《数据分析面试笔试》专题
-
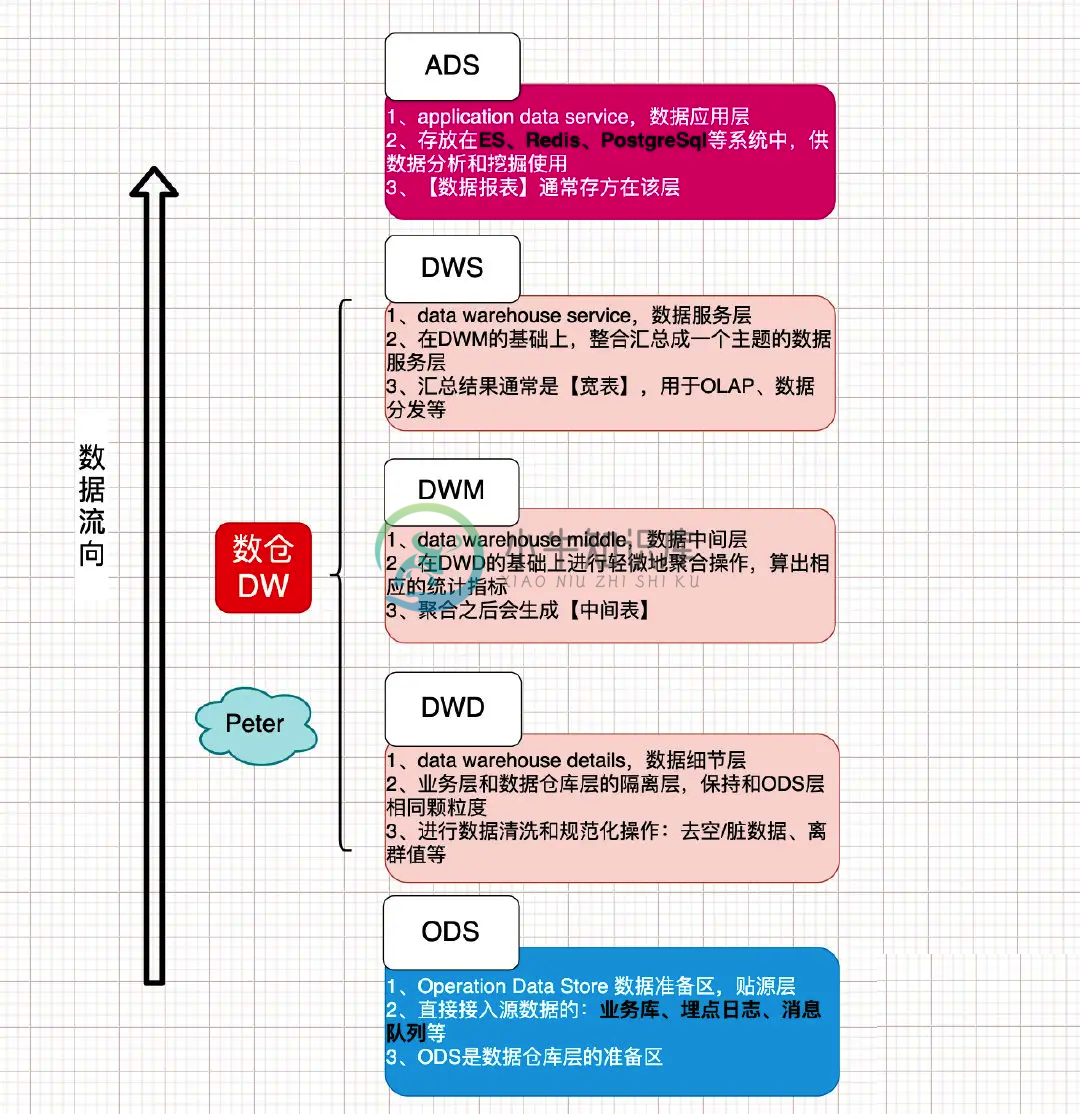 大数据数仓高级面试题【8道】
大数据数仓高级面试题【8道】主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
将分析数据从Spark插入到Postgres
问题内容: 我有Cassandra数据库,可以通过Apache Spark使用SparkSQL从该数据库分析数据。现在我想将那些分析过的数据插入PostgreSQL中。除了使用PostgreSQL驱动程序之外,是否有其他方法可以直接实现此目的(我想通过postREST和Driver实现它,我想知道是否有类似的方法)? 问题答案: 目前,尚无将RDD写入任何DBMS的本地实现。这里是Spark用户列
-
AJAX提交表单数据实例分析
本文向大家介绍AJAX提交表单数据实例分析,包括了AJAX提交表单数据实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了AJAX提交表单数据的方法。分享给大家供大家参考。具体如下: 遍历表单各元素,将参数值组织成JSON格式 这里对CheckBox复选框做了特殊处理,后台接收到的该值为所有复选框值用逗号的拼接 AJAX的调用: 谈到服务器端返回的JSON格式数据,支持如下格式 前端调
-
Android React-Native通信数据模型分析
本文向大家介绍Android React-Native通信数据模型分析,包括了Android React-Native通信数据模型分析的使用技巧和注意事项,需要的朋友参考一下 无论是计算机领域还是日常生活中,我们所言的通信,其核心都是数据信息的交换,而数据模型的优劣对通信效率有着决定性的作用。 在React-Native项目中,Javascript语言与Native两种语言(Java或OC等)间存
-
Mysql数据表分区技术PARTITION浅析
本文向大家介绍Mysql数据表分区技术PARTITION浅析,包括了Mysql数据表分区技术PARTITION浅析的使用技巧和注意事项,需要的朋友参考一下 在这一章节里, 我们来了解下 Mysql 中的分区技术 (RANGE, LIST, HASH) Mysql 的分区技术与水平分表有点类似, 但是它是在逻辑层进行的水平分表, 对于应用而言它还是一张表, 换句话说: 分区不是实际真正的对一张表
-
 详解Python数据分析--Pandas知识点
详解Python数据分析--Pandas知识点本文向大家介绍详解Python数据分析--Pandas知识点,包括了详解Python数据分析--Pandas知识点的使用技巧和注意事项,需要的朋友参考一下 本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘 1. 重复值的处理 利用drop_duplicates()函数删除数据表中重复多余的记录, 比如删除重复多余的ID. 2. 缺失值的处理 缺失值是数据中因缺少信息而造
-
 MobileFirst 7.0运营分析-未加载数据
MobileFirst 7.0运营分析-未加载数据我为MobileFirst 7.0配置了操作分析 根据IBM文档配置JDNI,并在管理操作控制台中创建客户端日志概要文件。但它总是显示0个数据。不加载任何客户端日志/服务器日志。 日志接收器适配器已构建并部署在操作控制台中。客户端有通过WL. Logger.send()将日志推送到服务器的方法。我看到客户端日志控制台和logcat,日志已推送到服务器。在服务器日志中,我还看到logReceiver
-
 电商数据分析实习生(已OC)
电商数据分析实习生(已OC)在牛客的第一条面经。菜鸟一枚,大佬轻喷 😥 单纯记录一下吧,既方便以后自己复盘,同时也希望能为以后投递元气的吴彦祖刘亦菲们做个参考8~ 背景:DS硕士在读,世界500强快消一年运营数据分析工作经历 一.hr约时间 二.业务一面(约36分钟) 1.自我介绍 2.工作经历中数据分析的指标有哪些?有哪些公式? 3.熟悉哪些分析模型?能结合实际的工作展开讲一下吗? 4.进销库存的管理优化是怎么实现的?(
-
 23秋招—猿辅导——数据分析(oc)
23秋招—猿辅导——数据分析(oc)时间:9.4 问题: 一位小哥面试官,基本上来一直问业务题,节奏比较快 快手部门的组织架构和上下游对接情况 两段实习的取数需求、看板工作等的比重 实习工作内容有差异,自己的倾向----分析比重更大 sql和python说思路 表中有user_id 和 friend_id,一共包括100人,去计算最小关系网 预测--1000份面试的样本,抽象出特征,去做预测候选人是否通过的模型,怎么搭建? (这个开
-
产品数据分析的一般过程
如果你不能以一个清晰的过程来展示你所从事的工作,你就不会真正的了解你在做什么。 ——质量管理之⽗ 威廉·爱德华兹·戴明 博士 我相信,不少应用开发者对AARRR模型都有所了解,并且经常会观察产品数据指标的变化和趋势。但是,如何有效的利用这些指标指导产品及运营的改进,多少有些让人感觉无措。很多情况下: 我们得到了非常清晰的产品数据指标; 然而,我们的产品和运营改进依然是盲目的。 换句话说,数据指标并
-
 人保健康 郑州 数据分析岗
人保健康 郑州 数据分析岗3V1 11.16 对人保健康有什么了解 对岗位的认识 你对岗位有什么优势 劣势是什么 你本科是几本院校 你专业对于岗位有什么优势,劣势
-
 字节跳动-数据分析实习生
字节跳动-数据分析实习生二面(约35分钟) 1、自我介绍(在学校的课程上完了吗,可以实习多久等) 2、描述ABtest你所知道的全部内容 3、描述z统计量,t统计量,F统计量 4、z分布,t分布的区别是什么 5、两道SQL题目: (a)找到每个班的学生的数量 ;(b)每个班各科目平均成绩>80分的学生人数和比例 6、怎么分析抖音某个商品购买量下降 7、反问环节
-
 滴普一面 大数据测试 10.13
滴普一面 大数据测试 10.13群面(轮流技术面,还好) (4候选者+1hr+1负责人+2技术面试官) 1.自我介绍 2.问测试项目(好久没看了,记不清。。。) 3.输入网址到出现页面的过程? 4.DNS 6.什么是合理的测试用例? 7.为什么想要做测试?未来的职业规划? #秋招##测试#
-
 大数据(MapReduce)面试题及答案
大数据(MapReduce)面试题及答案介绍下MapReduce ● 1.1 MapReduce定义 ○ MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据分析应用”的核心框架。 ○ MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并行运行在一个 Hadoop 集群上。 MapReduce优缺点 ● 1.2 MapReduce优缺点 ○ 1.2.
-
 大数据(Yarn)面试题及答案
大数据(Yarn)面试题及答案介绍下YARN ● Yarn 是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而 MapReduce 等运算程序则相当于运行于操作系统之上的应用程序。 YARN有几个模块 ● Yarn架构 ○ ResourceManager(RM): ○ NodeManager(NM): ○ ApplicationMaster(AM): ○ Container: YARN工作