《大数据开发》专题
-
 某大厂Java开发面经
某大厂Java开发面经总结,1h的面试把我面的满头大汗,小姐姐声音很温柔,人很好,就是我太菜(* ̄︶ ̄) 1.自我介绍 2.Java中的继承和多态 接口和抽象类的区别 StringBuffer和StringBuilder的区别 String为什么不能拆分 3.error和exception的区别 怎么处理exception 4.什么是泛型 泛型的作用 泛型的使用方式有哪几种(答得模棱两可) 5.HashMap的遍历方式
-
 大疆测试开发一面
大疆测试开发一面腾讯会议面试 1.自我介绍 2.你对于测试开发的理解?为什么选择测试开发? 3.你最满意的一件事。 4.对大疆有什么了解 常用语言的考察 5.python给自己打几分 6.python字典怎么合并?dict.update() 7.python列表怎么反转?列表名.reverse() 8.python里面有指针吗? 9.python迭代器?生成器? 反问
-
 大疆后端开发笔试
大疆后端开发笔试做过这么多笔试最简单的 选择题12道,交换机在第几层之类的题目 算法:给个矩阵,格子带权,找到从左上到右下的权值为正的最小值 二维dp两分钟a了 选做题:10亿图片存储,什么方案,怎么查找,怎么优化 我写了分布式存储➕特征识别,不知道行不行
-
 阿里大文娱 Java开发
阿里大文娱 Java开发1.一分钟自我介绍 2.你项目中遇到的最大难点是什么?技术上面 3.RabbitMQ消息队列的原理 4.在哪些场景中使用到AOP? 5.Spring Security在项目中如何使用?怎么达到URL级别的控制 6.项目中有没有用到设计模式? 7.支付宝支付中如果想添加外卡支付之类的扩展应该采用哪种设计模式? 8.死锁是怎么产生的?然后我们在开发过程中有什么措施能够避免死锁? 9.了解线程池吗?说一
-
数据透视表还是大熊猫分组依据?
问题内容: 我有一个非常希望直截了当的问题,在最近3个小时中,这一直给我带来很多困难。应该很容易。 这是挑战。 我有一个熊猫数据框: 我想要将数据框转换为: 值是值计数。有人有见识吗?谢谢! 问题答案: 这是重塑数据的几种方法 1) 使用 2) 或者,在over上使用,然后填充零。 3) 或者使用与, 4) 或者,与
-
按数字搜索从Spring数据jpa开始
我使用的是Spring数据jpa,MySQL。我有以下实体 Mysql表如下所示, 我想搜索所有
-
针对广大开发人员的并行开发
Subversion 中的分支、标记和合并 虽然很多开发团队都使用版本控制系统管理代码变更,但当多个开发人员并行地使用不同的代码库进行编码时,还是会出现问题的。在本期的 让开发自动化 中,自动化专家 Paul Duvall 展示了如何运用开源的、免费的 Subversion 版本控制系统来有效地进行标记、分支和合并。 说到源代码分支,可以将大多数的软件开发团队大致划分为两大阵营:有些是根本不分支;
-
如何将大熊猫的每月数据转换为季度数据
问题内容: 我有月度数据。我想将其转换为1月份从1月份开始的3个月的“期间”。因此,在下面的示例中,前三个月的汇总将转换为q2的开始(所需格式:1996q2)。而将三个月度值汇总在一起而得出的数据值是三列的平均值。从概念上讲,并不复杂。有谁知道如何一口气做到这一点?潜在地,我可以通过循环来做很多艰苦的工作,并从中进行硬编码,但是我是熊猫的新手,正在寻找比暴力更聪明的东西。 所以我在寻找: 问题答案
-
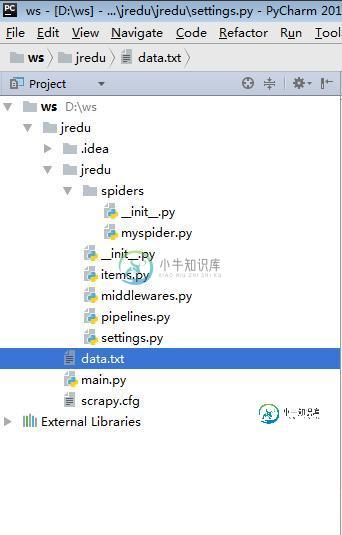 Python大数据之从网页上爬取数据的方法详解
Python大数据之从网页上爬取数据的方法详解本文向大家介绍Python大数据之从网页上爬取数据的方法详解,包括了Python大数据之从网页上爬取数据的方法详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python大数据之从网页上爬取数据的方法。分享给大家供大家参考,具体如下: myspider.py : items.py : middlewares.py : pipelines.py : settings.py
-
将大型本地数据库与服务器数据库同步(MySQL)
问题内容: 我需要每周将一个大型(3GB + / 40+个表)本地MySQL数据库同步到服务器数据库。这两个数据库完全相同。本地数据库会不断更新,每周大约需要用本地数据更新服务器数据库。您可以将其称为“镜像数据库”或“主服务器/主服务器”,但是我不确定这是否正确。 现在,数据库仅在本地存在。所以: 1)首先,我需要将数据库从本地复制到服务器。由于数据库大小和PHPMyAdmin的限制,使用PHPM
-
在其他数据框中查找最近点(包含大量数据)
问题很简单,我有两个数据帧: > 一个有90000套公寓和他们的经纬度 还有一个有3000个药房和他们的经纬度 我想为我所有的公寓创建一个新变量:“最近药房的距离” 为此,我尝试了两种花费大量时间的方法: 第一种方法:我创建了一个矩阵,我的公寓排成一行,我的药店排成一列,它们之间的距离在交叉点上,然后我只取矩阵的最小值,得到一个90000值的列向量 我只是用了一个双人床来搭配numpy: ps:我
-
pytorch下大型数据集(大型图片)的导入方式
本文向大家介绍pytorch下大型数据集(大型图片)的导入方式,包括了pytorch下大型数据集(大型图片)的导入方式的使用技巧和注意事项,需要的朋友参考一下 使用torch.utils.data.Dataset类 处理图片数据时, 1. 我们需要定义三个基本的函数,以下是基本流程 这里,我将 读取图片 的步骤 放到 __getitem__ ,是因为 这样放的话,对内存的要求会降低很多,我们只是将
-
弹性搜索未提供大量的页面大小数据
问题内容: 要获取的数据大小:大约20,000 问题:在python中使用以下命令搜索Elastic Search索引数据 但没有得到任何结果。 如果我给的尺寸小于或等于10,000,则可以正常工作,但不能与20,000相匹配, 请帮助我找到最佳的解决方案。 PS:在深入研究ES时发现此消息错误: 结果窗口太大,从+大小必须小于或等于:[10000],但为[19999]。有关请求大数据集的更有效方
-
mysql 大表批量删除大量数据的实现方法
本文向大家介绍mysql 大表批量删除大量数据的实现方法,包括了mysql 大表批量删除大量数据的实现方法的使用技巧和注意事项,需要的朋友参考一下 问题参考自:https://www.zhihu.com/question/440066129/answer/1685329456 ,mysql中,一张表里有3亿数据,未分表,其中一个字段是企业类型,企业类型是一般企业和个体户,个体户的数据量差不多占50
-
infinispan文件存储大小与数据大小不成比例
我编写了一个小型infinispan缓存PoC(下面的代码),以尝试评估infinispan的性能。运行它时,我发现对于我的配置,infinispan显然无法从磁盘中清除缓存项的旧副本,导致磁盘空间消耗比预期的要多几个数量级。 如何将磁盘使用率降低到实际数据的大致大小? 以下是我的测试代码: 这是infinispan配置: Infinispan(应该是?)配置为写入缓存,其中包含RAM中的20个最