《大数据开发》专题
-
 数据挖掘十大算法
数据挖掘十大算法数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
-
第15章 大数据与MapReduce
大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力。 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则随意浏览后就离开。 对于你来说,可能很想识别那些有购物意愿的用户。 那么问题就来了,数据集可能会非常大,在单机上训练要运行好几天。 接下来:我们讲讲 MapRedece 如何来解决这样的问题 MapRedece Hadoop 概述 Ha
-
 10.14-东方电子-大数据
10.14-东方电子-大数据面试时间:30min 自我介绍 HR常规询问,成绩排名、英语六级、籍贯、家庭、独生子女,高考分数。 研究生日常,工作学校都是怎么安排的?实习日常,加班情况? 实习项目介绍,背景,技术栈? Lamda架构介绍?为什么这么设计?流批一体概念? 技术选型考虑的问题? 选择OLAP数据库的依据?Clickhouse介绍? 研究方向介绍,论文情况,模型和创新点?工程落地? 对公司的意向度? 反问:部门业务?
-
 大疆 数据工程实习
大疆 数据工程实习一面 实习介绍 设计过哪些数据指标,这些指标的意义 项目介绍 具体分层怎么做的 表怎么设计的 对数仓和数据湖的理解 连续登录3天的用户 问的太少了,估计没想招我 #面经##大疆#
-
 美团大数据一面凉
美团大数据一面凉自我介绍 手撕,股票最大利润 sql 成绩排名三 数仓分层 数据倾斜 遇到的问题 为什么要分层 分析了哪些指标 介绍一下spark 介绍一下hadoop 介绍一下hbase 反问 不知道哪的问题,又凉了面了这么多0offer
-
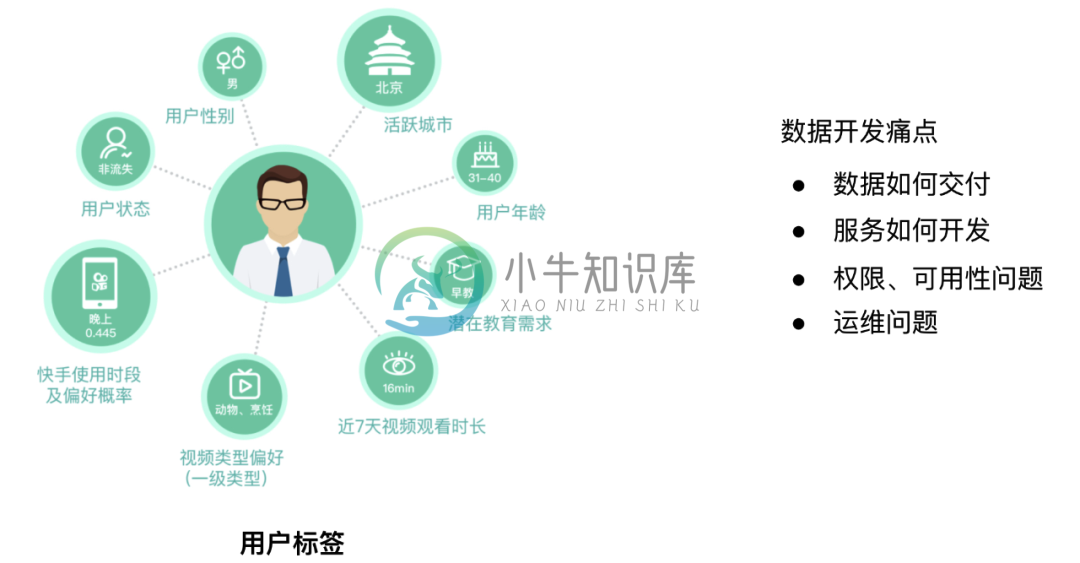 大厂数据中台建设
大厂数据中台建设主要内容:1.现有数据存在的问题,2.系统架构1.现有数据存在的问题 1.1 开发数据服务门槛高 数据开发工程师除了开发完数据表外,通常还需要思考如下问题: 数据如何交付:业务通常期望使用数据接口方式来使用数据,而非数据表,这会更加灵活、解耦、高效。数据开发工程师因此需要建立对应的数据服务 服务如何开发:数据服务有多种形式,通常要求开发工程师有微服务知识、服务发现注册、高并发等 权限、可用性问题:开发完数据服务后,需要考虑权限问题,确保数据资
-
 人工智能与大数据
人工智能与大数据主要内容:1.关系,2.区别1.关系 现在,没有什么流行词比大数据和人工智能更常见了。无数的分析家向我们保证,将从根本上重塑我们的日常生活。事实上,对于围绕人工智能和大数据的所有讨论,很少有人提到这两种新兴技术的融合,尤其是在解释人工智能为什么迫切需要大数据以取得成功的时候。 这是人工智能和大数据操作之间的秘密联系,以及这两种新兴趋势将如何主导21世纪。 没有大数据就不能拥有智能机器 在开始描述人工智能和大数据如何一起工作之
-
 字节 data 大数据四面
字节 data 大数据四面update: 9.30 约 10 月中旬 HR 面了,许愿 OC 🤗 --- 9.29 字节四面,问了 HR 四面技术好像是这个部门的正常情况😅,I'm like, well... - 自我介绍 - 上来先做了一道题:Leetcode 解码方法(动态规划) - 实习具体负责哪些工作,占比是怎样的 - 你们数仓团队几个人,数仓怎么分层、分主题 - 分层的意义 - 你在商品域的工作中是否会涉及边
-
 字节 data 大数据二面
字节 data 大数据二面9.12 一面结束后半小时飞速约了二面,9.14 二面 - 自我介绍 - 为什么读研 - 为什么转专业 - 你对大数据的理解 - 介绍一下实习组内的分工、数仓架构 - 以商品域为例,数据的模型/表有哪些,从哪些角度评价数据模型 - 你们组具体的宏观的业务流程 - 具体是怎么和其他部门协作的,流程是怎么样 - 你是怎么理解数开的工作的,你个人的偏好是哪方向 - 数据库的范式、事务 - 范式建模、维度
-
 字节 data 大数据三面
字节 data 大数据三面中秋假期所以二面三面间隔了挺久的,9.23 三面,面试时间很短,35 分钟左右 - 自我介绍 - 实习介绍 - 看你做了很多任务优化,讲讲优化的思路,从哪些方面去考虑 - 介绍一下 Cube 表去重优化 - 介绍一下***识别项目 - 你们商品维表数据量 - 你们实习部门的数仓分层 - 用户域和流量域的区别 - SQL:今天登录但昨天没登录的用户 - 算法:二叉树层序遍历,自己构造输入输出 - 你
-
 大数据工程师面经
大数据工程师面经👥 面试题目 hadoop的三个核心组件,以及hdfs的读写原理 hive的内部表与外部表有什么区别 hive里面的数据倾斜是什么?怎么去处理?该怎么去预防? 数据仓库的分为几层?每一层是做什么的?是根据什么进行分层的? hive里面的窗口函数有没有用过?rank(),,dense_rank(),row_number()这三个有什么区别? hive里面数据表合并是怎么合并的? hive里面的列
-
 字节大数据商业化
字节大数据商业化1.数据分层概念 2.Hadoop 和spark 优缺点 3.数据倾斜 场景题 大表和小表join 4.宽窄依赖 5.sql题 6.走楼梯算法 7.hive的用户自定义方法区别
-
 联通数科大数据研发(西安)面经
联通数科大数据研发(西安)面经面试10分钟不到,等了快半小时 1 自我介绍 2 项目介绍 3 hdfs读数据流程 4 linux vim命令 5 热门商品topN指标编写 6 为什么选择西安 7 期望薪资
-
Redis:显示数据库大小/密钥大小
问题内容: 我的redis实例似乎正在变得非常大,我想找出我那里的多个数据库中的哪个消耗了多少内存。Redis的命令仅向我显示了每个数据库的总大小和密钥数,这并没有给我带来太多的了解…因此,在监视Redis服务器时为我提供更多信息的任何工具/想法都将受到赞赏。 Redis文档没有显示任何可以返回某些键消耗的内存的命令,因此我想如果有错误代码会为Redis写很多“废纸t”,这可能很难找到… 问题答案
-
 浙江大华大数据提前批面经
浙江大华大数据提前批面经中午两点打过来,我说暂时没空约了晚上八点 面试时间控的很准,也没有反问就结束了 一面15min [项目]- [ ] Linux起一个服务端的过程 -[ ] 使用哪种epoll工作方式 - [ ] 水平触发与边缘触发编写时要注意些什么 - [ ] 多进程如何通信 - [ ] fork如何判断父子进程 - [ ] 虚函数的作用 - [ ] 虚函数的使用场景 - [ ] 了解的C++智能指针 - [ ]