《猫眼娱乐》专题
-
大熊猫:按二级索引范围对MultiIndex进行切片
问题内容: 我有一个类似MultiIndex的系列: 我想获得s [‘b’]值,其中第二个索引(’ ‘)在2到10之间。 在第一个索引上切片可以正常工作: 但不是第二种,至少从似乎是两种最明显的方式来看: 1)这将返回元素1至4,与索引值无关 但是,如果我反转索引,并且第一个索引是整数,第二个索引是字符串,则可以正常工作: 问题答案: 正如Robbie-Clarken回答的那样,从0.14开始,您
-
熊猫跨列求和,并从该值除以每个像元
问题内容: 我已经阅读了一个csv文件,并将其旋转为以下结构: 结果部分: 我想通过每一行在第0列到第13列之间求和,然后将每个单元格除以该行的总和。我仍然习惯于大熊猫。如果我理解正确,那么在执行此类操作时应该尝试避免for循环吗?换句话说,我该如何以“熊猫”方式做到这一点? 问题答案: 请尝试以下操作: 或者,您可以执行以下操作: 或者只是从头开始: 将列之类的标题更改为标题应该类似。
-
如何跨熊猫的多个数据框列“选择不同”?
问题内容: 我正在寻找一种等效于SQL的方法 pandas sql比较与无关。 仅适用于单个列,因此我想我可以合并这些列,或将它们放在列表/元组中并进行比较,但这似乎是熊猫应该以更原生的方式进行的操作。 我是否缺少明显的东西,或者没有办法做到这一点? 问题答案: 您可以使用该方法来获取DataFrame中的唯一行: 如果只想使用某些列来确定唯一性,则也可以提供关键字参数。请参阅文档字符串。
-
熊猫:如何将一列中的文本拆分为多行?
我正在处理一个大的csv文件,下一列的最后一列有一个文本字符串,我想用一个特定的分隔符来分割。我想知道是否有一种简单的方法可以使用pandas或python来实现这一点? 我想按空格分割,然后按列中的冒号分割,但是每个单元格将导致不同数量的列。我有一个重新排列列的函数,所以列在工作表的末尾,但是我不确定从那里做什么。我可以在excel中使用内置的函数和一个快速宏来完成,但是我的数据集有太多的记录需
-
根据数据类型获取熊猫数据帧列列表
如果我有一个包含以下列的数据帧: 我想能够说:这里是一个数据框,给我一个列的列表,它是类型Object还是类型DateTime? 我有一个将数字(Float64)转换为两位小数的函数,我想使用这个特定类型的dataframe列列表,并通过这个函数将它们全部转换为2dp。 也许 吧:
-
在熊猫[重复的]中转换为行的序列列表
我有一个数据框,如下所示 如何从它创建一个单独的x和y列?
-
Python如何使用熊猫编写新的csv文件[复制]
我只想从csv文件中返回这些特定列,并将其写入新的csv文件? 我该怎么做 到目前为止,我可以读取数据!!但不知道怎么写 绝对PYTHON BEGGINER警报
-
熊猫如何创建简单的跨标签没有聚合?
我有一个熊猫表3列:parent_male,parent_female,后代-所有字符串。我想创建一个简单的稀疏交叉表的男性和女性和后代作为值-我怎么能写一个aggfunc这样做。(不需要真正的聚合)-只需在空格中放一个空字符串。
-
熊猫如何传递DataFrame.assign参数以添加多个新列?
如何用于返回添加了多个新列的原始DataFrame的副本? 预期结果: 上面的示例导致: 。 背景: Pandas中的函数获取与新分配列关联的相关数据帧的副本,例如:。 此函数的0.19.2文档说明可以向数据帧添加多个列。 可以在同一分配中分配多个列,但不能引用在同一分配调用中创建的其他列。 此外: 参数: kwargs:关键字,值对 关键字是列名。 函数的源代码声明它接受字典:
-
如何选择和存储熊猫中大于数字的列?
我有一个带有整数列的熊猫数据帧。我想要包含大于10的数字的行。我能够评估真假,但不是实际价值,通过做: 我不经常使用Python,所以我将对此进行循环。 我花了20分钟在谷歌上搜索,但没有找到我需要的。。。。 编辑:
-
如果列值为NaN,熊猫数据框返回布尔值
我有一个包含多个列的DataFrame,我想检查特定的列值是否为NaN,如果是,我需要返回布尔值(True或False)。 我试过了 但它返回所有具有索引和布尔值的行。
-
熊猫-从数据框中完全删除重复项[重复]
我想从熊猫数据框中完全删除重复的项目。例如,我有数据框: 我要做的是在列中查找唯一的值,并删除所有重复的项。。因此,最终产品将如下所示(注意已消失): 谢谢。
-
熊猫:如何转换字典到转置数据帧?[重复]
我有一个列表的字典(等长),我想把它转换成一个数据帧,这样字典中的每个键代表数据帧中的一列(或一系列),并且对应于每个键的值列表被转换成数据帧中的单个记录专栏。 假设词典的内容是: 我希望dataframe的内容是: 我尝试通过首先将字典转换为数据帧,然后对数据帧进行转置来解决这个问题。 这给出了以下输出: 我不知道如何进一步进行。
-
熊猫-将字符串转换为字符串列表[重复]
我有这个“file.csv”文件要和熊猫一起读: 使用 输出为: 我知道,列是一个完整的字符串,因为: 我需要将其作为字符串列表来阅读,如。我尝试了这个问题中提供的解决方案,但没有成功,因为我的和字符实际上会把事情搞砸。 预期输出应为:
-
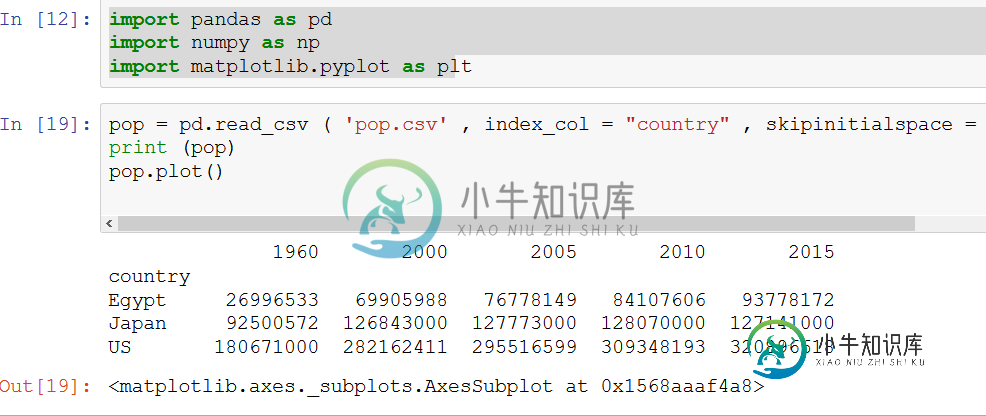 当试图绘制熊猫表时,绘制不显示[重复]
当试图绘制熊猫表时,绘制不显示[重复]我在CSV文件中有一些数据,想打印出来,但图形没有显示出来 这是CSV文件http://www.mediafire.com/file/2gtbxm5adom7m4j/pop.csv