《oc》专题
-
浏览器演示中的Google Cloud Vision OCR与通过python实现的OCR之间的差异
我对谷歌云视觉应用编程接口相当陌生,所以如果有一个明显的答案,我很抱歉。我注意到,对于一些图像,我在谷歌云视觉应用编程接口拖放(https://cloud.google.com/vision/docs/drag-and-drop)和python中的本地图像检测之间得到不同的OCR结果。 我的代码如下 突出显示这一点的示例图像附在示例图像中 上面的python代码不会返回任何内容,但在浏览器中使用拖
-
Openshift oc new-app命令getsockopt:连接拒绝错误
我使用Docker注册表和Openshift原始映像运行RHEL虚拟机: 我可以成功地从虚拟机本身通过docker拉localhost:5000/cowsay-dockerfile: 2.0 但是,在“源”容器内,与 new-app 等效的命令将失败: 我尝试了新应用程序的各种参数,包括2.0标记和不带2.0标签,以及如下(使用不安全的注册表启动): 我觉得我必须接近将图像放入Openshift
-
 ocsps不显示但我有在DSS
ocsps不显示但我有在DSS我刚刚签署文件。和添加LTV太(与文档安全故事和TSA);但土坯读者告诉我,LTV是不启用。 我发现了问题。Adobe reader告诉我文档中没有嵌入OCSP。 添加时间戳后,我只需创建DSS字典并添加证书和ocsp响应。 这还不足以增加OCSP吗? 我像Pades BES一样签署文件。它需要VRI吗?我知道id不需要。 这是样品 PDF文件
-
如何使用iText为PAdES签名时间戳嵌入CRL/OCSP撤销信息?
这个问题与另一个问题相连。 由于我想完全验证添加到PAdES签名(过期和撤销)中的时间戳,我还需要将crl文件或创建时间戳时捕获的TSA证书的ocsp响应添加到签名中。 据我所知,iText 5.4.1似乎没有提供此功能。特别是通过 com.itextpdf.text.pdf.security.TSAClientBouncyCastle和 com.itextpdf.text.pdf.securit
-
PDO OCI截断大型多字节CLOB
当PDO OCI通过PDO::Fetch()返回我的行时,我的CLOB列已经是PHP流了。在长CLOB中包含多字节UTF-8字符的情况下,当我读取这个流时,它会被截断。 实例 我的头饰是一串8193英镑的符号(“”)...16,386字节 返回的行数组将列显示为“resource type='stream'” 我执行stream_get_contents()从流中获取字符串 我的字符串为8,192
-
使用OCR以键值格式从护照图像中提取数据
我的目标是使用基于OCR服务器的解决方案,以键值格式从护照图像中提取数据,以便数据保留在本地。我尝试了Azure表单识别器容器(认知服务表单识别器API V1预览版)。但结果并不令人满意,因为根据训练数据创建的模型无法提取任何键值对。我尝试了各种训练样本数据,也参考了https://docs.microsoft.com/en-us/azure/cognitive-services/form-rec
-
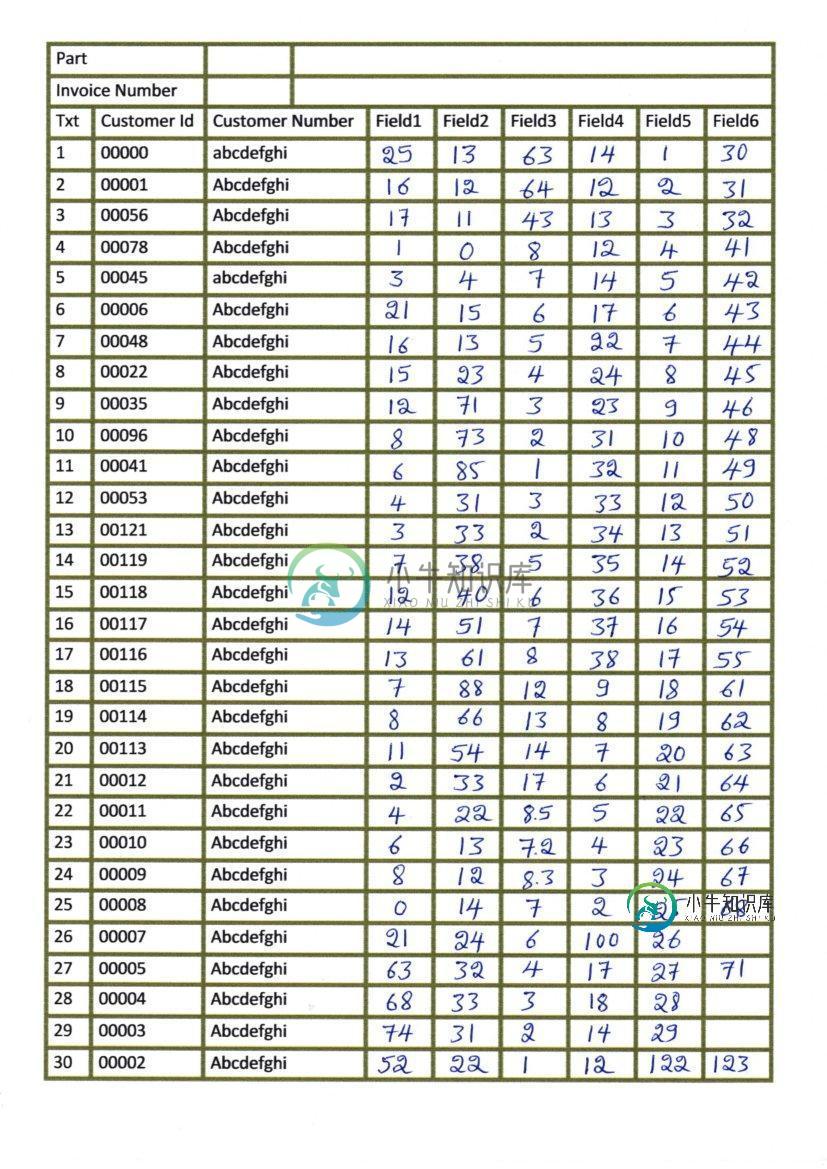 使用OCR将表格图像中的单个字段提取到excel
使用OCR将表格图像中的单个字段提取到excel我扫描了一些图像,这些图像有如下所示的表格: 我试图分别提取每个框并执行OCR,但当我尝试检测水平线和垂直线,然后检测框时,它会返回以下图像: 当我尝试执行其他转换来检测文本(侵蚀和扩张)时,一些残留的线条仍然伴随着文本出现,如下所示: 我不能检测文本只执行OCR和正确的边界框不会生成如下所示: 我不能使用真正的线条清晰地分开盒子,我已经在一个用油漆编辑的图像上尝试过了(如下所示),以添加数字,并
-
我想从OCR数据中提取表格信息
我想从OCR数据中提取表格信息,我有原始文本和它的文本。我尝试了pytesseract,但找不到实际的实现。 以下是一张图片:https://drive.google.com/open?id=1CGJwbmf5snoXvwlQAsRAxIRRixbT_Q8l 我试过这个:https://github.com/WZBSocialScienceCenter/pdftabextract 这种方法对我根本
-
如何使用OCR从指定位置提取文本信息?
用户上传包含班级、教授、时间表等信息的表格数据。 我想很容易地提取这些信息。 我可以使用OCR库,但它只会输出随机混合的文本。 我不知道什么东西属于什么。 有没有一种方法可以训练OCR只查看图像(表单)的特定部分,然后标记数据,这样当它提取数据时,所有数据都会被标记。等 假设我有一个有很多数据的表单,我希望它只看地址部分并标记它。 或者是类似电子表格的数据,我想让它按列标记。 简单地将所有文本提取
-
 如何在java中使用OCR识别来自不同表单字段的表单数据?
如何在java中使用OCR识别来自不同表单字段的表单数据?我有一个表单的图像,其中包含不同的字段,如名称,数字,地址等。我想从这些字段中识别数据并将其保存到数据库。现在,我的OCR工作正常,但我不知道如何从图像中提取特定的字段数据(名称,地址)用于OCR。简单地说,我想知道如何识别输出文件中的字符是来自名称字段或地址字段或任何其他字段。
-
goFabric8>无法解压缩/users/apple/.fabric8/bin/oc.zip zip:不是有效的zip
我正在尝试为微服务设置环境。我在用fabric8来做到这一点。 我使用的是命令。在执行时,我得到以下错误... 你知道吗?
-
峰值查找算法MIT OCW 6.006-它一直存在吗?
这周我开始了MIT OCW6.006的讲座,在第一节课上教授介绍了找峰算法。 1 2 3 4 5 6 7 8 9 a-i是数字 位置2是峰当且仅当b≥a且b≥c。如果i≥h,位置9是峰值 他提出这个算法是为了提高它的复杂度: [9,8,7,6,5,2,3,1] 该算法的工作原理如下: 步骤1:A[n/2] 6<7?-->是的,看左半部分[9,8,7,6] 步骤2:A[n/2] 8<9?-->是的,
-
OCLinEcore安装过程中的问题
我是一名学生,我试图在eclipse中使用EMF创建一个元模型。现在,我试图在我的元模型中添加一些OCL约束,所以,我尝试使用OCLinEcore。不幸的是,当我点击我的(*。ecore/open with/ocline core editor)它显示如下错误: 加载程序约束冲突:在解析重写的方法“org.eclipse.cocl.xtext.essentialocl.ui.contentassi
-
使用OCSP从TLS获取证书链
我想使用OCSP检查证书,这是来自服务器在TLS握手。 我使用Bouncy Castle作为OCSP实现的提供者,而BC验证方法一般需要X509Certificate作为参数。
-
使用java验证证书链,检查撤销和OCSP状态
我对PKI的世界是新的,一般的证书。我正在写一个服务,需要验证证书链。 感谢所有的指示和帮助提前。感激不尽。 致以最诚挚的问候