《阅文集团》专题
-
Firestore-如何在将文档添加到集合后获取文档id
是否有方法获取将文档添加到集合后生成的文档id? 如果我将文档添加到代表社交媒体软件中“帖子”的集合中,我想获取该文档ID并将其用作不同集合中另一个文档中的字段。 如果我无法获取添加文档后生成的文档Id,我是否应该计算一个随机字符串,并在创建文档时提供Id?这样我就可以使用与其他文档中的字段相同的字符串了? 快速结构示例:
-
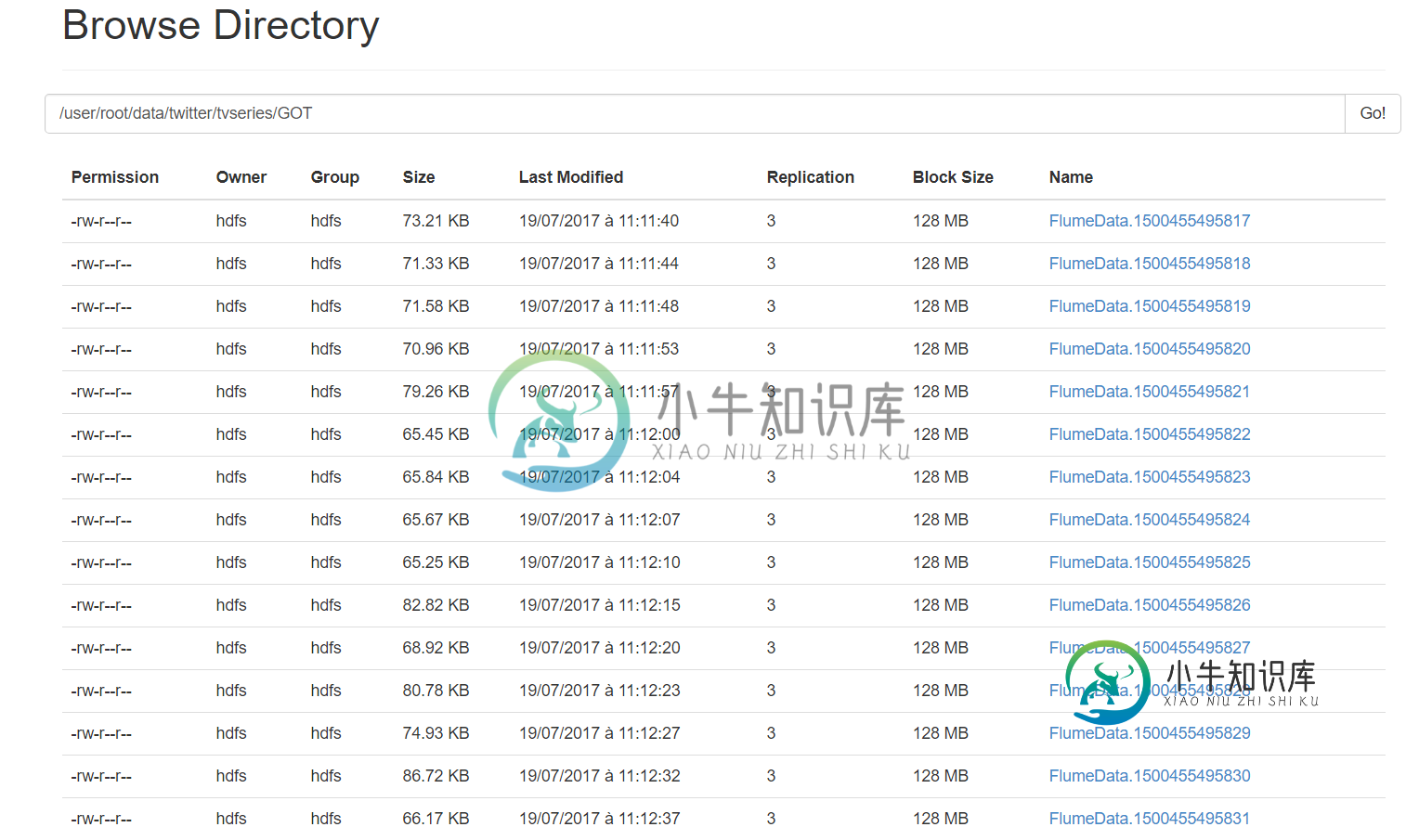 如何将所有收集的推文提取到一个文件中
如何将所有收集的推文提取到一个文件中我用Flume收集推文,并存储在HDFS上。收集部分工作正常,我可以在我的文件系统中找到我所有的推文。 正如我们所看到的,推文存储在128MB的块中,但只使用几个Ko,这是HDFS的正常行为,如果我错了,请纠正我。 然而,我如何在一个文件中获取所有不同的推文? 这是我使用以下命令运行的conf文件: flume ng agent-n TwitterAgent-f./my flume files/t
-
邮递员请求正文中的文件未保存在集合中
我有一个 POST 请求,用于验证请求正文中的文本/csv 文件。请求在邮递员中成功运行:返回 HTTP 代码 200。Postman 控制台中的请求正文填充了文件路径和名称,即 src:“/Users/username/Downloads/demo_file.csv”,但是当导出集合时,请求中的文件值为空。见下文。 问题。为什么它是空的,这是一个错误/已知问题吗? 作为一个快速测试,我将文件添加
-
屏幕阅读器不是读取aria-label属性中的文本,而是读取元素中的文本
我有以下元素。计数在跨度元素中,文本在 DIV 标记中。当我将鼠标悬停在计数上时,它只读取数字,当我将鼠标悬停在 DIV 标记的文本上时,它只读取文本。但我希望屏幕阅读器将完整文本读取为“1 文档”。为此,我保留了带有计数的“aria标签”属性,并为具有类“列表项”的父DIV保留了文本。但它仍然只阅读文本“文档”,而不是整个计数。
-
采集帮助 - 了解采集 - 采集流程
采集流程: 采集一般可以分为3个过程:1.设置采集规则;2.采集数据内容;3.导出内容,这3个内容是可以独立分开来的。 设置采集规则:这个就是在操作中的添加采集节点,并对这个节点规则进行设置,比如:设置采集内容列表的地址、指定采集标题或者内容的位置(规则)、设置采集内容过滤规则。这个规则是采集最根本最基础的东西,采集规则可以导入导出,方便对这个采集规则进行分享。 采集数据内容:根据不同情况对数据采
-
采集帮助 - 了解采集 - 关于采集
关于采集: 什么是采集呢?我们可以这样理解,我们打开一个网站,看到有一篇文章很不错,于是将文章的标题和内容复制,然后将这篇文章转到我们的网站上,这个过程就可以称作采集,将别人网站上对自己有用的信息转到自己网站上。 采集器也是这样,不过整个过程是由电脑来完成的,我们复制人家的标题和内容,是在知道什么地方是内容,什么地方是标题前提下进行操作的,但电脑是不知道的,所以我们要告诉电脑怎么识别怎么采,这就是
-
 某集团任意文件下载到虚拟主机getshell的方法
某集团任意文件下载到虚拟主机getshell的方法本文向大家介绍某集团任意文件下载到虚拟主机getshell的方法,包括了某集团任意文件下载到虚拟主机getshell的方法的使用技巧和注意事项,需要的朋友参考一下 0x01 前言 从某群的故事改编而来,都是些老套路各位看官看得高兴就好;第一次在i春秋发帖有点紧张,如果有什么不周到的地方请去打死阿甫哥哥。你没听错,阿甫哥哥推荐。 0x02 什么是任意文件下载 说到文件下载各位童鞋都不陌生(老
-
MySQL使用Java从文件插入大数据集
问题内容: 我需要将CSV文件中的约180万行插入MySQL数据库。(只有一张桌子) 当前使用Java解析文件并插入每一行。 可以想象,这需要花费几个小时才能运行。(粗略地10) 我之所以没有将其从文件直接传送到db中,是因为在将数据添加到数据库之前必须对其进行操作。 此过程需要由那里的IT经理来运行。因此,我将其设置为一个不错的批处理文件,以便他们在将新的csv文件放入正确的位置后运行。因此,我
-
Firestore:如何在集合中获取随机文档
问题内容: 对于我的应用程序而言,至关重要的是能够从Firebase的集合中随机选择多个文档。 由于Firebase(我知道)没有内置本机函数来实现执行此操作的查询,因此我的第一个想法是使用查询游标选择随机的起始索引和终止索引,前提是我拥有其中的文档数集合。 这种方法行之有效,但只能以有限的方式进行,因为每次每次文档都会与其相邻文档一起依次送达。但是,如果我能够通过其父集合中的索引选择一个文档
-
无法加载文件或程序集系统。Web.Mvc
我在我的项目中使用的是umbraco 4.11.3。我的项目在Windows 7上运行良好,并在visual studio 2012上运行。但它在Win 8中从visual studio 2012运行时并不工作! 错误是: 无法加载文件或程序集“System.Web”。Mvc,Version=2.0.0.0,Culture=neutral,PublicKeyToken=31bf3856ad364e
-
使用Java将结果集转换为CSV文件
问题内容: 嗨,我正在尝试将oracle jdbc结果集转换为csv文件。下面是使用的代码。当字段中具有如下所示的值时,就会发生问题。它会使输出csv变形,所有这些都放在单独的行而不是一个字段中。 栏位中的值在csv中列为 [<333message:脚本中的运行时错误’ProcessItem:’类型:’ITEM’“ 1:0)。内部脚本错误:java.lang.NullPointerExceptio
-
从swagger规范文件更新邮递员集合
-
SQL查找带有所有标签集的文章
问题内容: 查找带有一组标签中任何一个的文章是一个相对简单的联接,并且已经讨论过:最佳数据库(MySQL)结构:包含优先标签的文章 但是,如果我正在搜索,并且想要查找带有所有标签集的文章该怎么办? 为具体起见,假定下表: 我想出了这个方法,我认为这可能会起作用,但是它非常庞大,丑陋且不清楚,因此我认为必须有更好的方法: (本质上,请计算相关标签的数量是否为期望值。) 问题答案: select ar
-
Firestore创建集合而不添加任何文档
我想创建一个集合而不在其中创建任何文档。但不是先创建文档,然后删除文档。我尝试了一些方法,但当我删除文档时,我的集合也被删除了。 Firestore图像
-
如何使用Spring集成处理大型文件
我正在处理非常大的文件,并使用Spring集成来处理它们。我想知道使用Spring集成和提供的DSL处理这些问题的最佳和最有效的方法是什么。我有一个测试CSV文件,它有大约30K条记录,我正在使用filespliter组件将每一行读入内存,然后根据分隔符再次拆分,以获得我需要的列。 下面的代码段。