《阅文集团》专题
-
在流星1.7+中可以订阅文本搜索光标吗
解决办法是什么?
-
使用urllib2和python正确阅读超文本标记语言
我打开这个链接"http://www.amazon.com/s?rh=n: 1"与urllib2和我试图获取下一页链接(href="/s/ref=lp_1_pg_2?rh=n: 283155, n:!1000, n: 1
-
出现错误请参阅日志文件/users/GeorgeHornton/workspace/.metadata/.log
现在,我希望这不是一个重复的问题,因为它的标题类似于这个链接中的问题:一个错误已经显现。请参见日志文件/user/workspace/.metadata/.log[duplicate]。但这不应该是因为我已经下载了Eclipse IDE。为了方便起见,我的Eclipse版本是Neon3,我在我的苹果MacBook Air上使用它。
-
第三章 – MQTT控制报文 - 3.11 UNSUBACK – 取消订阅确认
3.11 UNSUBACK – 取消订阅确认 服务端发送UNSUBACK报文给客户端用于确认收到UNSUBSCRIBE报文。 3.11.1 固定报头 图例 3.31 – UNSUBACK报文固定报头 Bit 7 6 5 4 3 2 1 0 byte 1 MQTT控制报文类型 (11) 保留位 1 0 1 1 0 0 0 0 byte 2 剩余长度 (2) 0 0 0 0 0 0 1 0 Bit 7
-
动作电缆在本地订阅,但不在heroku上订阅
问题内容: 我一直在尝试可以在网上找到的所有内容,但没有任何效果。希望大家能看到新的问题。这是我第一次使用ActionCable,在本地一切正常,但是当推送到heroku时。我的日志没有像我的开发服务器那样显示任何可操作的订阅: 在发送消息时,我确实看到了,但没有将它们追加,这是在猜测是否意味着未访问/调用该方法? 我确实在heroku的日志中注意到它说,开发人员正在localhost:3000监
-
如何使用WooCommerce订阅获取特定用户的订阅?
语境: 给定一个WooCommerce和WooCommerce订阅的WordPress网站,我试图获取特定用户订阅的列表。在最近的更新之前,这一行代码已经为我解决了这个问题。以下是我一直在使用的代码: 其中$user\u id是WordPress中的有效用户id。 问题: 自上次更新以来,我们经常看到以下错误: 致命错误:在/home/warfarep/public_html/wp content
-
嵌套的可观察订阅问题,无法取消订阅
在ngOnDestory中,我取消了两个订阅,但仍然得到前面的错误。 现在我几乎可以肯定问题出在这行:即使我在注销之前取消了proposalSubscription和chatSubscription的订阅,但仍然会出现错误。有没有解决这个问题的方法?而且,我对RXJ和操作符没有太多的经验。有没有操作符可以用来避免这种嵌套订阅? 提前道谢。
-
 Antlr4预处理器文法与C文法的集成
Antlr4预处理器文法与C文法的集成我是ANTLR4的新人。我正在使用Antlr4和Antlr4适配器来解析C文件并生成PSI树。 我知道C预处理器应该处理#include和#define部分,并将结果传递给C lexer和C parser。但是我需要为C.G4解析#include和#define,这样我的插件就可以在没有预处理器的情况下处理C文件。 我查看了这个链接并尝试了解决方案,但当它遇到预处理器语句以外的东西时,它就无法解决
-
播放核心应用内审阅API,但未显示审阅activity
我正在尝试利用昨天刚刚发布的Google的Review API(Play Core Library1.8.0)。参见https://developer.android.com/guide/playcore/in-app-review 我仔细地遵循了疑难解答部分,我确保应用程序是从内部测试轨道下载的,我的帐户没有对应用程序的审查,应用程序在该用户的库中等等。我甚至尝试过使用一个全新的帐户,但每次显示
-
将苹果TouchId或三星Finger打印阅读器与我的应用程序集成
我目前正在为(Android,ios)开发一个移动应用程序,它有以下要求。请告诉我是否可以在最新的智能手机、平板电脑上使用内置指纹阅读器来满足我的要求。 我有一个运行在云上的人力资源管理系统,我有员工的详细信息,现在我正在开发一个员工考勤的移动应用程序,基本上应用程序将在以下步骤中工作。 当员工打开应用程序时,它将显示一个指纹登录。 员工将在设备上点击手指,假设它有内置的指纹读取器支持。 移动应用
-
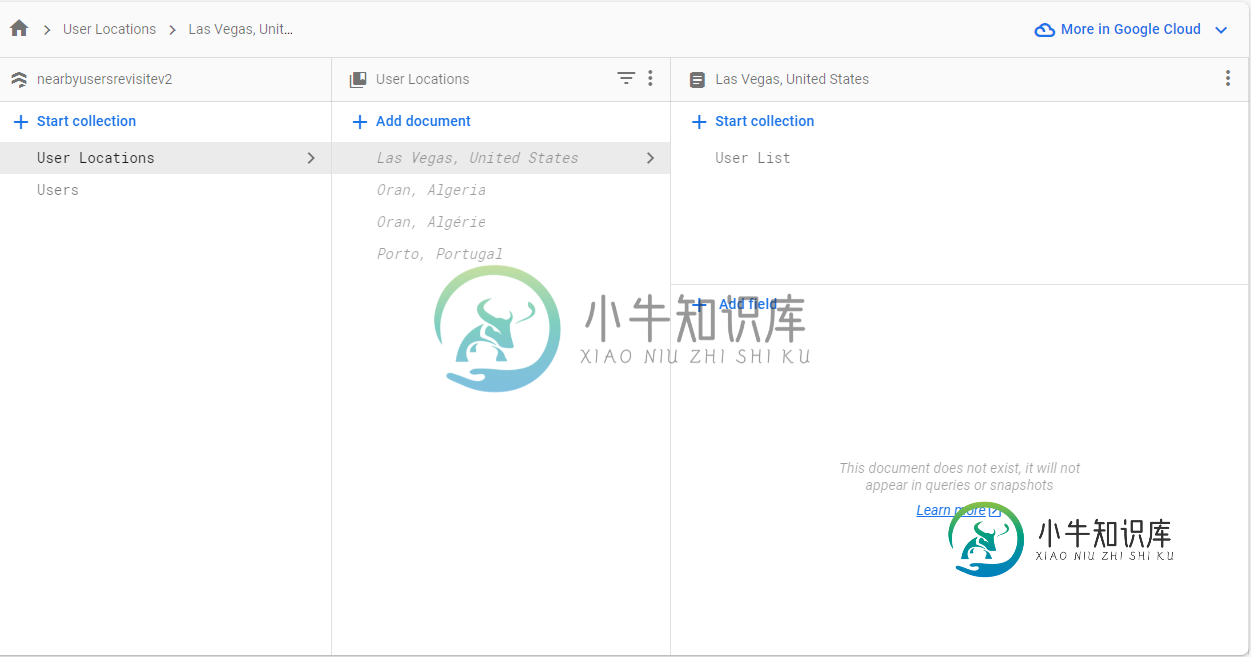 Firestore从根集合中获取所有文档(包含子集合)
Firestore从根集合中获取所有文档(包含子集合)我正在使用Java开发一个Android应用程序,我使用firestore数据库,我有一个名为用户位置的集合,其结构类似于照片: 分贝 我的问题是,当一个用户改变他的位置或一个新用户进入一个已经存在的位置(其他用户有相同的位置)时,它会创建一个新文档(如在“oran, algerie”中)。当我添加新用户并更新文档时,我想使用,但问题是我无法以正常方式检索根集合的所有文档: 它返回null。我尝试
-
WebFlux:从流内对象添加订阅服务器上下文值
我有一个Webflux应用程序,我正在使用订阅服务器上下文填充MDC值,以便它们向下游传播。我已经实现了这个项目中的类来处理订阅者之间的MDC传输,设置webfilter来向传入的请求添加请求ID,并且可以在日志中看到请求ID作为MDC的一部分。 日志输出: ...但是什么都没起作用。如何从属于进程流的对象向订阅服务器上下文添加数据?
-
我如何避免阅读我对Firestore不感兴趣的文档?
我收集了2k份文件。我已经实现了分页,所以一次可以得到10个文档。文档如下所示: 要获取前10个元素,我使用以下查询: 要获得接下来的10个文档,我使用: 第一次打开应用程序时,我会滚动3页,这样总共会向缓存中添加30个文档。第二次打开应用时,我不想再次下载文档。由于我有字段,我可以查询: 这将返回所有新的/修改的文档,这很糟糕,因为如果添加了200个文档,我会为它们付费。换句话说,我花了200次
-
如何从Spring集成java dsl集成文件轮询集成流触发Spring批处理
如何使用java dsl Integrationflows从spring集成触发spring批处理作业。 我有下面的代码,它轮询目录中的文件,当新文件添加到目录中时,会生成一条消息,我想在该实例中触发一个Spring批处理作业。请建议。
-
Stormpath Spring Boot集成-上下文重复
我试图将Stormpath登录工作流添加到我的Spring Boot应用程序中,该应用程序在/api上下文中运行,该上下文在我的application.properties中定义为server.context-path=/api。 当我访问一个受限路径时,我会得到Stormpath登录页面,其中包含一个“Next”请求参数http://localhost:8080/api/login?next=%