《大数据开发》专题
-
如何计算spark scala中的数据帧大小
我想编写一个具有重分区的大型数据帧,所以我想计算源数据帧的重分区数。 数据帧/default_blocksize的大小 所以请告诉我如何在spark scala中计算数据帧的大小 提前谢谢。
-
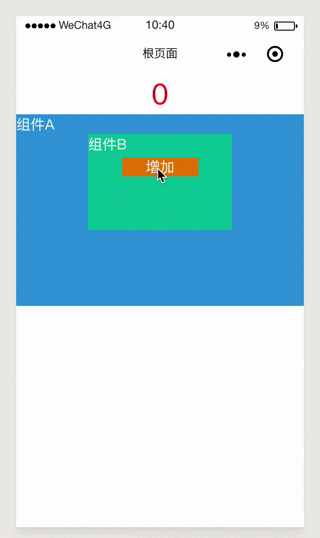 小程序数据通信方法大全(推荐)
小程序数据通信方法大全(推荐)本文向大家介绍小程序数据通信方法大全(推荐),包括了小程序数据通信方法大全(推荐)的使用技巧和注意事项,需要的朋友参考一下 序 本文论述的是子或孙向父传递数据的情况,自下而上 相信大家平时在小程序开发中肯定遇到过页面或者组件之间的数据通信问题,那小程序数据通信都有哪些方式呢?如何选择合适的通信方式呢?这就是本文要讨论的重点。 关系划分 在讨论都有哪些数据通信方式之前,我们先来定义一下,小程序页面、
-
如何在数据库中保存图像大小?
我需要在数据库中按kb保存大小,以便在前端查看,这是我正在使用的控制器。我使用的是Laravel 5.8 所以我的问题是,拉雷维尔是否提供了处理这种情况的任何假象?或者任何其他框架都有更适合问题的功能是什么?
-
在Spring batch中以块级存储大量数据
我刚接触spring,对spring了解不多,请帮我解决这个问题。我的用例是:我们使用spring batch和面向块的处理来处理数据。 在每个处理块的末尾(即,一旦满足提交间隔并将值传递给写入器),必须存储值列表,以便在整个tasklet完成后,必须使用存储的值列表将值写入csv文件。如果在块处理中发生了任何作业失败,那么将值列表写入文件就不应该发生。
-
JQuery、AJAX、PHP传递大量数据导致错误
我正在尝试使用AJAX将页面中的大量数据传递给PHP脚本。这对于一些少量的数据来说很好,但是当有更多的数据时会出现以下错误。 我正在使用的JQuery是: 数据实际上是一个json数据字符串。 并在PHP中读取,只需使用: 我怎么能传递大量的数据链接这个,但仍然使用$_POST在PHP中引用它 我以为我需要用JSON做一些事情,但我可以弄清楚什么。 谢啦
-
以块为单位更新大型sqlite数据库
我有一个sqlite数据库(大约11GB),它有多个表,包括表和。表相当大(1.2亿行),较小(15000行)。我想在python中使用sqlite3通过
-
Spring Batch从Rest web服务读取大量数据
例如:如果我在01012020和01012021之间调用它,我将获得8000万个数据。 PS:web服务按一天的分页方式工作,也就是说,如果我想检索01/09/2020到07/09/2020之间的数据,我必须调用它几次(01/09-02/09之间,然后02/09-03/09之间,依此类推,直到06/09-07/09) 在这种情况下,如果数据很大,我的问题是堆空间内存。
-
弹性搜索河无法处理大量数据
我有一个问题,在elasticsearch与mongob建立河流。如果日期的大小在一百万以内,我可以从mongob导入数据。但是当数据很大1000万或更大时,河流无法索引来自mongob集合的所有记录。 我在日志中看到这个错误 通常说river stale是错误的几次。此外,我在mongodb设置中的oplog大小为1024MB。
-
 大熊猫。数据帧输出表格式配置
大熊猫。数据帧输出表格式配置在哪里可以配置Jupyter,使DataFrame对象在默认情况下显示为带边框的完整表? 现在看起来是这样的:
-
CPU百分比大于100的Docker统计数据
我通过从Jmeter发送请求来强调容器,然后通过docker stats命令监视容器的cpu使用情况,该命令给出的值大于100%。 我不明白为什么即使只给容器分配一个核心,它也会给出超过100%的!。你知道原因吗?这个cpu值是否表示除了容器之外的某些系统进程的cpu使用情况? 提前感谢你的帮助。 docker信息结果:集装箱:2运行:1暂停:0停止:1图像:10服务器版本:17.06.0-CE存
-
为自定义数据源设置光池大小
我想为我的自定义数据源更改光池大小,我使用的是Spring boot 2版本。 我可以设置数据源url,数据源密码等。我将值写入application.properties文件。之后,我用environment.getproperty读取这些值并设置dataSource,但是我不知道池大小的相同过程:(
-
带字符串验证的ByteBuf数据包大小?
每个包作为,操作码用于知道它是什么类型的包,例如操作码2是登录包。 所以登录包有一个操作码和两个字符串。例如,用户名最大长度为18,密码最大长度为12,因此登录数据包的大小必须为31。 但是当用户名小于18时会发生什么呢?如果我的密码是10,用户名是4,我的数据包大小将是15,根据系统检查将是非法的。 它在做什么?应该如何做?
-
优化两个大型pyspark数据帧的连接
我有两个包含GB数据的大型pyspark数据框df1和df2。第一个数据框中的列是id1,col1。第二个数据框中的列是id2,col2。数据框的行数相等。id1和id2的所有值都是唯一的。id1的所有值也正好对应一个值id2。 因为。前几个条目与df1和df2区域相同,如下所示 DF1: df2: 所以我需要连接键 id1 和 id2 上的两个数据帧。df = df1.join(df2, df1
-
将大型数据文件导入熊猫[副本]
我有一个1.5GB.dat文件需要作为pandas数据帧导入,我遇到了内存问题(8GB RAM)。如何将dat文件分解成块来执行分析?
-
如何在Talend大数据工作中迭代tHiveInput?
有没有一种方法可以在talend大数据工作中迭代一个TiveInput?