《无领导小组讨论如何脱颖而出》专题
-
对 Redis 持久化的探讨与理解
目前Redis持久化的方式有两种: RDB 和 AOF 首先,我们应该明确持久化的数据有什么用,答案是: 用于重启后的数据恢复 Redis是一个内存数据库,无论是RDB还是AOF,都是其保证数据恢复的措施。 所以Redis在利用RDB和AOF进行恢复的时候,都会读取RDB或AOF文件,重新加载到内存中。 RDB RDB就是Snapshot快照存储,是默认的持久化方式。 可理解为半持久化模式, 即按
-
调整图像大小而不会变形OpenCV
问题内容: 我正在使用python 3和最新版本的openCV。我正在尝试使用提供的调整大小功能来调整图像大小,但是调整图像大小后会非常失真。代码: 原始图像为480 x 640(RGB,因此我将0传递给它来达到灰度) 有什么办法可以调整大小并避免使用OpenCV或任何其他库造成的失真?我打算制作一个手写数字识别器,并且已经使用MNIST数据训练了我的神经网络,因此我需要图像为28x28。 问题答
-
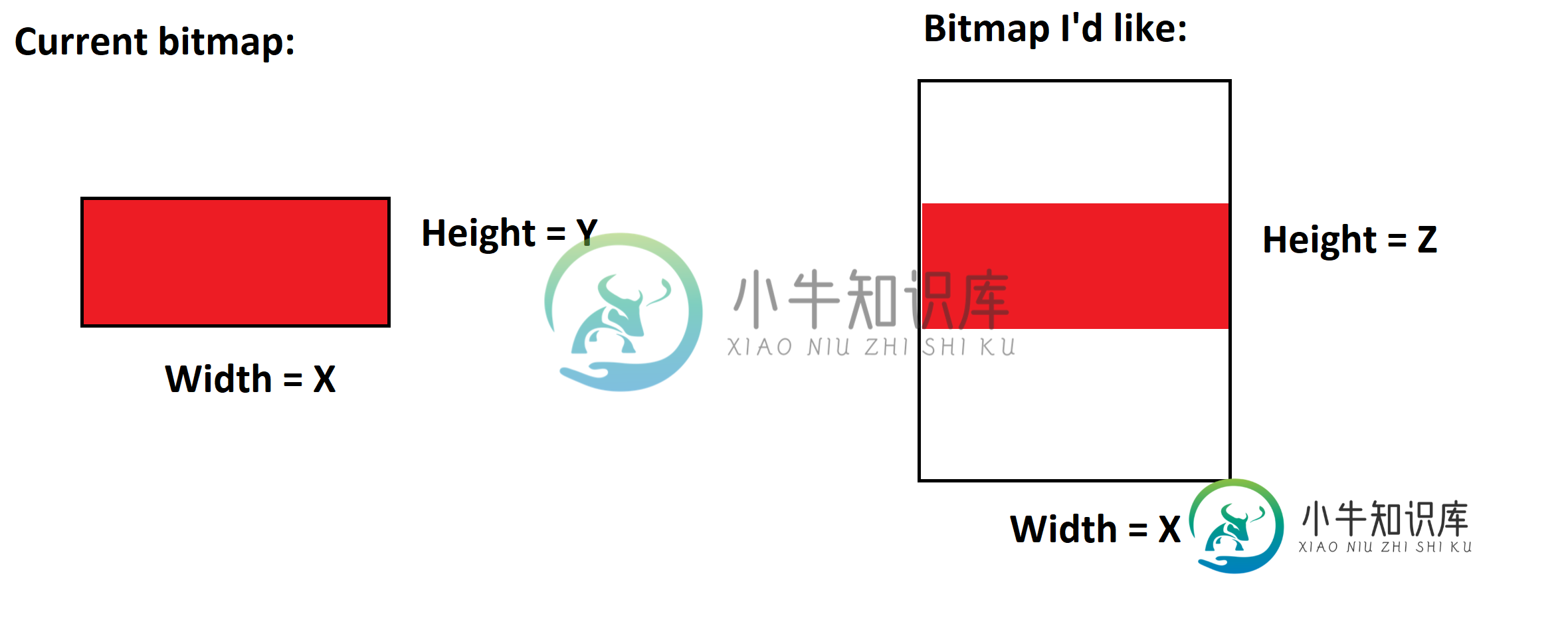 增加位图大小而不缩放图像
增加位图大小而不缩放图像我想在我的Android应用程序中增加位图的大小。 基本上,我想创建一个新的位图,其宽度与原始位图相同,但高度更大。(新)额外像素的背景可以是黑色、白色或透明。 我该怎么做?
-
有没有开源的小而美的软件?
比如kotlin swift java go写的记事本这样简单的软件。 想看看别人咋写的?
-
如何从用print_r打印的数组的输出创建数组?
问题内容: 我有一个数组: 而且我会: 打印: 有功能吗,所以在做的时候: 我会把阵列取回来吗? 问题答案: 我实际上写了一个将“字符串数组”解析为实际数组的函数。显然,它有点笨拙,但可以在我的测试用例上使用。这是http://codepad.org/idlXdij3上功能原型的链接。 对于那些不想单击链接的人,我也会在内联发布代码:
-
如何使用数组以及如何在Numpy中初始化多个数组?
我必须用Python写一个基于代理的模型项目,我需要初始化50个代理,每个代理都包含一组不同的数字。我不能使用50行的矩阵,因为每个代理(每行)可以有不同数量的元素,所以每个代理的向量长度不一样:当算法中出现agent_i的某些条件时,然后将算法计算的一个数字添加到它的向量中。最简单的方法是手动编写每一个这样的 但我当然不能。我不知道是否存在一种通过循环自动初始化的方法,比如 如果它存在,它将是有
-
你看一下,如果按照领导思想做一个产品,结果出现了问题,你觉得应该怎么解决?
本文向大家介绍你看一下,如果按照领导思想做一个产品,结果出现了问题,你觉得应该怎么解决?相关面试题,主要包含被问及你看一下,如果按照领导思想做一个产品,结果出现了问题,你觉得应该怎么解决?时的应答技巧和注意事项,需要的朋友参考一下 先想好对策(针对问题的解决方案),再去找老板汇报情况(产品出了什么问题,“我”拟的解决办法),看老板有什么指示或者建议,再根据老板的反馈去调整解决方案或者推动方案实行。
-
无法用GnuPG导出机密PGP密钥
在那之后,我试着拿回我的子键,以防它们还在身边。我可以看到我的钥匙和子钥匙在GPG钥匙串OSX应用程序。使用和进行列表时,我获得了与主密钥和子密钥相关联的所有公钥,但只获得了主密钥和其中一个子密钥的秘密(我没有导出到yubikey的那个)。 尝试调试更多,我决定使用一个较新版本的gpg来合并密钥等等,希望我能拿回秘密(我想在这一点上它已经不可能了,但我一直在尝试) 使用,它告诉我有一个主密钥和两个
-
Unity无法在Mac上导出Android项目
我正试图在Mac电脑上将Unity项目导出到Android系统,但遇到了以下例外: ExitGUIException:类型为“UnityEngine”的异常。已引发ExitGUIException。单位发动机。Gui实用程序。ExitGUI()(at/Users/builduser/buildslave/unity/build/Runtime/IMGUI/Managed/GUIUtility.cs
-
Java 11无法导出模块描述符
当我试图编译我的新的模块化Java 11应用程序时,我收到了这个错误消息: 这似乎是一个依赖项的依赖项的问题。我甚至找不到是哪个模块把它拉进来,这样我就可以更新它了。 我使用的是openjdk 11.0.2、IntelliJ 2018.3.4、Maven 有什么建议我可以如何解决或修复这个问题吗?我在这个问题上找到的文件很少。
-
MySQL工作台:无法导出数据库
我遇到了有关数据库导出的问题。首先,我必须澄清我正在使用MySQL Workbench 5.2.47。到目前为止,我遵循的过程如下: > 我按照http://mysqlworkbench.org/2012/07/migrating-from-ms-sql-server-to-mysql-using-workbench-migration-wizard/的指示创建了与MSSQL DB的连接,以便将其
-
无法从eclipse导出可运行的jar
我试图从eclipse导出一个可运行的jar,但结果是: 这是舱单: 其中Operazioni和Negozio是my包,itext是外部库
-
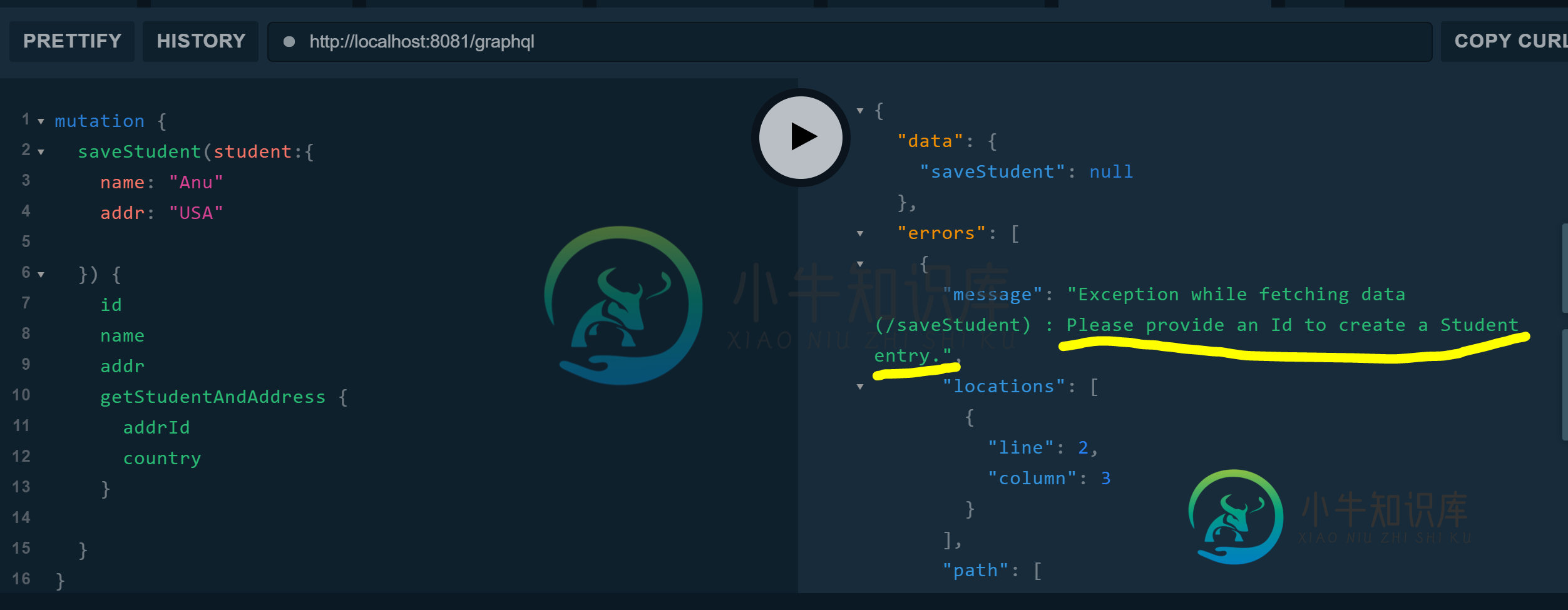 无法在graphql spqr spring boot starter中摆脱“获取数据时异常(/{apiName})”
无法在graphql spqr spring boot starter中摆脱“获取数据时异常(/{apiName})”我正在使用“io”的“graphql spqr spring boot starter”库版本0.0.4。利安根。图形QL’。我可以自定义错误。参考以下代码和屏幕截图: 型号: 服务等级: 自定义异常类: 然而,我不知道如何在获取数据(/saveStudent)时消除异常,如上面的消息字段截图所示。我知道我们可以有一个实现GraphQLErrorHandler(GraphqlJava kickst
-
检索引用其他论文的论文的标识符
我尝试使用ScopusAPI(pybliometrics)检索引用其他论文的论文标识符。 例子: 论文Franke et al.2020总共有3次引用(我使用获得这个数字) 有没有办法得到这3篇论文的标识符(dois,标题,...)?如果Scopus API不支持此功能,谷歌学者API是否支持此功能?
-
如何在python子进程之间传递大型numpy数组而不保存到磁盘?
问题内容: 有没有一种好方法可以在不使用磁盘的情况下在两个python子进程之间传递大量数据?这是我希望完成的动画片示例: 这将创建一个子进程,该子进程生成一个numpy数组并将该数组保存到磁盘。然后,父进程从磁盘加载阵列。有用! 问题是,我们的硬件生成数据的速度比磁盘读写速度快10倍。有没有一种方法可以将数据从一个python进程传输到另一个纯粹的内存中,甚至可能不复制数据?我可以做类似参考传递