《烽火通信》专题
-
如何在Apache火花爆炸JSON数组[重复]
给定一个spark 2.3数据帧,其中一列包含JSON数组,如何将其转换为JSON字符串的spark数组?或者,等效地,我如何分解JSON,以便输入: 我得到: 非常感谢! p、 数组中条目的形状是可变的。 下面是一个示例输入,如果它是有用的: p. p. s.这不同于迄今为止所有建议的重复问题。例如,如何使用火花数据帧查询JSON数据列?的问题和解决方案适用于(1)数据是所有JSON数据,因此整
-
火花:阿夫罗与镶木地板的表现
现在Spark 2.4已经内置了对Avro格式的支持,我正在考虑将数据湖中某些数据集的格式从Parquet更改为Avro,这些数据集通常是针对整行而不是特定列聚合进行查询/联接的。 然而,数据之上的大部分工作都是通过Spark完成的,据我所知,Spark的内存缓存和计算是在列格式的数据上完成的。在这方面,Parquet是否提供了性能提升,而Avro是否会招致某种数据“转换”损失?在这方面,我还需要
-
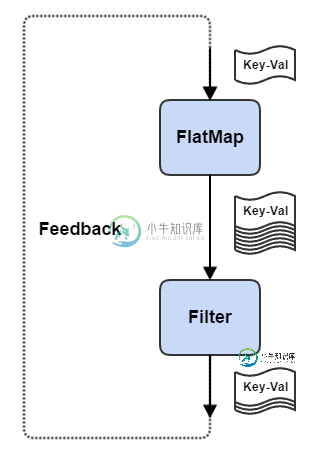 火花流:如何将输出反馈到输入
火花流:如何将输出反馈到输入更新:为了迭代支持,我不得不转向Flink流。不过还是会和Kafka试试看!
-
合并为真的火力恢复文档更新
今天在使用Admin SDK开发Cloud Firestore时,我无意中忘记了替换。使用更新。设置了merge true选项,令我惊讶的是,查询成功了,文档也创建了。我删除了合并:true,然后我得到了文档不存在错误。我用merge:true再次测试了它,并再次创建了文档。我在文档中找不到有关此的任何内容。有人能解释这种行为吗。
-
打开CentOS 7上的防火墙端口[关闭]
那么如何打开端口并使其在重启后存活呢?
-
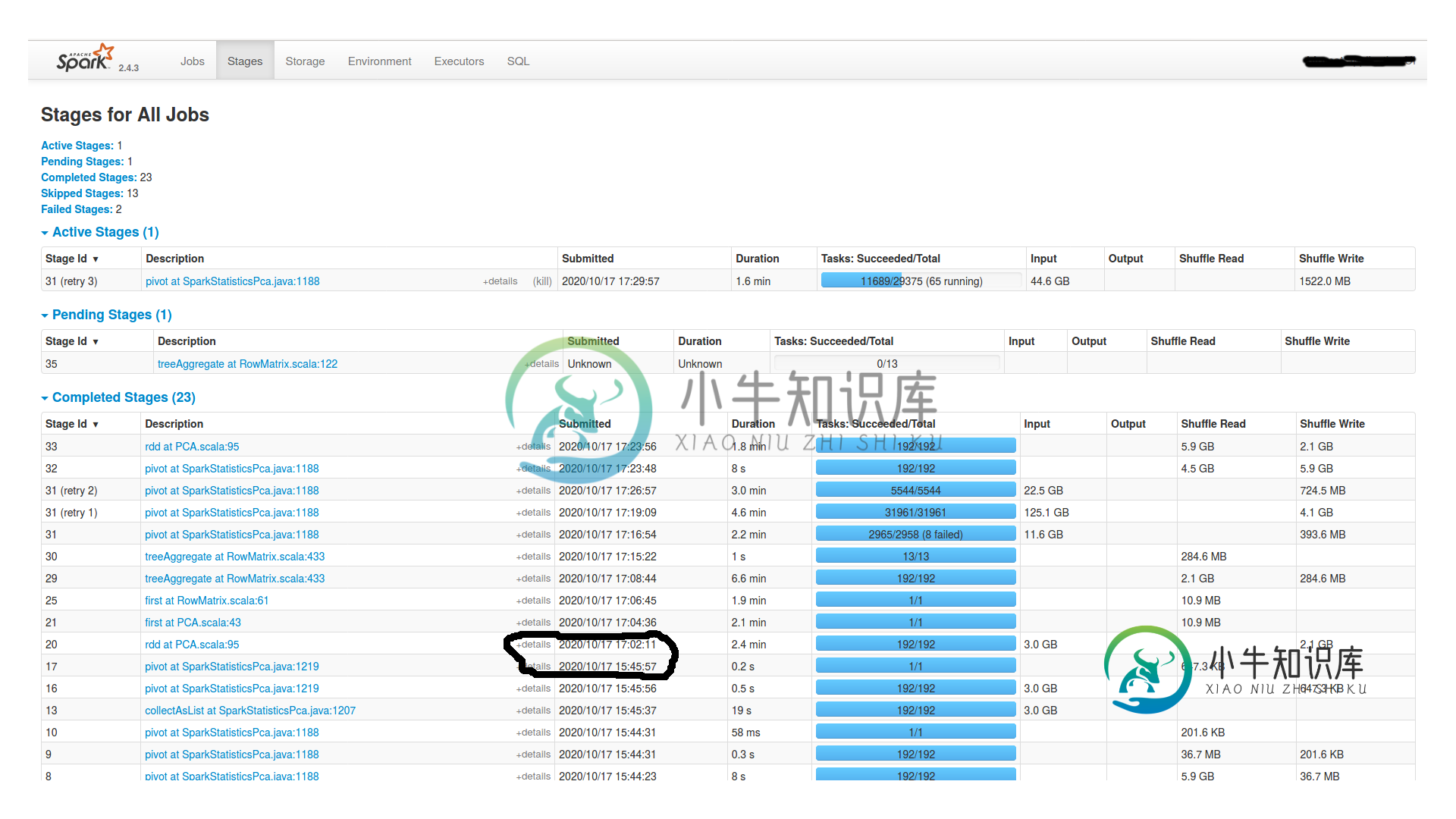 火花工作之间的巨大时间间隔
火花工作之间的巨大时间间隔我创建并持久化一个df1,然后在其上执行以下操作: 我有一个有16个节点的集群(每个节点有1个worker和1个executor,4个内核和24GB Ram)和一个master(有15GB Ram)。Spark.shuffle.Partitions也是192个。它挂了2个小时,什么也没发生。Spark UI中没有任何活动。为什么挂这么久?是dagscheduler吗?我怎么查?如果你需要更多的信息
-
火库认证包升级后的 uid 在哪里?
在以前版本的firebase_auth:^0.5.4中,有一个选项user.uid(uid是字符串类型)。 在firebase_auth的最新版本中:^0.15.0 1,我应该选择哪个选项来获取user.uid或替换它。 有关 FirebaseAuth 0.12.0 中的重大更改的说明。 添加了新的AuthResult和AdditionalUserInfo类 破坏性更改:登录方法现在返回AuthR
-
问题开始为火星控制台包水平
我刚刚将一个旧的OSGi项目迁移到当前的equinox版本(开普勒SR1)。在使用gogo控制台时,我在使用start level 1启动gogo捆绑包时遇到了一个问题(这是我通常对所有相关框架捆绑包所做的)。尽管四个捆绑包都处于活动状态并正在运行,但gogo控制台不会启动。键入help将导致NullPointerException。解决方案是以默认启动级别启动所有gogo捆绑包。我错过了什么吗?
-
火花SASL不使用纱线在emr上工作
首先,我想说的是我看到的解决这个问题的唯一方法是:Spark 1.6.1 SASL。但是,在为spark和yarn认证添加配置时,仍然不起作用。下面是我在Amazon's EMR的一个yarn集群上使用spark-submit对spark的配置: 注意,我用代码将spark.authenticate添加到了sparkContext的hadoop配置中,而不是core-site.xml(我假设我可以
-
如何计算阿帕奇火花的平均值?
我处理了像这样存储的双精度列表: 我想计算这个列表的平均值。根据文档,: MLlib的所有方法都使用Java友好类型,因此您可以像在Scala中一样导入和调用它们。唯一的警告是,这些方法采用Scala RDD对象,而Spark Java API使用单独的JavaRDD类。您可以通过对JavaRDD对象调用.RDD()将JavaRDD转换为Scala RDD。 在同一页面上,我看到以下代码: 根据我
-
如何在火花中打开 TRACE 日志记录
我注意到在 Spark 中的规则探索器每次催化剂更改计划时都会执行跟踪日志: https://github . com/Apache/spark/blob/78801881 c 405 de 47 f 7 e 53 EEA 3 e 0420 DD 69593 DBD/SQL/catalyst/src/main/Scala/org/Apache/spark/SQL/catalyst/rules/ru
-
Python Selenium PhantomJs=没有点击=(但是火狐点击
我有一个问题: 下面是在Firefox中点击网站链接的代码。它工作。点击。但是PhantomJS中的相同代码会进入页面,但不会点击。请帮忙解决问题。先谢了
-
如何在节点上实现模拟退火(TSP)
我知道我需要这样的东西 有人能给我一个这个的示例代码吗?。谢谢
-
火花:HDFS块与集群核心与rdd分区
我对spark有疑问:HDFS块vs集群核心vs rdd分区。 假设我正在尝试在HDFS中处理一个文件(例如块大小为64MB,文件为6400MB)。所以理想情况下它确实有100个分裂。 我的集群总共有 200 个核心,我提交了包含 25 个执行程序的作业,每个执行程序有 4 个核心(意味着可以运行 100 个并行任务)。 简而言之,我在rdd中默认有100个分区,100个内核将运行。 这是一个好方
-
了解火花中的洗牌和重新分区
如果有人能用简单的术语回答这些与火花洗牌相关的问题,我将不胜感激。 在spark中,当加载一个数据集时,我们指定分区的数量,这表示输入数据(RDD)应该被划分为多少个块,并且根据分区的数量启动相等数量的任务(如果假设错误,请纠正我)。对于工作节点中的X个核心数。一次运行相应的X个任务。 沿着类似的思路,这里有几个问题。 因为,所有byKey操作以及联合、重新分区、连接和共组都会导致数据混乱。 >