《经验分享》专题
-
Tag Manager使用经典分析进行跨域跟踪
有许多客户端站点使用其主域的类似系统以及托管在其他地方的外部签出软件。他们的分析充满了来自主要领域的自我推荐。例如 我有一个主域,在其中我拥有全部控制权。这有一个使用Universal Analytics的Google Tag Manager实现。第二个域是一个预订系统,使用经典分析。 我无法控制预订系统上的分析是如何实现的(除了设置跟踪ID),但开发人员说它设置为使用跨域跟踪。它们的实施有: 我
-
 中国电信广东省分公司面经(已offer)
中国电信广东省分公司面经(已offer)IT开发工程师岗位 总体就是行测+性格测评 记得留给性格测评至少10min的时间,虽然规定的是20min,但是10min绰绰有余。 行测总体不难,我记得是没有资料分析(那种大段文章,然后三四道关于文章的选择题),还有关于中国电信的题目(什么时候成立的?理念?要求员工以人为本具体要求什么?天翼云的理念?)建议考前集中看一下,总共时间基本要求1min1道题,我在复习公务员行测所以觉得不难,基本上都是公
-
python新手经常遇到的17个错误分析
本文向大家介绍python新手经常遇到的17个错误分析,包括了python新手经常遇到的17个错误分析的使用技巧和注意事项,需要的朋友参考一下 1)忘记在 if , elif , else , for , while , class ,def 声明末尾添加 :(导致 “SyntaxError :invalid syntax”) 该错误将发生在类似如下代码中: 2) 使用 = 而不是 ==(导致“S
-
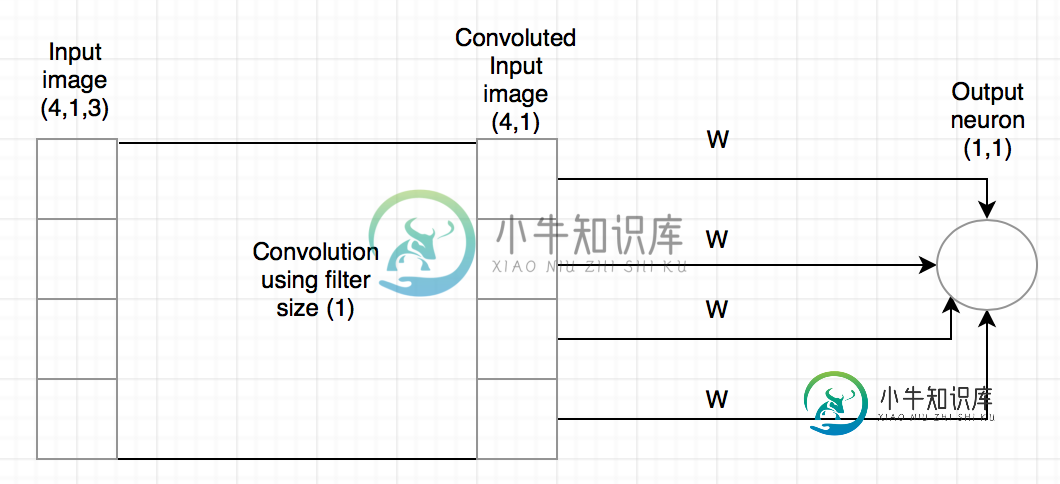 了解卷积神经网络中的权重分配
了解卷积神经网络中的权重分配我目前正在尝试理解卷积神经网络中的权重分配实际上是什么。 据我所知,CNN首次引入是为了减少连接输入和输出所需的连接数量,因为输入具有3个维度。 根据这一逻辑,我认为卷积减少了其中一个维度,并将卷积图像连接到输出神经元。 连接卷积图像和输出的权重是否是未共享的权重?如果没有,哪些权重是不共享的?。 或者,如果是,则反向传播将其视为一个权重,并将其更新为一个单位?
-
火花中的coalesce(Num分区)是否经过洗牌?
我在火花变换函数中有一个简单的问题。 coalesce(numPartitions) - 将 RDD 中的分区数减少到 numPartitions。可用于在筛选大型数据集后更有效地运行操作。 我的问题是 > < Li > < p > coalesce(num partitions)真的会从filterRDD中删除空分区吗? coalesce(numPartitions)是否经历了洗牌?
-
第二部分弹性反向传播神经网络
这是本帖的后续问题。对于一个给定的神经元,我不清楚如何得到它的误差的偏导数和它的权重的偏导数。 通过这个网页,我们可以清楚地看到Propocation是如何工作的(尽管我处理的是弹性传播)。对于一个前馈神经网络,我们必须:1)在向前通过神经网络时,触发神经元;2)从输出层神经元,计算总误差;3)向后移动,以每个神经元的权值来计算该误差;4)再次向前移动,更新每个神经元的权值。 不过,这些都是我不明
-
 众安保险-数据分析暑期实习面经
众安保险-数据分析暑期实习面经说实话都不记得什么时候投递的简历,就突然邮件通知面试 一面 2022.07.0.1 1、自我介绍 (中间面试官有介绍所在部门的业务以及该岗位的职责) 2、后来又来了一个面试官(应该是做技术的),上来就问sql的执行顺序 3、表连接方式有哪些及其区别? 4、sql题,表A和表B,a.id = b.id ,保留两表的所有字段,用哪种连接方式?若没有共同的字段,用什么连接(union)?union 和
-
 双非本科数据分析实习面经汇总
双非本科数据分析实习面经汇总第三份实习也确定下来了,如果毕业确定工作的话,这应该是本科阶段最后一次实习了。前前后后也面了很多家大公司的实习,面试的过程真的是五味杂陈,双非本科的title真的让自己在找实习过程中吃了太多苦头,当然跟自己硬实力还不够也有很大关系。把实习面经汇总一下,希望能给想找数分实习的小伙伴一些经验 一、网易严选-电商市场数据分析实习生 笔试:给一份数据,做一份数据分析报告 业务面(15min): 1.介绍一
-
 龙湖秋招面经 数据分析一二三面
龙湖秋招面经 数据分析一二三面时间线:9.4投递,9.16一面,9.21二面(和hr改的时间),9.26三面,全程hr电话约面 一面技术 1. 特征工程常用方法 归一化标准化、离散化(分箱、onehot编码)、组合降维等等 2. 分类样本不均衡如何解决 欠采样、过采样 3. 针对A/Btest经历——如果使用抽样调查方法如何确定样本量和分桶(统计学意义上)
-
 东方财富数据分析-一面二面凉经
东方财富数据分析-一面二面凉经一面 30min 视频面 挖简历,没什么技术知识,面试官人很好,感觉有点憨憨的。 二面 30min 视频面 凉经 主管面 先说明他做的很产品,所以问的我基本上都是关于业务的。没什么相关经验,答得不太好。 一些开放的问题包括: 买过理财产品吗? 在用什么理财APP? 如果让你做竞品分析,你觉得它们之间的区别是什么? 感觉还是要比较了解他们的APP,比较了解他们的产品。 最后面试官点评我说还是要多用产
-
 2023届校招面经:猿辅导-数据分析师
2023届校招面经:猿辅导-数据分析师TimeLine:一面20220820,二面20220827(已挂) BG:北邮本硕,管理类专业,两段实习经历:字节数据分析师、美团商业分析师 笔试 涉及统计学、概率论、机器学习、SQL等方面的知识,详情可在牛客网上搜索“猿辅导数据分析笔试”获取更多信息 一面 1. SQL题,口述解法即可 课程信息表lesson_order,字段:学科 subject, 用户id userid, 订单id ord
-
 快手电商数据分析实习面试(凉经)
快手电商数据分析实习面试(凉经)快手电商面试好难啊,面试官是个特别好的小哥,不过问的问题还是暴露了我能力不足啊感觉凉了啊。 首先是他自我介绍,快手电商用户买家提升部门的,然后介绍了面试环节。首先是自我介绍;接着是简历问题,要求我介绍下在Kaggle上的项目经历;接下来是问题环节,首先问我ABtest流程,幸好我之前恶补了说完之后他的评价是还行,如果有具体场景应该能更清楚,但是接下来就是一个我完全没记住的问题了,计算最小样本量需要
-
 字节跳动数据分析面经(生活服务)
字节跳动数据分析面经(生活服务)面试大概30min 自我介绍 之前做过的一个比较完整的数据分析:分析背景目的,问了几个细节,以及当时有哪些做的不够好的地方。感觉这个问题回答的不是很好。 之前工作中的亮点 : 我回答的是把定性数据问题定量分析,但是感觉举得例子不好,没有很好的体现这个亮点。 常用的app:小红书,哪些可以改进的点。我说的同城分类下面的地点或者商家展示时效性不够好,丰富度不够。问怎么判断这个问题,怎么优化。 对抖音生
-
 面经-快手海外版-数据分析实习生
面经-快手海外版-数据分析实习生一面 1.SQL table_a dt, city_id, device_id, gmv tips:每个device一天可能有多条记录 (1)求每个城市每天gmv最高的5个device_id (2)求连续三天每个城市每天gmv都在前5的device_id 2.统计题 (1)自变量存在多重共线性,如何通过变量筛选来解决? (2)线性回归的五个基本假设 3.机器学习 (1)DBScan 与 Kmean
-
 哈啰打车-数据分析实习-面经 v.23.02.17
哈啰打车-数据分析实习-面经 v.23.02.17一面 23.02.14: 自我介绍 实习深挖 搭建看板选取了哪些指标?(效率、后验、用量;效率最为重要,具体讲了指标,额外提到了一个预算达成率) 你这个预算达成率具体是指?或者说你们也有预算么?(有的,和哈啰不太一样的是,我们的预算其实就是指分配的运营流量,我们分给他们一个定额,他们再自己配置到单卡上;我们的预算达成率就是他们投放卡片的启播量比上他们的预算总值,如果这个达成率在周环比上有一个比较大