《猫眼娱乐》专题
-
如何有效地迭代熊猫数据帧的连续块
问题内容: 我有一个大的数据框(几百万行)。 我希望能够对它进行分组操作,而只是按行的任意连续(最好大小相等)的子集进行分组,而不是使用各个行的任何特定属性来确定它们要进入的组。 用例:我想通过IPython中的并行映射将函数应用于每一行。哪行进入哪个后端引擎都没有关系,因为该函数一次基于一行来计算结果。(至少在概念上;实际上是矢量化的。) 我想出了这样的东西: 但这似乎很漫长,并且不能保证大小相
-
如何通过mysqldb将熊猫数据框插入数据库?
问题内容: 我可以从python连接到本地mysql数据库,并且可以创建,选择并插入单个行。 我的问题是:我可以直接指示mysqldb提取整个数据帧并将其插入到现有表中,还是需要遍历行? 在这两种情况下,对于具有ID和两个数据列以及匹配的数据帧的非常简单的表,python脚本的外观如何? 问题答案: 更新: 现在有一种方法,而不是: 另请注意:语法可能会在熊猫0.14中更改… 您可以使用MySQL
-
如何从熊猫数据帧在MySQL DB中创建新表
我最近从使用SQLite来满足大部分数据存储和管理需求过渡到使用MySQL。我想我终于安装了正确的库来使用Python3.6,但是现在我在从MySQL数据库中的dataframe创建新表时遇到了问题。 以下是我导入的库: 在我的代码中,我首先从CSV文件创建一个数据帧(这里没有问题)。 然后,我使用以下def函数建立到MySQL数据库的连接: 最后,我使用熊猫函数“to_sql”在MySQL数据库
-
熊猫有条件地以粗体格式格式化字段
我有一个熊猫数据框: 如果结果被认为是重要的,是否可以将单元格(如Excel表格中的单元格)设置为粗体,而不是添加带星号的列? 在一行中以粗体显示DataFrame()值似乎只能格式化整行-我想只重新格式化一个特定的单元格 有条件地格式化Python熊猫单元格 看起来很相似,虽然它们只改变背景,而不是粗体的格式。 下面的代码已经可以更改背景颜色了-我只是不知道如何设置为粗体。
-
不能扩展基类与猫鼬和打字脚本在NodeJS
我正在尝试使用Mongoose 4.5.4,它在NodeJS中的打字脚本(显然),同时使用存储库模式。 存储库库: 用户存储库: 我有以下类型错误调用从 类型的< code>[ts]参数 有人知道为什么吗?我的模型()的创建非常简单:
-
猫鼬:更新字段,推入数组中的对象[重复]
我想在mongo数据库的数组中添加一个元素: 结果很完美: 更新:猫鼬模式:
-
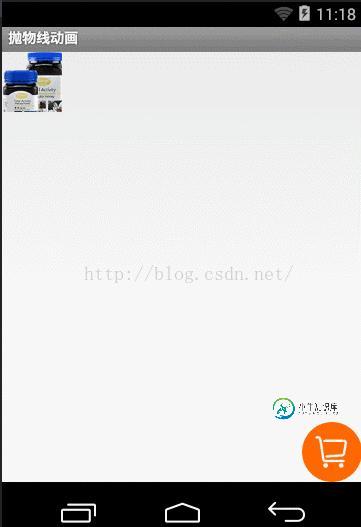 Android仿天猫商品抛物线加入购物车动画
Android仿天猫商品抛物线加入购物车动画本文向大家介绍Android仿天猫商品抛物线加入购物车动画,包括了Android仿天猫商品抛物线加入购物车动画的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Android仿天猫加入购物车的具体代码,供大家参考,具体内容如下 先上效果图 实现思路: 首先,我们需要三个Imagview 第一个是原商品图片, 这个图片是布局文件中创建的 我们称作A 第二个是做动画的图片 这
-
如何根据条件删除熊猫数据框中的列?
问题内容: 我有一个熊猫DataFrame,里面有很多值。 如何删除这样的列? 我试图这样做: 有更优雅的方法吗? 问题答案: 这是保留每列中小于或等于指定数量的nan的列的另一种选择: 在我的测试中,这似乎比李建勋在我测试的案例中建议的放置列方法要快一些:
-
在熊猫数据框中搜索和替换点和逗号
问题内容: 这是我的DataFrame: col2中的数据是本地格式的数字,我想将其转换为: 我尝试过,它返回ValueError::无法解析位置0处的字符串“ 9.876.543,21”。 我也尝试过,它返回ValueError:无法将字符串转换为float:‘5.023.654.46’ 谢谢你的帮助! 问题答案: 如果可能的话,最好使用: 如果不可能,那么应该有所帮助:
-
熊猫修剪数据框中的前导和尾随空白
问题内容: 开发可修剪前导和尾随空白的功能。 这是一个简单的示例,但是实际文件包含的行和列要复杂得多。 结果应消除所有前导和尾随空格,但保留文本之间的空格。 请注意,该功能需要涵盖所有可能的情况。谢谢 问题答案: 我认为需要检查值是否为字符串,因为列中的混合值-带字符串的数字和每个字符串调用: 如果列具有相同的dtype,则对于列中的数值,您的示例中不会得到:
-
熊猫python COUNTIF在具有多个条件的多个列上
问题内容: 我有一个数据集,其中我试图确定每个人的危险因素数量。所以我有以下数据: 每个属性(年龄,吸烟者,糖尿病)都有自己的条件来确定是否是危险因素。因此,如果年龄> = 45,则是一个危险因素。吸烟者和糖尿病为“ Y”是危险因素。我想要添加一列,以根据这些条件总计每个人的风险因素数量。因此数据如下所示: 我有一个样本数据集,我在Excel中鬼混,而我这样做的方式是使用COUNTIF公式,如下所
-
熊猫:在字段上使用不同名称加入DataFrames吗?
问题内容: 根据本文档,我只能在具有相同名称的字段之间建立联接。 您是否知道是否可以在名称不同的字段上连接两个DataFrame? SQL中的等效项为: 问题答案: 我认为您可以使用来实现。传递关键字参数作为,并告诉Pandas每个DataFrame中的哪一列用作键: 文档在本页上对此进行了详细描述。
-
单节点和项目中的猫鼬和多个数据库
问题内容: 我正在做一个包含子项目的Node.js项目。一个子项目将拥有一个Mongodb数据库,Mongoose将用于包装和查询db。但是问题是 猫鼬不允许在一个猫鼬实例中使用多个数据库,因为模型建立在一个连接上。 要使用多个猫鼬实例,Node.js不允许使用多个模块实例,因为它在中具有缓存系统。我知道在Node.js中禁用模块缓存,但是我认为这不是一个好的解决方案,因为它只需要猫鼬。 我尝试使
-
猫鼬-带有嵌入式文档的模型保存表格
问题内容: 将嵌入式阵列保存到Mongoose模型时遇到麻烦。 请参阅底部的编辑。 我有一种使用Mongoose在Express中创建BlogPost并将其存储在mongo中的数据的表单。我可以创建和查看新的博客文章,但是我只是在BlogPost模型中添加了嵌入式文档架构Feed,但无法获取Feed数组以将其从表单保存到模型中 码: BlogPosts.js web.js 翡翠形式 如果我填写此表
-
排序熊猫数据框中每一行的最快方法
问题内容: 我需要找到最快的方法来对具有数百万行和约一百列的数据框中的每一行进行排序。 所以像这样: 需要成为: 现在,我将排序应用于每一行,并逐行建立一个新的数据框。我还在每行中做一些额外的,不太重要的事情(因此为什么我使用熊猫而不是numpy)。改为创建列表列表,然后立即构建新的数据框,会更快吗?还是我需要去赛顿? 问题答案: 我想我会在numpy中这样做: 我曾以为这可能有效,但是它对列进行