《群面》专题
-
AWS ElastiCache SSL安全群集Spring数据Redis“Redis运行状况检查失败”
我们正试图通过启用SSL加密来保护我们的ElastiCache集群到Spring Boot流量。Spring Boot应用程序成功启动,但当它尝试在Eureka上注册时,Spring Boot Admin失败,出现异常: 设置: Spring Boot版本2.1.4。发布 工作流程: 应用程序启动并连接到ElastiCache群集 一段时间后,10-20秒<代码>Redis health chec
-
为什么我在尝试计算集群时派生未处理的异常
OpenCV错误:断言失败(data.dims<=2&&type==CV_32F&&K>0),在未知函数中,文件.....\src\OpenCV\modules\core\src\matrix.cpp,第2485行未知异常 我不明白为什么会这样。我试图改变参数,但无济于事。 你能给我一些解决这个问题的办法吗? int main(int argc,char*argv[]){ }
-
在JBoss 7.1.1中为MySQL集群创建XA数据源:连接只读错误
我们正在JBoss7.1.1应用服务器中为后端集群MySQL服务器配置XA数据源(主-主配置)。以下是数据源配置: 我们面临以下问题: 在DB URL jdbc:mysql:/10.2.0.35:3306,10.2.0.36:3306/test_prod?autoreconnect=true中,如果10.27.40.35服务器关闭,则给出以下异常。但是如果我将URL配置反向为jdbc:mysql:
-
使用 Helm 安装从构建计算机到远程 kubernetes 群集的图表
我正在为我的项目设置jenkins管道,它基于k8s并使用helm图表进行安装。我有一个单独的集群,jenkins需要使用helm安装我的应用程序。 我的问题是,我应该如何在不同的机器上安装头盔?我的jenkins服务器没有舵。使用ssh命令在远程集群中安装是一种好的做法吗?是否有一个mvn或helm客户端可以在远程机器上安装图表?
-
 如何通过Java驱动程序正确连接Atlas M0(免费层)集群?
如何通过Java驱动程序正确连接Atlas M0(免费层)集群?正在尝试使用MongoDB 3.6版通过Java驱动程序连接Atlas群集。 所以,我写的是: 在这种情况下,错误是: 当程序以使用MongoDB 3.6版或更高版本的snippet开始时,不使用: 在POM文件我有依赖: 此外,当我启动时,我的数据库会添加到此地址,但我为集群添加了路径,但不是为了这个。也许我需要写具体集群的路径,或者? Ofc,我有管理员用户。此外,我还可以通过Compass连
-
在不使用集群的情况下将Azure Blob存储加载到Azure Databricks
谢谢
-
如何才能等到RabbitMQ消息同步到集群中的其他节点?
我有一个三节点的rabbitmq集群。这是我正在使用的集群(不是我的)https://github.com/bijukunjummen/docker-rabbitmq-cluster。 我遇到了一个问题,如果我用ha-policy=all向队列发送大量消息,并不优雅地关闭服务器,则其他节点上的消息并不都可用。 这在Java RMQ库中可能吗? 谢了。
-
Apache Cassandra 3.11.6:群集键错误,cass-stress写入后表中未定义列名
我目前遇到了一个问题,即我试图从cassandra中选择或插入特定的列数据,并不断得到未定义的列名错误,尽管列名是查看表时的聚类键。但是,其他列的行为正常。 此外,在插入数据时,尽管column1是“未定义的”,但仍需要它作为集群键 这是从3.11.4开始改变的预期行为吗?
-
使用IF NOT EXISTS进行带有主键和群集列的唯一插入
当有主键和集群列时,如何使用IF NOT EXISTS执行LWT。我只希望只有当主键不存在时才应用插入。我不希望逻辑包含主键+集群列。
-
无法将gsutil与工作负载标识功能一起用于GKE群集
我为我的GKE集群启用了workload identity功能,它运行良好。 我没有问题访问具有Google Cloud服务号的正确IAM权限的命令,但是我不确定如何在启用workload_identity时在kubernetes Pod中使用命令。 基本上我的问题是,当workload_identity启用时,是否有办法使用gsutil? 在我的pod中使用时,我看到了这个错误
-
高可用和集群简述 - 高可用主要场景和对应思路
适用于redis非重度用户,内存占用不大,总体内存大小的增长趋势可预估,有一定停机时间的系统——纵向扩容即可满足,可以对全库进行主从复制即满足需求而不需要做分片,一般针对单个小型项目的cache 等场景。一般采用一主多从的sentinel方案进行部署。
-
 最新华为OD机试真题-API集群访问频次统计(100分)
最新华为OD机试真题-API集群访问频次统计(100分)🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-D卷的三语言AC题解 👏 感谢大家的订阅➕ 和 喜欢💗 📎在线评测链接 => API集群访问频次统计(100分) <= 🌍 评测功能需要 =>订阅专栏<= 后联系清隆解锁~ 🍓OJ题目截图 ✨ API集群访问频次统计 问题描述 某个产品的 集合部署在多个服务器节点上。为了实现负载均衡,需要统计各个 的访问
-
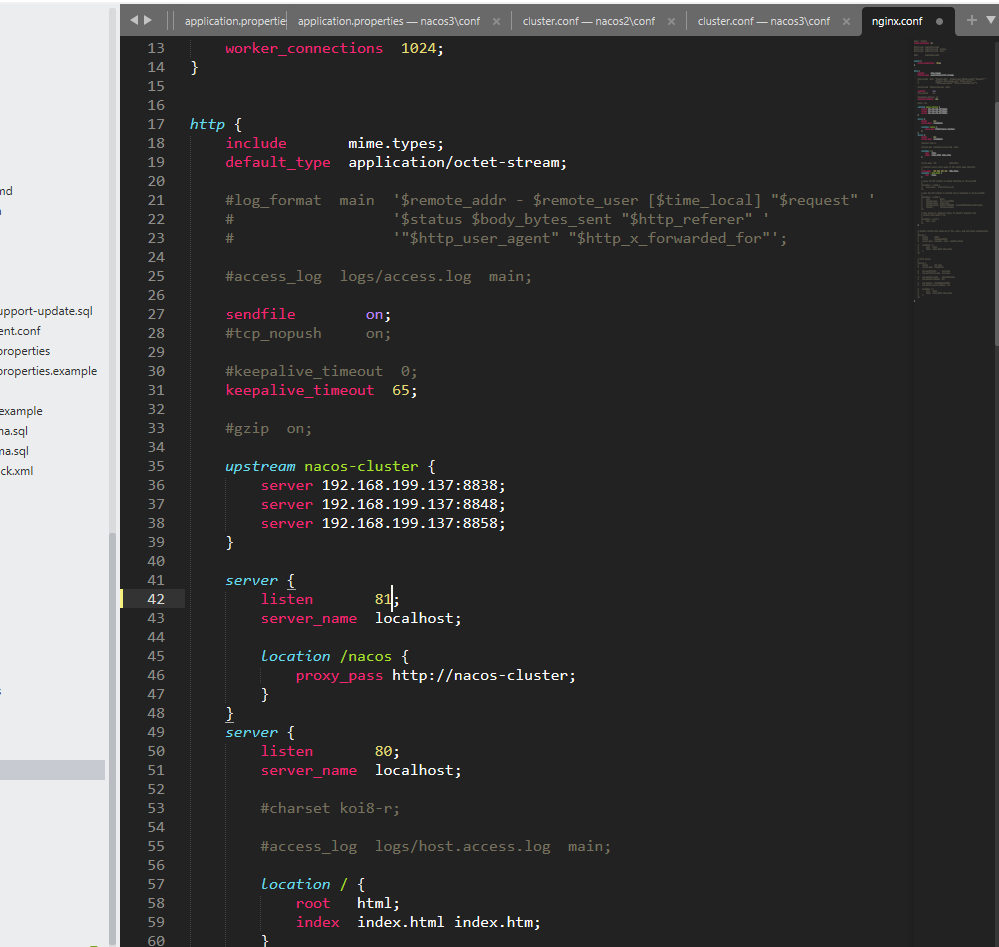 java - 请教下nacos集群,cloud项目无法注册是怎么回事啊?
java - 请教下nacos集群,cloud项目无法注册是怎么回事啊?nacos是2.2.3 2023-08-27 09:52:23.153 ERROR 6492 --- [ main] c.a.c.n.registry.NacosServiceRegistry : nacos registry, userp_ppservice register failed...NacosRegistration{nacosDiscoveryProperties=NacosDis
-
java - 服务器集群下根据年月日生成唯一编号重复?
开发环境 springboot + mybatis-plus 实现类伪代码如下 调用类伪代码如下 代码基本就上面那些,在本地单机环境下没出现过 序列字符串 重复的问题;在集群环境下时而出现,按照我的理解来说,在创建时已经使用redisson锁住了,应该是不会出现数据脏读的问题,这样应该是不会重复的。求各位大佬帮忙解答一下,十分感谢。
-
在懂你英语30天的社群中,现在需要通过用户运营和社群运营实现用户续费,请说一下你的具体执行方案。
本文向大家介绍在懂你英语30天的社群中,现在需要通过用户运营和社群运营实现用户续费,请说一下你的具体执行方案。相关面试题,主要包含被问及在懂你英语30天的社群中,现在需要通过用户运营和社群运营实现用户续费,请说一下你的具体执行方案。时的应答技巧和注意事项,需要的朋友参考一下 用户运营: 1.定期针对性地对用户进行消息推送 2.营造人格化、人性化的学习氛围,给用户学习时的关怀 3.和用户进行学习上的