《万得信息》专题
-
 中信银行信息科技岗线上群面初体验
中信银行信息科技岗线上群面初体验面试形式:群面辩论 之前没面过群面,本来也是抱着体验的心态去的,我全程只说了4-5句话 😅,应该已经 G 了 流程: 1. 读一段关于某个议题的材料,15 个人分为两个 A B 组 2. 组内讨论。组内讨论总结支持我方观点的结论,三分钟还是五分钟 3. 组间辩论。争论 AB 面,15分钟还是20分钟 4. 综合结论,给出比较客观全面的方案和结论,一个人汇报,2分钟 汇报完就可以关闭摄像头离场了,
-
 中国银行信息科技运营中心 中行信科
中国银行信息科技运营中心 中行信科面完了,写个面经吧。(base 上海 信息科技岗) 1、自我介绍 2、本科绩点 3、实习经历 4、是否挂过科 5、家在哪 6、是否有其他offer 7、数据清洗流程 8、特征选择、降维方法 9、分类的作用(具体应用场景) 10、数据有缺失值怎么处理 11、offer城市选择 大概流程12分钟吧。中间的面试官追问了好多细节,还说了一句“这就没了?”。我估计是g了,明天面试的xdm加油
-
假如你是微信的产品经理,你觉得微信最应该优化的功能是什么,原因是什么?为什么微信没有做出这个优化?
本文向大家介绍假如你是微信的产品经理,你觉得微信最应该优化的功能是什么,原因是什么?为什么微信没有做出这个优化?相关面试题,主要包含被问及假如你是微信的产品经理,你觉得微信最应该优化的功能是什么,原因是什么?为什么微信没有做出这个优化?时的应答技巧和注意事项,需要的朋友参考一下 附近的人添加视频动态。 在附近的人的基础上增进一个方便他人了解和切入话题的维度,同时起到普及和传播动态视频的作用。打开方
-
Java读取200万行文本文件的最快方法
问题内容: 目前,我正在使用扫描仪/文件阅读器,同时使用hasnextline。我认为这种方法效率不高。还有其他方法可以读取与此功能类似的文件吗? 问题答案: 您会发现这是所需的速度:您可以每秒读取数百万行。字符串拆分和处理很可能导致遇到的任何性能问题。
-
 阿里云盘万能邀请码注册获取教程
阿里云盘万能邀请码注册获取教程本文向大家介绍阿里云盘万能邀请码注册获取教程,包括了阿里云盘万能邀请码注册获取教程的使用技巧和注意事项,需要的朋友参考一下 阿里云网盘注册邀请码怎么注册登陆?为了让更多的小伙伴也体验体验,之前也特分享了一批阿里云盘邀请码送给大家,下面为大家分享一下获取阿里云盘邀请码注册登录网盘的方法。 软件介绍 根据阿里云盘官网介绍,其组建了一支由智能算法、智能存储、新型网络、AloT、 网络安全等领域科学家、工
-
MySQL快速从60万行中选择10条随机行
问题内容: 如何最好地编写一个查询,从总共60万行中随机选择10行? 问题答案: 一个出色的职位,可以处理多种情况,从简单到有缺口,再到有缺口的不均匀。 http://jan.kneschke.de/projects/mysql/order-by- rand/ 对于大多数一般情况,这是您的操作方法: 这假定id的分布是相等的,并且id列表中可能存在间隙。请参阅文章以获取更多高级示例
-
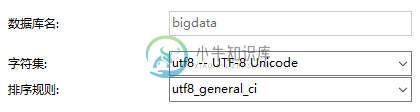 Mysql快速插入千万条数据的实战教程
Mysql快速插入千万条数据的实战教程本文向大家介绍Mysql快速插入千万条数据的实战教程,包括了Mysql快速插入千万条数据的实战教程的使用技巧和注意事项,需要的朋友参考一下 一.创建数据库 二.创建表 1.创建 dept表 2.创建emp表 三.设置参数 SHOW VARIABLES LIKE 'log_bin_trust_function_creators'; 默认关闭. 需要设置为1。因为表中设置 mediumint 字段
-
封装好的一个万能检测表单的方法
本文向大家介绍封装好的一个万能检测表单的方法,包括了封装好的一个万能检测表单的方法的使用技巧和注意事项,需要的朋友参考一下 检测表单中的不能为空(.notnull)的验证 作用:一对form标签下有多个(包括一个)表单需要提交时,使用js准确的判断当前按钮对那些元素做判断 用法:在form标签下 找到当前 表单的容器 给予class="form",当前表单的提交按钮给予 class="chec
-
MySQL从60万行中快速选择10条随机行
问题内容: 如何最好地编写一个查询,从总共60万行中随机选择10行? 问题答案: 一个出色的职位,处理从简单到有缺口,再到有缺口不均匀的几种情况。 http://jan.kneschke.de/projects/mysql/order-by- rand/ 对于大多数一般情况,这是您的操作方法: 这假定id的分布是相等的,并且id列表中可能存在间隙。请参阅文章以获取更多高级示例
-
在Python中合并具有数百万行的两个表
问题内容: 我正在使用Python进行一些数据分析。我有两个表,第一个(叫它“ A”)有1000万行和10列,第二个(“ B”)有7300万行和2列。他们有1个具有共同ID的列,我想根据该列将两个表相交。特别是我想要表的内部联接。 我无法将表B作为pandas数据框加载到内存中,以在pandas上使用常规合并功能。我尝试通过读取表B上的文件的块,将每个块与A相交,并将这些交集连接起来(内部联接的输
-
在java中使用lmax Disruptor(3.0)处理数百万文档
我有以下用例: 当我的服务启动时,它可能需要在尽可能短的时间内处理数百万个文档。将有三个数据来源。 我已设置以下内容: 我的每个源调用consume都使用Guice来创建一个单例破坏者。 我的eventHandler例程是 我在日志中看到,制作人(
-
向hbase插入数百万条记录时会出现SocketTimeoutException
我构建了一个由九个节点组成的hbase集群。每个节点都有64GB的内存容量。现在,我想向hbase插入数百万条记录。为了提高写入性能,我在每个节点中创建了20个线程,并且在每个节点中将writebuffer设置为64MB,并且自动刷新为false。 准备好数据并设置好配置后,我启动hbase集群。但当记录达到一定程度时,问题就出现了。 Java语言网SocketTimeoutException:等
-
更新嵌套字段以获取数百万个文档
问题内容: 我对脚本使用批量更新以更新嵌套字段,但这非常慢: 您知道另一种可能更快的方法吗? 为了不对每次更新重复执行脚本,似乎可以存储该脚本,但是我找不到保持“动态”参数的方法。 问题答案: 与性能优化问题一样,由于有许多可能导致性能不佳的原因,因此没有唯一的答案。 在您的情况下,您正在批量请求。当执行,该文件实际上是被重新索引: …要更新文档就是要对其进行检索,更改,然后为整个文档重新编制索引
-
Neo4j 2.1.0-M01严重失败,树图为830万片叶子
(已经在Github上打开了一个案例#2250,但这里可能有人有解决方案?)他讲故事。我们有一个数据集,它只是一个具有 级别为0的单个根节点(有时它的ID(root)=0,因为我们从空数据库开始) 我们正在使用LOAD CSV加载数据,其中每一行创建一个节点和与前一级节点的关系。Neo4j是一个2.1.0-M01 Enterprise for Startups,集群有3个节点,每个实例有8Gb内存
-
使用PySpark生成6000万JSON文件时的OutOfMemoryError[重复]
通过JDBC连接,我能够成功地从Oracle db使用下面的PySpark代码生成6000万记录CSV文件。 根据管理员的要求,我更新了我的评论:这是一些不同的问题,其他outoutmemory问题也存在,但在不同的场景中会得到。错误可能是一样的,但问题是不同的。在我的情况下,我得到了大量的数据。