《躺平》专题
-
如何停止Codenameone中的MapContainer类的拖动/平移
我尝试过使用MapContainer.setEnabled(false),但这似乎只在模拟器中起作用,在部署到真正的android设备上时没有效果。 提亚。
-
获取本地应用程序数据目录路径的跨平台方式是什么?
我需要的是一种与平台无关的方式来获取到本地应用程序数据目录的路径。似乎仅适用于Windows。我该怎么做呢?
-
地图vs平面地图在Reactor
我已经找到了很多关于RxJava的答案,但我想了解它在Reactor中是如何工作的。 我目前的理解是非常模糊的,我倾向于认为map是同步的,flatMap是异步的,但我不能真正理解它。 以下是一个例子: 我有文件(a
-
当最小化/还原动画打开时,如何在移除任务栏按钮之前平滑最小化窗口?
我正在最小化一个表单到系统托盘(显示一个托盘图标),同时保留它的任务栏按钮,当它没有最小化。这意味着在窗体最小化时移除任务栏按钮,否则将其还原。 实现这一点的最简单方法是隐藏/显示窗体,最小化的窗口无论如何都不会显示。 ,如果我移动代码(更不用说窗口可以通过 等最小化),它不会导致任何进展。 没有它。这里类似的问题试图处理第一次显示窗口时显示的动画,尽管该动画似乎与DWM相关,并且Minimize
-
如何使用struts 2动态更改平铺3属性值?
我的文件。 我有一个Struts2Action,它从数据库中获取数据并填充在在showdefinition中,我再次为另一个工作使用了另一个相同操作的方法,这次我填充了列表视图定义,但我以前的不保留其值。 我被困在这一个星期了,请帮帮我。
-
如何在Realm移动平台中管理会话?
我试图使用Realm移动平台(Swift 3)制作一个具有实时协作的iOS应用程序,但由于缺乏文档和示例而陷入困境。目前我已经通过领域对象服务器进行了用户身份验证。我可以在服务器和所有用户之间同步数据。现在我希望两个用户在一个会话中连接,然后像在他们的绘图演示中一样在他们之间同步数据(观看https://realm.io视频)
-
Google云平台数据ETL批处理:云函数数据流
在我的新公司,我是一名数据工程师,负责构建google cloud platform(GCP)批处理ETL管道。我的团队的数据科学家最近给了我一个数据模型(用Python3.6编写的.py文件)。 数据模型有一个主函数,我可以调用它并获得一个dataframe作为输出,我打算将这个dataframe附加到一个bigquery表中。我是否可以只导入这个主函数,并使用apache beam(Dataf
-
Kafka到Google云平台的数据流摄取
主题中的Kafka数据可以被流式传输、消费和吸收到BigQuery/云存储中,有哪些可能的选项。 按照,是否可以将Kafka与Google cloud Dataflow一起使用 GCP自带Dataflow,它建立在Apache Beam编程模型之上。KafkaIO与Beam Pipeline一起使用是对传入数据执行实时转换的推荐方式吗? https://beam.apache.org/releas
-
带有平衡组的Regex可以处理负前瞻,但不能处理正前瞻(.net方言)
我发布了这个问题的答案,其中OP希望正则表达式匹配不同的JSON类型数据块,条件是其中一个属性具有特定值。 稍微简化一下问题 - 假设一些示例数据如下: 正则表达式应该与匹配,但仅限于存在数据元素的地方。 我在回答中的正则表达式是: < code>layer\s*{(? 它不是明确识别包含< code>foo的匹配,而是排除那些包含< code>fee的匹配。如果所有非< code > fee -
-
基于SAP Hybris的电子商务平台
Hybris适合这些任务吗? 谢谢!
-
Spring Data JPA:如何在RDS Aurora PostgreSQL实例之间负载平衡读取查询?
我在AWS中创建了一个Aurora PostgreSQL集群: Writer实例有一个endpoint,Reader实例有一个endpoint: 在我的应用程序中,我像往常一样定义了一个数据源: 同样,代码中定义了一些普通实体和存储库: 同样,也有一些普通的读/写操作: 问题是所有这些查询都被发送到Aurora的Writer实例,而我的Reader实例仍然没有被使用。 但是我希望诸如,exists
-
树视图项中的绑定错误(水平和垂直内容对齐)
我得到这些错误。我读了几个帖子,我的TreeViewItem确实定义了Horizontal和VerticalContentAlignment。有趣的是。NET 4.0让这个错误消失了(我使用3.5 -否则我会遭受这个https://connect . Microsoft . com/visual studio/feedback/details/588343/changed-behavior-fro
-
C中平方根不打印的向量[重复]
我在制作一个向量时遇到了麻烦,它会返回向量的原始元素平方。 这是我得到的错误。
-
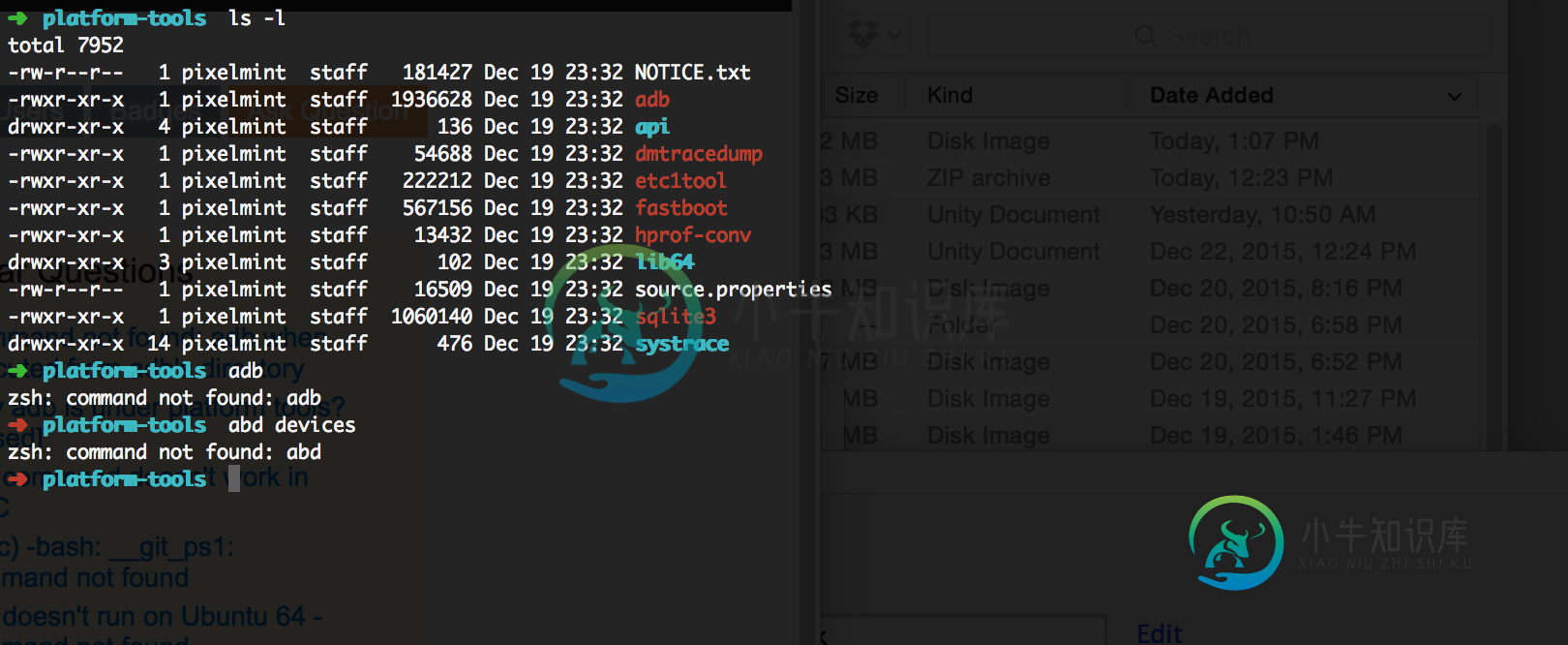 adb:在Mac OS X Yosemite上未找到命令(从平台工具目录中)
adb:在Mac OS X Yosemite上未找到命令(从平台工具目录中)最终,我会尝试获取note 5的设备id。 我已经安装了Android Studio以及平台工具23.1 当我使用终端进入平台工具文件夹并键入adb时,我得到“未找到命令” 有什么想法吗? 谢啦
-
如何将熊猫的数据文件放平?
所以我得到了一个看起来像这样的数据帧:原始数据帧 我需要对数据帧进行转换,使其看起来如下所示: 有谁知道怎么用熊猫?