《大数据开发》专题
-
 大数据实习面试记录
大数据实习面试记录#数据人的面试交流地# 十方融海 大数据开发实习生(秋招提前批) 一面:2022/05/30 自我介绍 this super 值和引用 垃圾回收算法 多线程用过吗 回收算法 进程线程 Linux子系统: linux内核的子系统有5个: 1、 进程调度控制系统(SCHED); 2、内存管理系统(MM),主要作用是控制多个进程安全地共享主内存区域; 3、虚拟文件系统(VFS); 4、网络接口(NET)
-
 大数据实习面试记录
大数据实习面试记录#数据人的面试交流地# 广州丰石科技 大数据开发实习生 2022/06/07 一面:感觉就是kpi 进去之后做一份面试题,hr叫我做小题,后边的大题不需要做,做完之后面试的时候给面试官看,第一句就是后面的题不会做吗? 蚌埠住了。。。 自我介绍 spark中数据迟到怎么处理 hive权限管理 cdh kafka分区策略 sparkstream对接kafka的方式, hashmap键和值允许为空吗,
-
 大数据实习面试记录
大数据实习面试记录#数据人的面试交流地# 赫基集团 大数据开发实习生 一面:电话面 2022/06/21 1.sql判断是否有重复数据 2.数据库引擎的区别 3.说一下项目 4.项目中转化率数据异常怎么进行清除 二面:主管加hr面 2022/06/31 项目和经历 建模(雪花模型和星型模型) 渐变字段 笛卡尔积用在什么场景?没想出来,最后面试官说这是个坑,说没人愿意遇见笛卡尔积 还有普遍hr问题 反问 科大讯飞 A
-
 秋招大数据面试记录
秋招大数据面试记录#数据人的面试交流地# 中数通 数据岗 2022/11/02 毕设做好了吗,方向是什么 什么是大数据 用过的存储工具 Hadoop和hive的区别 用过的采集工具采集 数据的过滤是怎么做的,再flume定义的拦截器,json异常怎么进行处理 kafka是什么 用过的数据挖掘,体现再哪里 数据的展示 flume和spark分别是什么,什么时候采用 参加过的比赛 比赛中是如何完成,分工,时间,设计,流
-
 秋招大数据面试记录
秋招大数据面试记录#数据人的面试交流地# 2022/09/30 闻泰科技 大数据开发 一面: 为什么当程序员? 加班接受? 家人愿意让你去深圳发展吗? 职业规划 mysql: 索引了解吗 性别适合做索引吗,经常改变的字段适合做索引吗 MySQL的锁 事务的四大特性 事务内增删查改的语句是按顺序执行的吗 视图是什么 数据是怎么存储的 hive:hive在hdfs上的存储格式 怎么看hive表的存储路径 show ta
-
8. 大数据与机器学习
Kubernetes 在大数据与机器学习中的实践案例。
-
1.3.2 空间大数据可视化
空间可视化是地理大数据应用的最后一公里。它涵盖了一系列不同的规模,小到单个房产, 大到全球比例尺的海量地景数据的可视化。空间可视化充分利用了地理信息技术的空间数据可视化能力,用地图的方式进行可视化表达,解决了大数据中空间位置表达的问题;同时,利用地理信息技术的空间分析能力,为地理大数据涉及到的大量空间分析提供了处理能力,在空间维度上初步实现了大数据的分析。 区别于普通空间数据可视化,空间大数据可视
-
1.3.1 大数据可视化技术
数据可视化是关于数据视觉表现形式的科学技术研究。可视化技术是利用计算机图形学及图像处理技术,将数据转换为图形或图像形式显示到屏幕上,并进行交互处理的理论、方法和技术。它涉及计算机视觉、图像处理、计算机辅助设计、计算机图形学等多个领域,成为一项研究数据表示、数据处理、决策分析等问题的综合技术。 随着大数据时代的来临,信息每天都在以爆炸式的速度增长,其复杂性也越来越高;另外,随着越来越多科学可视化的需
-
查看数据库和表大小
在实例详细信息页面中,点击数据库和表部分下的“查看全部”。“数据库和表”页面会以列表显示服务器中的数据库和表和它们的大小。该列表按大小排序。点击左侧窗格中的实例以跳转到其数据库和表页面。
-
 云智 大数据中心一面
云智 大数据中心一面1.vue和react的区别和相同 2.cookie的生命周期前端在请求头里怎么设置 3.css的流式布局 4.css怎么让一个元素居中对齐 5.跨页面不同源的页面怎么通信(本地,不允许使用代理服务器) 6.node.js如何读取文件 7.node.js怎么利用服务器多核 8.sessionstroge和localstroge和cookie的区别 9.事件冒泡的机制 10.tcp的三次握手,四次挥
-
 中新赛克-大数据-一面
中新赛克-大数据-一面20分钟结束 八股:java——hadoop——hive, 再问一问源码有没有看过,如何调试,如何解决异常。
-
 金风科技大数据一面
金风科技大数据一面自我介绍 数据倾斜问题 spark的shuffle相对于mr的shuffle有什么区别 spark的stage怎么划分的 yarn中都有什么,作用是什么 hdfs读写流程 rpc和http分别是什么,有什么区别 项目中都有什么数据 数仓的分层,每层都做了什么事 反问 金风科技二面总经理面 自我介绍 总经理问题: 1.本科和研究生都是通信,为什么选择大数据 2.怎么在完成学业同时学习大数据的 2.对
-
 海康 大数据算法 二面
海康 大数据算法 二面【30min】自己提到推荐领域和数据挖掘领域,直接就问了两个领域比较熟悉的算法有什么,大概介绍一些 不会的: 1. XGB shrinkage 2. FM 算法为什么时间不高 3. 如何将用户之间和物品之间的特征加入协同过滤中(随便说了,特征拼接) 比较明确的问题: 1. 随机森林,提升树的区别 2. 随机森林如何构建?特征采样的好处 场景题 1. 给出手机的BOM结构图,对于预测手机销量和原材料
-
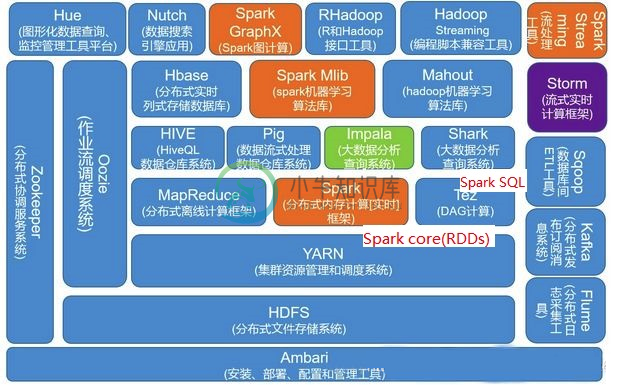 大数据生态圈的理解
大数据生态圈的理解HDFS是整个大数据架构的底层,它提供了一个文件系统 Spark(Spark core(RDD)) 和 MapReduce 是一个层级,是一种操作计算框架,MapReduce相当于一个别人写好的 java程序,它并不需要在服务器上启动相应的服务,甚至可以在本地run Hive => MapReduce Hive 操作MapReduce(底层是 MapReduce) Spark SQL=> Spar
-
 京东健康大数据算法
京东健康大数据算法已挂 一面 没有自我介绍,直接开问; 八股考的比较多,论文和实习经历都没怎么问 lgbm和xgboost的区别 RNN, GRU, LSTM之间的差别 为什么RNN容易梯度爆炸? 进程的通信方式 介绍下进程和线程 进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位 死锁的四个必要条件 互斥条件:一个资源每次只能被一个进程使用; 请求与保持条件: 一个进程因请求资源而阻塞时,对