《躺平》专题
-
如何使两个docker容器之间的nginx反向代理负载平衡?
我尝试在使用相同nodejs应用程序的两个容器之间实现nginx反向代理负载平衡。 目录结构: docker撰写。yml:
-
web应用程序的负载平衡是如何工作的?一般概念
我正在努力弄清楚我是否正确理解负载平衡。我有一个用XAMPP开发的web应用程序。基本上我有一个数据库和应用程序本身。之后,我在运行Ubuntu的VPS中的Digital Ocean中托管了该应用程序,并在其中安装了ApacheMySQL和PHP。现在我想了解负载平衡的要求。 从我到目前为止所读到的关于负载平衡的内容来看,您至少需要3台服务器,其中一台将是Apache或NGINX,并打开相应的负载
-
Nginx负载平衡上游代理
我需要一些nginx负载平衡方面的帮助。我有一个docker实例,它服务于一个静态网页,它有两个容器,比如说192.168。1.1:8081 - 当我输入这些IP地址192.168.1.1时,这些IP必须服务于我的两个站点之间的负载。 在我的Nginx中,我必须为此设置两个文件 Nginx。conf,在这些文件中,我必须包含我的默认值。conf文件。违约conf文件包含以下信息。 当我键入192.
-
内部和面向internet的弹性负载平衡
我们试图在自动缩放的AWS中使用弹性负载平衡,这样我们就可以根据需要进行缩放。 我们的应用程序由几个较小的应用程序组成,它们都位于同一子网和同一VPC上。 我们想把我们的ELB放在一个应用程序和其他应用程序之间。 问题是我们希望负载均衡器在内部使用API的不同应用程序之间工作,并且面向互联网,因为我们的应用程序仍然有一些应该在外部而不是通过API完成的用法。 我已经读过这个问题,但我无法从那里准确
-
需要澄清nginx和负载平衡
我现在正在阅读Instagram的设计,我发现了对他们负载平衡系统的这样一个描述。 每个对Instagram服务器的请求都要经过负载平衡机;我们曾经运行过2台nginx机器,并在它们之间进行DNS循环。这种方法的缺点是DNS更新所需的时间,以防其中一台机器需要取消使用。最近,我们开始使用Amazon的弹性负载平衡器,它后面有3个NGINX实例,可以进行交换(如果运行状况检查失败,它们会自动停止循环
-
云中自定义客户端服务器应用程序的负载平衡
我正在设计一个定制的客户机-服务器tcp/ip应用程序。应用程序的网络要求如下: 能够通过安全的TCP/IP通道(在指定端口打开)说出自定义应用层协议。 设计目标之一是使应用程序具有可扩展性,因此负载平衡尤为重要。我一直在研究EC2和WindowsAzure的负载平衡功能。我相信现在大多数产品都支持要求1。但是我不太确定要求2和3。特别地: > 这些服务(EC2、Azure)是否允许应用程序通过指
-
AWS负载平衡节点。端口3000上的js应用程序
我有一个节点。js Express web应用程序使用默认端口3000,通过弹性ip在Ubuntu EC2实例上响应良好。我试图在AWS中设置内置的负载平衡,但似乎无法通过良好的运行状况检查 安装2个ubuntu服务器,服务器应用程序罚款在端口3000. 将端口80的负载平衡器侦听器设置为路由到实例端口3000,并尝试将3000路由到3000。 将amazon-elb/amazon-elb-sg安
-
基于Cookie的WebSocket负载平衡?
我的情况是,我们目前正在编写一个使用Node的在线应用程序。服务器端的js和WebSocket侦听器。我们有两个不同的部分:一个是服务页面,另一个是使用节点。js和express ejs,另一个是完全不同的应用程序,只包含套接字。用于WebSocket的io库。现在我们来讨论WebSocket部分的可伸缩性问题。 我们发现的一个解决方案是使用redis并在服务器之间共享套接字信息,但由于体系结构的
-
Mongodb平衡非常慢
我们的集群正在经历非常缓慢的平衡。在我们的日志中,迁移进展似乎几乎没有进展: 此外,当我们分割一个新的集合时。它最初只从同一个主副本集中的8个块开始。它不会将块迁移到其他碎片 我们的配置是4个副本集(主要,次要,仲裁)
-
这些站点使用的是哪个平台?[关闭]
请谁能帮助我确定哪些CMS这些网站正在使用?我如何为自己建立同样的博客。我该用哪种技术。 网站链接:https://www.creativebloq.com/https://www.pcgamer.com/
-
使用Java8流获取最大平均科目成绩
-
如何让 maven 构建平台独立?
在我的mac上使用Maven构建时,在< code>mvn install上,我得到 [警告]使用平台编码(实际上是MacRoman)来复制过滤的资源,即构建取决于平台! 是否可以为给定平台 (Linux) 构建或以其他方式独立于构建平台?
-
协议缓冲区和平面缓冲区有什么区别?
两者都是序列化库,由谷歌开发人员开发。他们之间有什么大的区别吗?将使用协议缓冲区的代码转换为使用FlatBuffers需要大量工作吗?
-
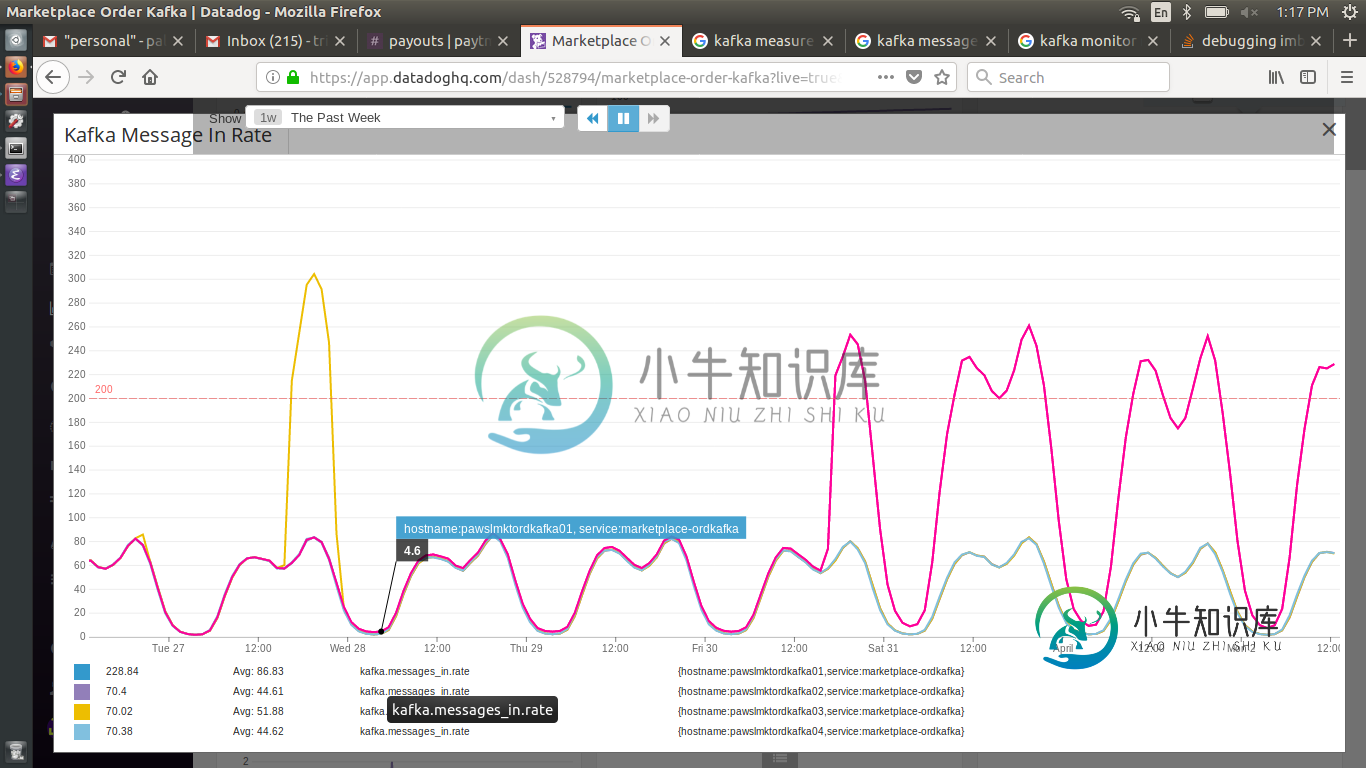 调试不平衡Kafkamessage_in
调试不平衡Kafkamessage_in集群由4个节点中的每个节点上的16个引线进行平衡 ISR在4个箱子中也保持平衡,每个箱子有32个ISR[复制系数为2] 所有4个盒子上的网络输入和输出几乎相等 请求任何帮助或可以查看的领域/指标来调试此异常。 对于将来正在搜索此信息的人https://mail-archives.apache.org/mod_mbox/kafka-users/201710.mbox/
-
Kafka消费群体行为不平等
试图理解Kafka中的消费者群体行为。示例4分区可用。在消费者方面,消费者群体控制着4个消费者。在这种情况下,在消费者组中的4个消费者中,只有一个消费者始终收到消息。其他人总是无所事事。可能的原因是什么? 是否所有分区都保存相同的消息?或者所有分区都有相同的消息?或者我们可以认为分区不是均匀分布的吗?