《唯品会》专题
-
数据库-唯一约束冲突的处理
我有一个用户创建屏幕,它记录了各种用户详细信息以及名字和手机号码。我有一个对应的用户表,其中名字和手机号码构成一个复合唯一键。此表中还定义了其他完整性约束。 当在创建用户屏幕上输入违反此约束的用户数据时,需要向用户显示“用户友好”错误消息。 当这种违反发生时,我从MySQL数据库中得到的异常是: 有两个选项可以显示有意义的消息(例如:“错误:给定手机号码的用户名已存在,请更改其中一个”)。 选项1
-
我应该用php检查唯一约束吗?
也许这个问题已经被问过了,但我真的不知道如何搜索它: 我有postgres表“customers”,每个客户都有自己的唯一名称。为了实现这一点,我在这个列中添加了一个惟一的约束。 我使用php访问该表。 当用户现在尝试创建一个新客户时,数据库会显示“完整性约束冲突”,php会抛出一个错误。 我想做的是在html输入字段中显示一个错误:“客户名称已被采用”。 我的问题是我应该怎么做。 我应该捕获PD
-
 为每个唯一值创建新工作表
为每个唯一值创建新工作表我有以下代码,可以很好地将相关数据复制到我的工作表中。我为J列中的每个唯一部门手动创建每个工作表,然后运行此宏。我想要一个基于J列中的唯一值动态创建工作表的宏。我在网上找到了很好的资源,但当它到达已经为其创建了工作表的行时,我发现的资源似乎会出错。在手动创建其他工作表之前,我包含了我当前使用的代码以及我的清单表的屏幕截图
-
ORA-00001:违反了唯一约束(MYUSER.ADI\u PK)
我有两张表, 但我做了一个组声明,以确保from\t的名称是唯一的: 我不确定我是否正确理解了这个问题。我尽了我所能,但仍然没有运气。
-
MySQL如何返回唯一/不同的结果?
问题内容: 我正在运行以下MySQL查询,以查找没有手册(且车轮有黑轮等)的汽车 查询的结果看起来正确,但是它两次返回ID为27的汽车。如何更改查询,以使所有结果都是唯一的(没有重复项)? 问题答案: 假定这是唯一的主键,那么其中的一种联接将导致笛卡尔乘积。也就是说:或包含多个匹配项。 子查询通常是消除笛卡尔积的好工具。下面的示例查询显示了两种使用子查询的方法。 第一个子查询可确保我们只查看在20
-
如何使字典列表中的值唯一?
问题内容: 我有一个Python字典列表,如下所示: 我想实现的是保持,和独特的。 例如,如果我们有3项具有相同和,但有3个不同的值 ,,,则操作之后,它应该是和。 我该如何实现? ================================================== =============更新: 好的,感谢Anand的出色回答,它可以完美运行。但是,我还有一个问题。 假设我们有
-
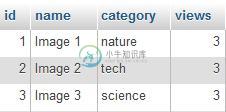 具有Laravel和MySQL的唯一IP计数器
具有Laravel和MySQL的唯一IP计数器我想做一个简单的独特的IP计数器的画廊页面视图。 我的想法是将视图记录与2个表中的图像记录分开。 保存图像:,,,列 为查看的图像保存访问者 此示例屏幕截图显示了3名访问者,每人查看3张图像。我使用免费代理IP。 如果检测到New IP: 将1。 这个视图计数器可以工作,但是所有唯一的ip记录都被分组在2列下。它必须搜索所有记录才能找到匹配的,这可能会随着数千个ip的出现而变慢。 其他想法 > 每
-
在MySQL中仅选择唯一的行/记录
问题内容: 我想看看如何只获得具有唯一城市的唯一行/记录,而不关心是否是首都,例如: 只会返回一条记录。 我累了像这样的东西,但是没用 谢谢… 问题答案: 您可以使用以下仅用于mysql的技巧: 这将返回 遇到的第一行 的每个独特的价值和。 其他数据库将抱怨您的分组依据中未列出未聚合的列或此类消息。 已编辑 以前我声称不使用分组列上的函数将返回所有大小写的变化,但这是不正确的- 感谢SalmanA
-
根据SQL中的值添加唯一约束
问题内容: 我有一种情况,我只想在其他字段中有特定值的情况下才添加唯一约束(例如表为ID CategoryName名称值Value CategoryID) 约束将在ID,CategoryName和Name上,只有CategoryID为0 是否有可能? 问题答案:
-
在唯一约束之前清理SQL数据
问题内容: 我想在对两列施加唯一约束之前清理表中的某些数据。 输出应为 我正在寻找重复 的第一 行 之后的 所有行 前任: 第1,2行的(b,c)为(2,3)。第1行是正确的,因为它是第一个,第2行不是。 行4,6,7的(b,c)为(4,4),行4可以,因为它是第一个,而6,7则不是。 然后,我将: ..并添加唯一约束。 我当时正在考虑与自身进行测试的交集,但不确定从哪里开始。 问题答案: 我进行
-
一键选择Oracle SQL非唯一表别名
问题内容: 有人知道为什么这对两个表别名“ x”都有效吗? 我知道ID为5的JOIN没有任何意义… 感谢您的教训! 问题答案: 下面的前两个查询是等效的。在连接的子句中,表别名仅指使用该别名的最后一个表,因此仅表受到限制。 在和表达式中,别名引用两个表-因此,列名是唯一的,则可以成功引用它们,但是,在列名相同的情况下,oracle会引发异常(如果删除了注释,则在查询3中会发生这种情况)。 我找不到
-
带有变量[duplicate]的Javascript对象唯一ID
我正在尝试使用唯一ID将JSON对象存储在数组中,以便我可以在以后的代码中提取该特定对象,但是我的预期输出没有发生:
-
NumPy数组中每行的唯一元素数
例如,对于 我想得到 有没有办法不用for循环或使用? 编辑:实际数据由1000行组成,每行100个元素,每个元素的范围从1到365。最终目标是确定有重复的行的百分比。这是一个作业问题,我已经解决了(用for循环),但我只是想知道是否有更好的方法来做它与Numpy。
-
指向唯一约束的Laravel关系外键
用户表: 图书目录: 用户模型中的关系: 默认情况下,外键指向主键id。如何使其指向唯一的? 如果只有,是主键,我们可以用第三个参数传递它,并覆盖属性:
-
PostgreSQL与多列唯一约束名称冲突
当尝试使用PostgreSQL执行时,我遇到了一个我不理解的行为。文档似乎指示语句的冲突目标可以是索引表达式或约束名称。但是,当试图引用约束名称时,我得到了一个“列...不存在”错误。 我的第一次尝试是创建一个索引,它可以很好地处理约束推理: 在描述上表时,我在“索引”下看到了以下内容: 我的第二次尝试是将唯一约束显式地放在创建表中: 在描述上表时,“索引:”的输出略有不同(“唯一约束”与前一示例