《烽火通信》专题
-
通知
<section class="ui-notice"> <i></i> <p>请检查网络</p> <div class="ui-notice-btn"> <button class="ui-btn-primary ui-btn-lg">按钮</button> </div> </section>
-
通知
通知类型: 类型 描述 at At 我的 comment 评论我的 like 喜欢我的 system 系统通知 follow 用户粉丝 获取通知统计 GET /api/v2/user/notification-statistics 1 响应: Status: 200 OK { "at": { "badge": 4, "last_created_at": "2019-02-2
-
通知
您可以在智能手表和手机上接收应用程式发给 M600 的通知。如果您已经允许 M600 显示通知,则通知会出现在主屏幕上。查看Notification settings (通知设定)获取更多信息。 如果您已经在智能手表上将通知标记为未读,就可以在 M600 的主屏幕上看到这一状态图标。 图标上的数字显示新通知的数量。 如需查看通知 从屏幕底部向上滑动或将手腕往外摆动。 轻触通知查看其包含的所有信息。
-
通知
支付结果通知 在用户成功支付后,微信服务器会向该 订单中设置的回调URL 发起一个 POST 请求,请求的内容为一个 XML。里面包含了所有的详细信息,具体请参考:支付结果通知 而对于用户的退款操作,在退款成功之后也会有一个异步回调通知。 本 SDK 内预置了相关方法,以方便开发者处理这些通知,具体用法如下: 只需要在控制器中使用 handlePaidNotify() 方法,在其中对自己的业务进行
-
通用
类属性 $state state值,调用getAuthUrl方法后可以获取到 $scope 授权权限列表 $result 接口调用结果 $accessToken AccessToken,调用相应方法后可以获取到 $openid openid,调用相应方法后可以获取到
-
通知
读取通知信息 调用地址 http://api.bilibili.cn/notify 需要 App Key 并验证登录状态(Access key) 返回 返回值字段 字段类型 字段说明 num int 总通知数目 pages int 返回的记录总页数 result array 返回数据 返回字段 “result” 子项 返回值字段 字段类型 字段说明 nf_id int 通知ID type stri
-
通告
一旦项目可以展示了—不必完美,只要能看—就可以将其通知给世界了。这是一个非常简单的过程:来到http://freshmeat.net/,在顶端的导航栏点Submit,然后输入你的新项目的通告。Freshmeat是一个大家关注新项目通告的地方。你只需要在那里用项目新闻抓住一些眼球,就会众口相传。 如果你知道某个邮件列表或新闻组会对你的项目合题或感兴趣,那么请在那里通告,但请注意,一个论坛只有一个通告
-
通知
创建OS(操作系统)桌面通知 进程:主进程 在渲染进程中使用 如果要显示来自渲染进程的通知, 你应该使用 HTML5 Notification API 类: Notification 创建OS(操作系统)桌面通知 进程:主进程 Notification是一个EventEmitter. 通过 options 来设置的一个新的原生 Notification。 静态方法 Notification 类有以
-
一个火车站所需的最少站台数量
问题内容: 您将获得到达特定车站的列车的到达和出发时间。您需要找到在任何时间点容纳火车所需的最少站台数量。 例如: 请注意,抵达时间按时间顺序排列。 问题答案: 解决方案1: 您可以迭代所有间隔并检查有多少其他间隔与其重叠,但这将需要 o(N^2) 时间复杂度。 解决方案2: 我们将使用与归并排序非常相似的逻辑。 对到达(arr)和离开(dep)数组进行排序。 比较到达和离开数组中的当前元素并在两
-
火花的Log4j2。log4j默认属性文件在哪里?
我在哪里可以找到默认的log4j配置文件的工人和驱动程序? 1) 目前Spark正在将执行器/工作者(stdout/stderr)级别的日志记录到工作文件夹,并将驱动程序级别的日志记录到日志文件夹。 我在哪里可以找到这个配置? 我尝试将Log4j2用于spark,而不是log4j。我正在尝试获取默认属性文件,以便可以将其中的一些内容复制到log4j2属性XML。 2) 另外,是否可以修改当前正在运
-
使用代理防火墙生成docker映像错误
你好,我一直在尝试构建镜像,但我在代理防火墙后面,每次我使用docker构建构建。我得到:= 我已经尝试将我的代理地址添加到 docker 代理设置中,在构建命令上尝试了 --build-arg HTTP_PROXY=,并且还尝试在我的 FROM 命令之后立即在我的 docker 文件中设置 ENV htp_proxy=,但是问题仍然存在,我无法找到任何其他解决方案。我的 dockerfile 有
-
火花连接器负载与sstableloader性能的关系
我现在有一个spark工作,它从HDFS中提取数据,并将数据转换为平面文件,以加载到Cassandra中。
-
如何运行火花壳与纱在客户模式?
我已经在一个15节点的Hadoop集群上安装了。所有节点都运行和最新版本的Hadoop。Hadoop集群本身是功能性的,例如,YARN可以成功地运行各种MapReduce作业。 我可以使用以下命令在节点上本地运行Spark Shell,而不会出现任何问题:。 你知道为什么我不能用客户端模式在纱线上运行Spark Shell吗?
-
在CDH 5.4中将火花连接在纱线簇上
-
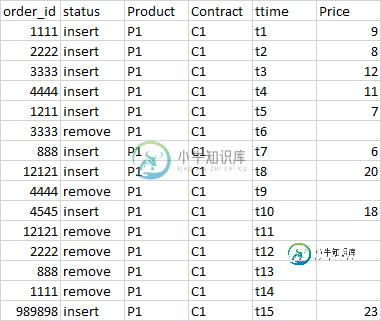 时间序列/刻度数据集的火花转换
时间序列/刻度数据集的火花转换我们在蜂巢中有一个表,它将每天结束时的交易订单数据存储为order_date。其他重要的列是产品、合同、价格(订单价格)、ttime(交易时间)状态(插入、更新或删除)价格(订单价格) 我们必须以滴答数据的方式从主表中构建一个图表表,其中包含从市场开盘到开盘的上午每行(订单)的最大和最小价格订单。i、 e对于给定的订单,我们将有4列填充为maxPrice(到目前为止的最高价格)、maxpriceO