《大数据开发》专题
-
 特斯拉数据开发技术面
特斯拉数据开发技术面#软件开发2024笔面经# 1说说你对数仓里分层的理解,越详细越好? 2说说你对数仓里数据建模的认知理解,越详细越好? 3之前做过数仓么? 4请简要说明什么是数据仓库,以及它与数据库的主要区别。 5列举几种常见的数据抽取、转换和加载(ETL)工具,并简述其特点。 6如何处理数据中的缺失值?请举例说明至少两种方法。 7讲一讲你对分布式数据处理框架(如 Hadoop、Spark 等)的理解。 8在大数
-
 美团一面凉经 | 数据开发
美团一面凉经 | 数据开发笔试 90min 选择题+sql*1+算法*2 简单sql,困难算法 一面 共 50min 自我介绍 sql 3小问 15min 实习经历 项目经历 数仓分层的意义 从hdfs如何到ODS层 介绍维度表和事实表 有没有使用zookeeper hadoop节点之间如何进行联系 hive sql脚本是在哪里运行 一共有多少张表,都是自己写的吗 做数仓的时候遇到了哪些困难,怎么解决的 在实习期间的困难和
-
 作业帮 数据开发 一面 40min
作业帮 数据开发 一面 40min1.自我介绍 2.介绍项目,数据哪来的,数据量级,数仓模型,曝光率怎么算的 3.难点介绍,随spark版本变化会不会有一些函数不适用 4.bitmap的JAVA实现,哈希冲突怎么做的 5.数据倾斜介绍 6.除了数据倾斜,还有哪些优化手段 7.开窗函数 8.udf用过吗 9.JAVA实现过什么项目 10.sql:去掉一个最高分去掉一个最低分求用户平均分 很常规的一次面试,没什么好细说的 #数据人的面
-
 9-4 海亮集团-数据开发
9-4 海亮集团-数据开发数仓有哪几层,每层作用 星型模型和雪花模型 累计快照事实表,拉链表 如何进行维度建模 遇到的数据倾斜问题 大小表join 内部表和外部表区别 拉链表如何设计 spark为什么快 指标体系的建设和管理 用过bi报表之类的吗 炸裂函数,开窗函数 rdd和dataframe的区别
-
为什么H2数据库文件大小的增长超过了数据大小
我有一个h2数据库文件,文件大小已经增长到5GB。我删除了一些数据以缩小文件的大小。但即使从数据库中删除了一半记录,文件大小仍然保持不变。 我已经尝试了以下所有选项来减少数据库大小,但没有一个对我有用。 我的连接字符串如下所示: 注: 我们正在结清我们已经开始的交易 文件中没有5GB的数据 有人能给我建议一些解决方法或修复方法来减少我的数据库大小吗
-
Spring数据排序操作超出最大大小
我是相当新的Spring和MongoDB,并有一个问题,从我的MongoDB拉数据。我试图获得相当大的数据量,并收到以下异常: 执行器错误:操作失败:排序操作使用超过最大33554432字节的RAM。添加索引,或指定一个较小的限制。;嵌套异常是com.mongodb.MongoExc0019: Execator错误:操作失败:排序操作使用超过内存的最大33554432字节。添加索引,或指定较小的限
-
Neo4j查找数据库的最大字节大小
我找到了关于如何计算neo4j数据库大小的以下信息:https://neo4j.com/developer/guide-sizing-and-hardware-calculator/#_disk_storage
-
加载大于 h2o 中内存大小的数据
我正在尝试在h2o中加载大于内存大小的数据。 H2o博客提到: 下面是连接到h2o 3.6.0.8的代码: 给 我试着把一个169 MB的csv加载到h2o中。 这抛出了一个错误, 这表示内存溢出错误。 问:如果H2opromise加载大于其内存容量的数据集(如上面的博客引述所说的交换到磁盘机制),这是加载数据的正确方法吗?
-
 兴金数金,大数据实习面经
兴金数金,大数据实习面经一,上来就问了项目里日志的处理量,50w 100M左右 二,问项目里如何解决Hbase的热点问题,面试官没听明白,后面就直接问热点问题如何解决的 答的就举年份例子,加盐,预分区 三,Kafka里是如何leader和follow是如何实现同步的 具体怎么实现同步我确实不知道,我就答的是offset在follow和leader挂了后如何在实现同步的,面试官说我似乎说了又没说明白,后面查了一下,下
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
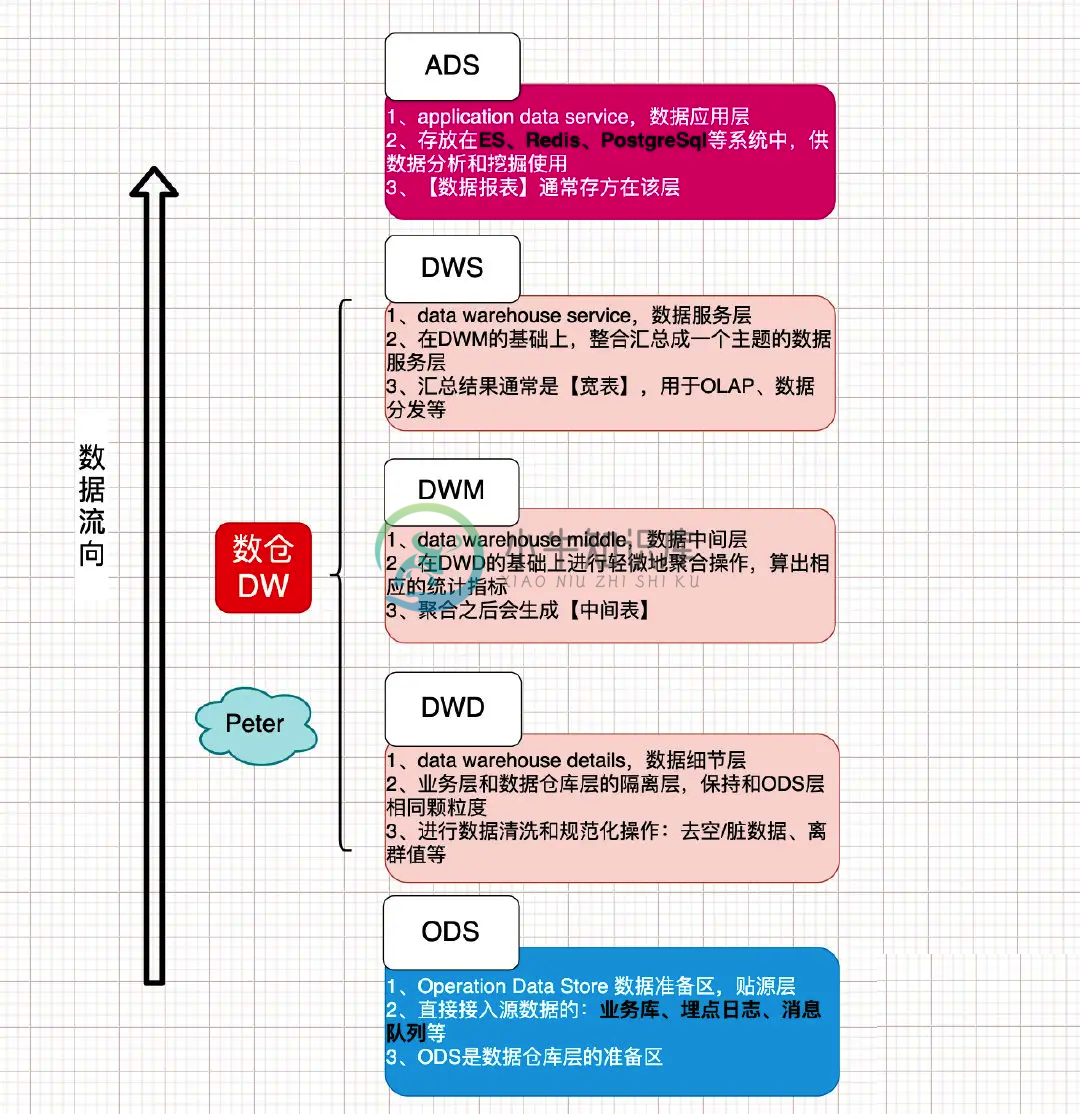 大数据数仓高级面试题 4
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
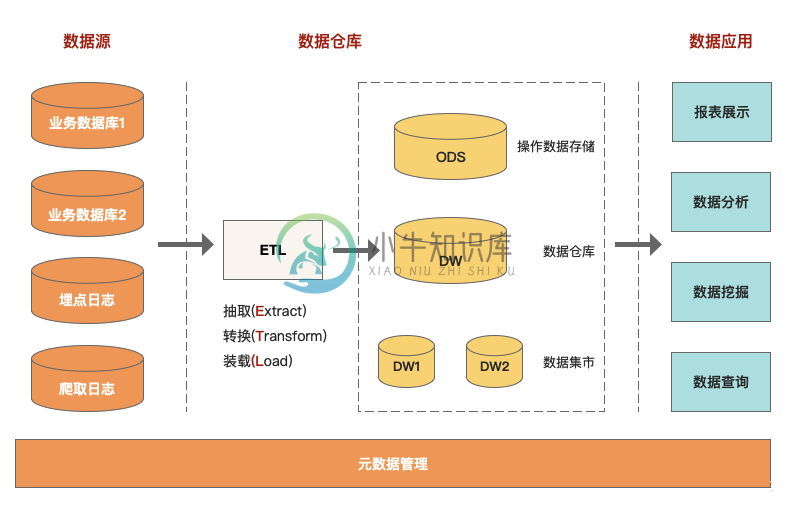 大数据数仓高级面试题 2
大数据数仓高级面试题 2主要内容:1、什么是数据仓库?,2、数据仓库和数据库的区别?,3、如何构建数据仓库?,4、什么是数据中台?,5、数据中台、数据仓库、大数据平台、数据湖的关键区别是什么?,6、大数据有哪些相关的系统?,7、如何建设数据中台?,8、数据仓库最重要的是什么?,9、概念模型、逻辑模型、物理模型分别介绍一下?,10、SCD常用的处理方式有哪些?,11、怎么理解元数据?,12、数仓如何确定主题域?,13、如何控制数据质量?,,,,1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、
-
 博观大数据(数据分析岗位一面面经)
博观大数据(数据分析岗位一面面经)1.自我介绍; 2.有做过落地的实际项目没; 3.介绍一下xgboost与GBDT的关系; 4.介绍一下常用的聚类算法(K-means); 5.了解NLP吗,介绍一下BERT的结构(模型结构、任务); 6.如何缓解数据稀疏、冷启动等问题; 7.反问(主要做什么业务,具体需要使用哪些算法); 8.总结:面试过程简单,没有算法题,一面过了就说线下走流程,已拒绝;
-
 2022/09/21 兴业数金 数据开发(已OC)
2022/09/21 兴业数金 数据开发(已OC)2022/08/01一面 25min 两个面试官 项目介绍一下 大数据比赛集群搭建过程 Hadoop端口号 有哪些配置文件 Hadoop切片 hive和关系型数据库区别 内部表外部表 项目中用的是外部表还是内部表 flink和spark区别 rdd是什么 spark stage怎么划分 spark分区数怎么确定 类加载机制 索引越多越好吗 lock和synchronize ------------