《微派》专题
-
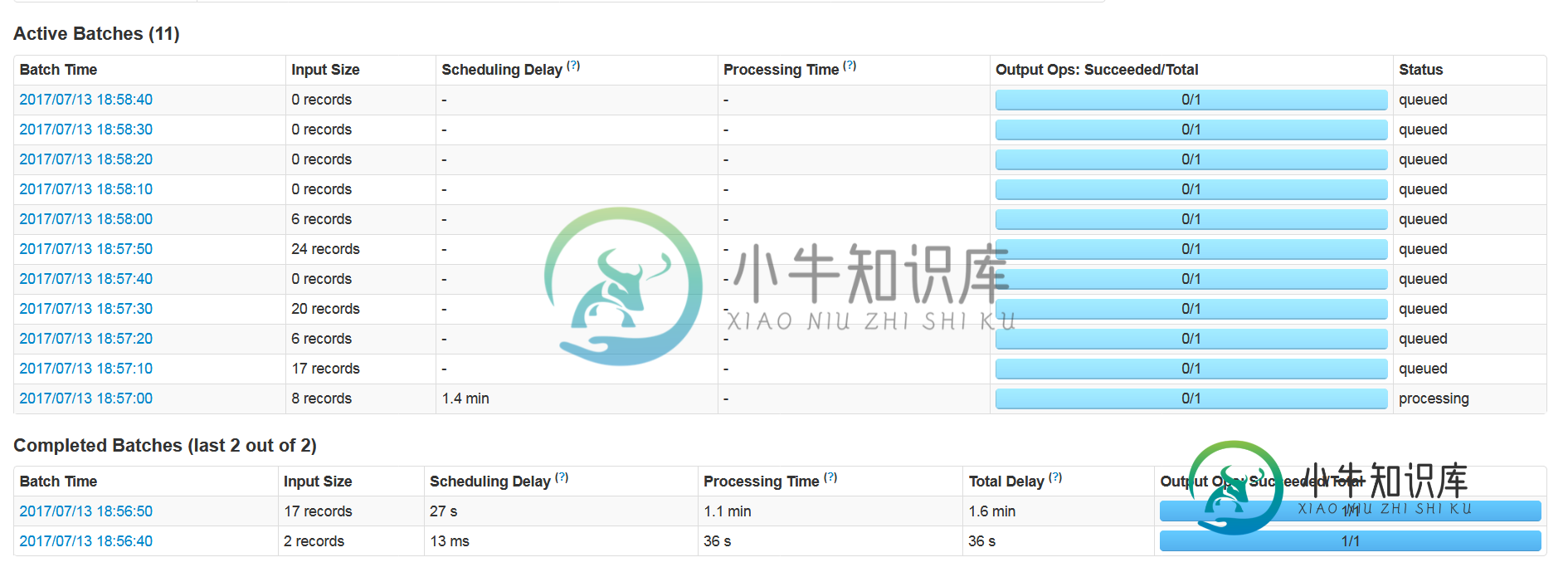 Spark Streaming:微批并行执行
Spark Streaming:微批并行执行我们正在接收来自Kafka的星火流数据。一旦在Spark Streaming中开始执行,它只执行一个批处理,其余的批处理开始在Kafka中排队。 我们的数据是独立的,可以并行处理。 我们尝试了多个配置,有多个执行器,核心,背压和其他配置,但到目前为止没有任何工作。排队的消息很多,每次只处理一个微批处理,其余的都留在队列中。 我们从差异实验中得到的统计数据: 实验1 100个文件处理时间48分钟 1
-
Kubernetes微服务版本控制
我对Kubernetes还很陌生,只是从一个示例项目开始学习。我目前正在运行一个.NET微服务,它需要一个MongoDB作为数据库。微服务被打包到Docker映像中,我创建了一个单独的Helm图表来正确部署我的微服务和所需的MongoDB。 是这样做的吗?还是我错过了什么?所有给我指明正确方向的线索都非常欢迎!
-
跨REST微服务的事务?
假设我们有一个用户、Wallet REST微服务和一个将事情粘合在一起的API网关。当Bob在我们的网站注册时,我们的API网关需要通过用户微服务创建一个用户,通过钱包微服务创建一个钱包。 下面是一些可能出错的场景: > 用户Bob创建失败:没关系,我们只需向Bob返回一个错误消息。我们使用的是SQL事务,所以没有人在系统中看到Bob。一切都很好:) 创建了用户Bob,但在创建钱包之前,我们的AP
-
微服务未在Eureka注册
我刚刚关注了下面这篇文章,https://spring.io/blog/2015/07/14/microservices-with-spring,但是我无法在尤里卡注册我的微服务。 customer-service.yml build . gradle for customer-service CustomerService.java 注册-server.yml
-
Apache NiFi中的微秒解析
我想通过CSVRecordReader将以下包含以微秒为单位的时间戳的CSV内容转换为通过AvroRecordSetWriter的AvroRecord: 我使用以下Avro模式: 但是CSVRecordReader似乎将微秒解释为毫秒,因此AvorRecordSetWriter的输出包含另外三个零: 时间戳字段将假定为自epoch(格林威治时间1970年1月1日午夜)以来的毫秒数https://n
-
Spring微服务超时docker swarm
我有三个服务的spring-cloud应用程序:Eureka服务器+网关(zuul)+用户服务(2个实例) 在localhost中,所有的东西都在工作,我可以访问: Docker创建了4个容器,所有3个服务都注册在Eureka-Server中: Eureka注册网关和2个用户服务实例 用户服务实例的ip: null application.yml Docker-Compose:
-
域对象共享微服务
我试图理解微服务。我想知道如何解决微服务架构中的一对多/多对多关系问题,以及最佳实践是什么。假设我想将学生课程应用程序转换为学生服务,将课程服务和学生服务对话转换为同一数据库中的学生表和课程服务对话课程表。 示例:学生可以注册许多课程,而且许多课程可以有许多学生(多对多关系)。我有2个微服务1:学生服务2:课程服务 学生服务有学生对象 课程服务具有课程对象 我知道学生服务部必须致电课程服务部才能获
-
Spring使用微服务架构
我正在构建一个基于Spring启动中的微服务架构的项目。该项目分为多个模块,我使用了 maven 依赖项管理。 现在我想在另一个模块中使用一个模块的服务。我有很多Spring申请。例如,我有两个名为A和B的应用程序。我想在B中使用A中的类,在A中使用B中的类。在这种情况下,我使用了maven依赖项,但这并不完全是在另一个应用程序中使用服务的方式,因为我面临循环依赖。 该如何解决这个问题?
-
spring boot微服务maven架构
我目前正在构建一个具有微服务架构的 Spring 启动应用程序。我正在寻找重用代码的干净方法。 我的想法是在共享模块中提取通用代码。(例如,微服务中的模型类继承的基类,在任何MVC控制器中重用的接口,每个绑定上下文都相同的域代码)。具体的实现和仅服务的模型类等都在子模块(微服务)级别。 我正在与maven一起构建东西,并管理依赖关系。我的问题是如何在这样的设置中构造maven模块和依赖项。 共享库
-
Docker容器中的微服务
我正在使用Spring Cloud创建微服务架构。 我正在使用Spring Cloud中的以下功能 Zuul–API网关服务,提供动态路由、监控、弹性、安全等功能- 功能区–客户端负载平衡器 Faign–声明性REST客户端 Eureka–服务注册和发现 Sleuth–通过日志进行分布式跟踪 Zipkin–具有请求可视化的分布式跟踪系统 Hystrix-适用于所有API的断路器、容错、Hystri
-
Kafka微服务正确用例
在我的新作项目中,我发现,一个微服务不会直接对另一个微服务进行post/put API调用,而是会向kafka生成一条消息,然后由单个微服务使用。 例如,Order微服务将向“Pending-Order”主题发布一条记录,然后该记录将被Inventory微服务(没有其他消费者)消费。反过来,在消费记录并进行一些处理之后,Inventory微服务将生成一个“Processed-Order”的记录,然
-
架构微服务Spring引导
-
作为微服务的用户
创建一个单独的服务来管理数据(如用户管理),这是一个好的实践吗?实现之后,只有该服务将有权访问用户和其他相关的DB表。所有其他服务都必须调用这个新的用户微服务来执行与用户相关的任务。 这种方法将迫使我们通过添加反规范化来重构DB模式。我们不会得到在多个微服务之间提供的基础表。如果服务器服务需要数据,它将通过微服务共享。
-
稍微快一点的Bellman-Ford
我对贝尔曼-福特做了一点修改,这样它只能“有用”放松。也就是说,d(v)的松弛被更新了。 现在,如果所有最短路径最多有k条弧。那么最坏情况下的运行时是O(V*k),因为在这个智能版本中我们只经过k个弧。这比原来的O(V*E)快一点,因为| k| 有谁能告诉我一种图的类型,这种改进的版本并不比原来的Bellman-Ford算法好?也就是说,最佳情况下的性能是O(V*E)
-
微融合和寻址模式
我使用英特尔®架构代码分析器(IACA)发现了一些(对我来说)意想不到的东西。 以下使用寻址的指令 不符合IACA规定的微型保险丝。但是,如果我这样使用