我只有一个内存为25 GB的执行器,并且如果它一次只能运行一个任务,那么是否可以处理(转换和操作)1 TB的数据?如果可以,那么将如何读取它以及中间数据将存储在哪里? 同样对于相同的场景,如果hadoop文件有300个输入拆分,那么RDD中会有300个分区,那么在这种情况下这些分区会在哪里?它会只保留在hadoop磁盘上并且我的单个任务会运行300次吗?
-
Cloud SQL中大容量加载数据的ETL方法
我需要将数据ETL到云SQL实例中。这些数据来自API调用。目前,我正在Kubernetes中用Cronjobs运行一个自定义Java ETL代码,它请求收集这些数据并将其加载到Cloud SQL上。这个问题与管理ETL代码和监视ETL作业有关。当合并更多ETL进程时,当前的解决方案可能无法很好地扩展。在这种情况下,我需要使用ETL工具。 我的Cloud SQL实例包含两种类型的表:公共事务性表和